给 AI 讲故事,如何教它脑补画面?

阿里妹导读:视觉想象力是人与生俱来的, AI 能否拥有类似的能力呢?比如:给出一段故事情节,如何让机器展开它的想象力,“脑补”出画面呢?看看阿里AI Labs 感知实验室的同学们如何解决这个问题。
1. 背景 —— 视觉想象力(Visual Imagination)
1.1 什么是视觉想象力?

1.2 AI拥有视觉想象力后的影响?
图2为一个在语义图像搜索领域中的案例。我们在google中搜索man holding fish and wearing hat on white boat,可能返回的结果质量为(a),引擎只是零星理解了我们的搜索意图。而当机器拥有一定视觉想象力后,它的搜索结果可能是(b),这将极大提升我们的信息检索效率,而这些信息是承载于图像中的。


2. 选题 —— 站在巨人的肩膀上
2.1 领域的痛点在哪?
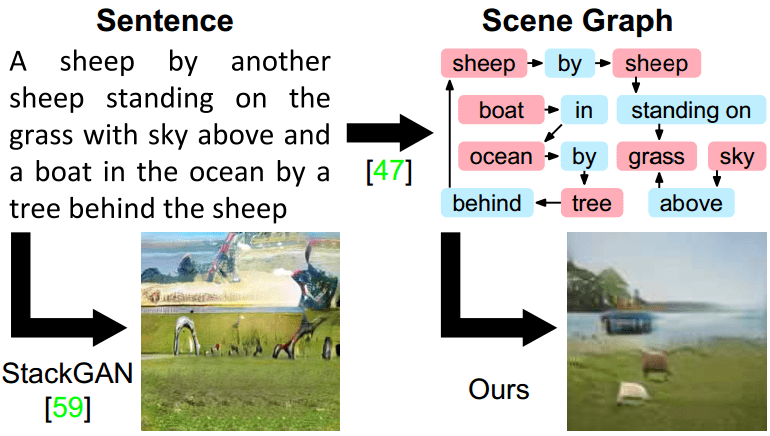
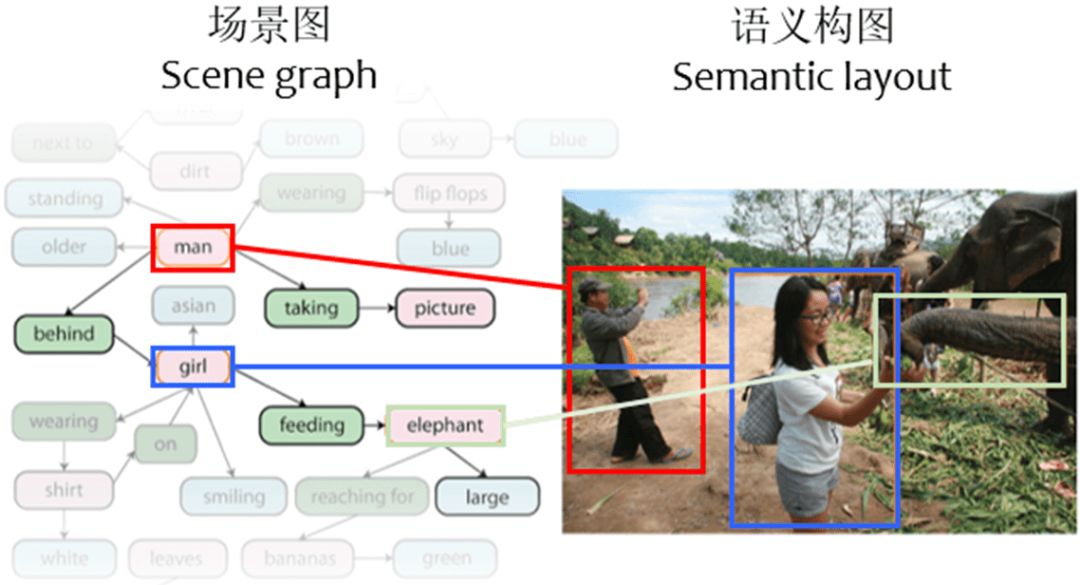
每个场景图中的实体,在图像中会有一个与之对应的bbox。如果不看图像本身,单看图中所有的bbox,就形成了一幅图像的语义构图,因此可以将语义构图看作是一种具有普遍含义的图像结构化表达。

2.2 如何解决?—— 我们眼中的大框架

2.3 论文的关注点
3. 论文的动机及贡献
3.1 当前的问题
★ 3.1.1 最接近的工作与组合爆炸问题
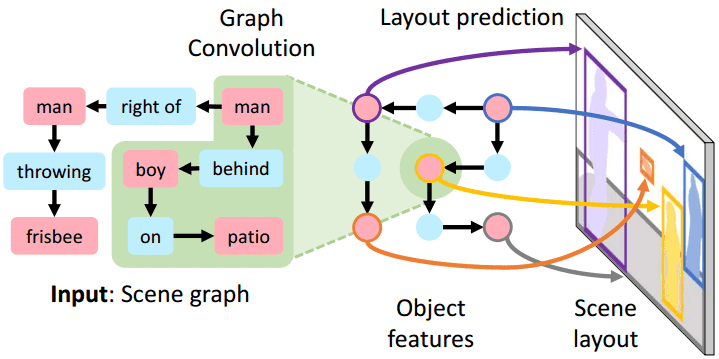
★ 3.1.2 语义构图评价指标的缺失
3.2 Seq-SG2SL的动机

3.3 SLEU的动机
-
1)要想完成自动化评估,必须需要真值。 -
2)SLEU的设计目的就是要度量一个生成的语义构图与真值之间的差异。
3.4 论文的贡献
4. 方法要点简述
4.1 Seq-SG2SL框架
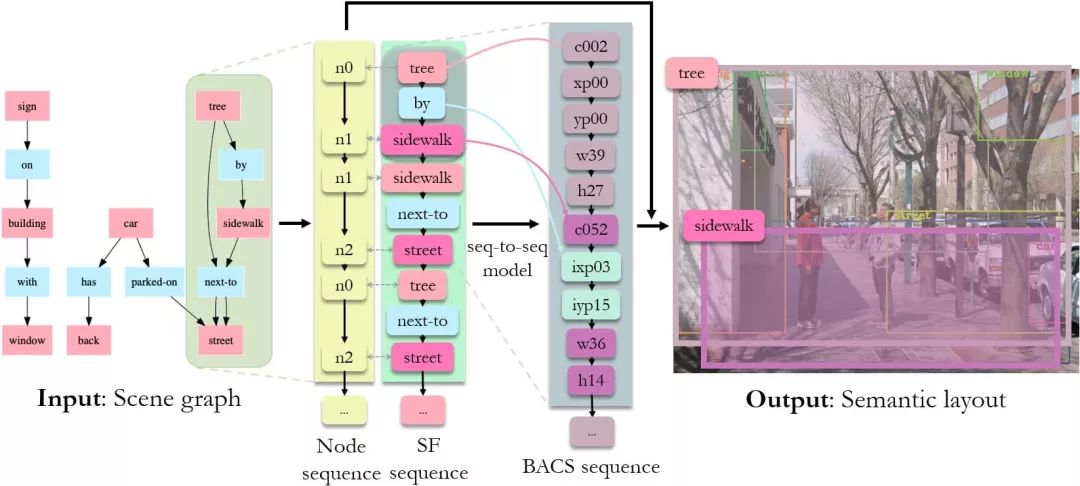
框架的主要思想就讲完了,细节的话感兴趣的读者可以去看论文。
4.2 SLEU指标
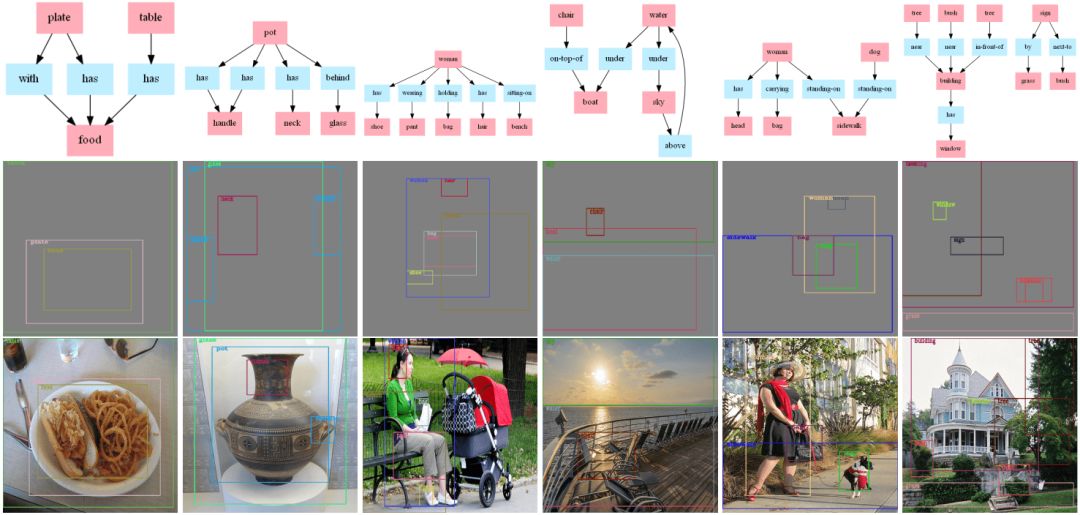
5. 实验结果预览
https://arxiv.org/abs/1908.06592
热门书籍+阿里机器智能创新案例,满足你对机器智能的所有学习需求。识别下方二维码或点击“阅读原文”立刻开始 AI 之路。




支付宝技术双11答卷:没有不可能

从P4到P9, 在马云家写代码到双11前端PM


登录查看更多
相关内容
专知会员服务
16+阅读 · 2020年4月8日
Arxiv
5+阅读 · 2019年8月27日
Arxiv
9+阅读 · 2018年5月11日
Arxiv
4+阅读 · 2018年5月8日
相关VIP内容
专知会员服务
16+阅读 · 2020年4月8日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年8月27日
Arxiv
9+阅读 · 2018年5月11日
Arxiv
4+阅读 · 2018年5月8日