AI都可以将文字轻松转成图像
夜晚是如此的安静,但是依然有很多挑灯夜战的你、他、她......无论在哪座城市,都会有忙碌的人在灯光下依然勤奋努力的工作,希望分享的这首小曲可以缓解夜间工作的疲惫,更希望眺望远处的朦胧灯火,依然是一个美好的心情!现在的我也是在暖黄色的灯光下书写今天分享的趣文,希望阅读到的朋友可以放下手头工作,小息片刻来欣赏今天的好文~

夜晚没有让你欣赏美女来着,但是这位“女神”如果你看一眼之后,便会有种羡慕的眼神去仰慕,因为她是很多人的偶像,那今天就来说说飞飞姐最新成果,让我们也近距离的接触下“女神科学家”!

上面这个图就是今天主要讲解的高科技,你只要给我一句话,我就能给你一幅图像,并且与你说的话语境相同!我不自觉地为这个新技术点赞,为我们科研人员鼓掌,感谢在AI一线的你们!
Image Generation from Scene Graphs
通过这个题目就能知道今天的主旨。首先打个比喻:
大家最近总是在看dou🎵,里面经常会出现一种场景,就是“来帮我修个图,这颜色亮一点,这改小一点......”,对于设计师,心里的阴影是多么沉重。
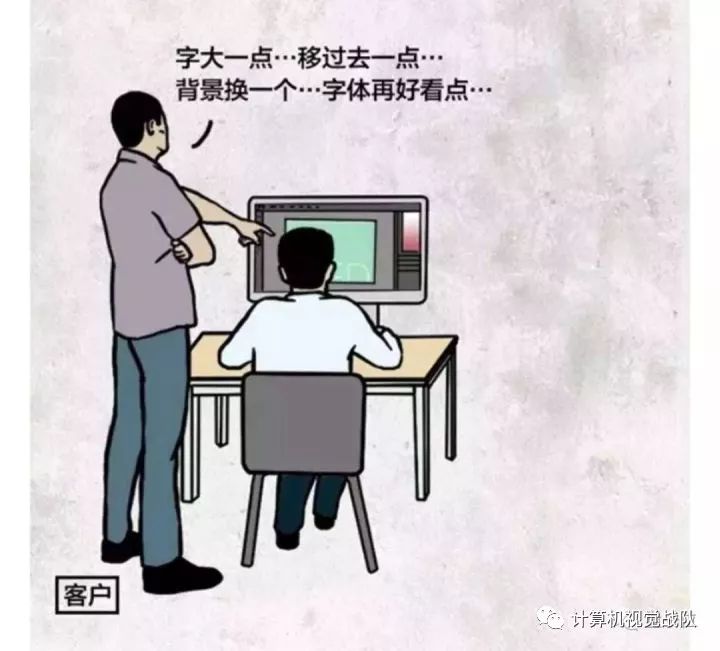
就好比上图的场景,如果有这么一个机器,我给他一些需求,它自动按照指令进行修改,那多好啊!现在这个期望可以实现了,下面就让我们好好了解下是怎么做到的!
早在之前,就有出现StackGAN,他利用语义信息可以简单实现的绘图,但是对于句子中若有多个目标物体或者位置多样化,关系复杂,那生成的图像根本无法表达出原有的意思,画出来的图像也不能看。
为解决这类问题,“女神”——李飞飞终于站出来,带着自己团队提出一个关键性的想法:不如先把句子的文本先处理,比如把句子中的物体和位置用一个物体关系图(Scene Graph)表示出来,然后再设计一个模型,去进行处理,把所得到的语义信息表现出来。
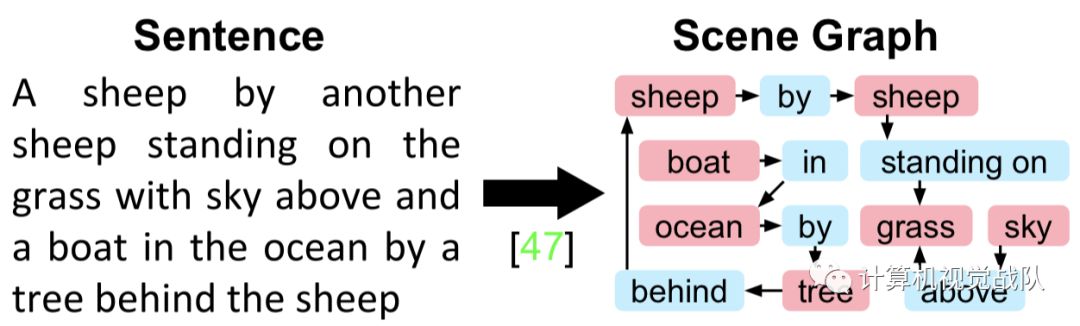
没有比较没有伤害,看下面的比较图,你会发现这样的思想确实很不错:

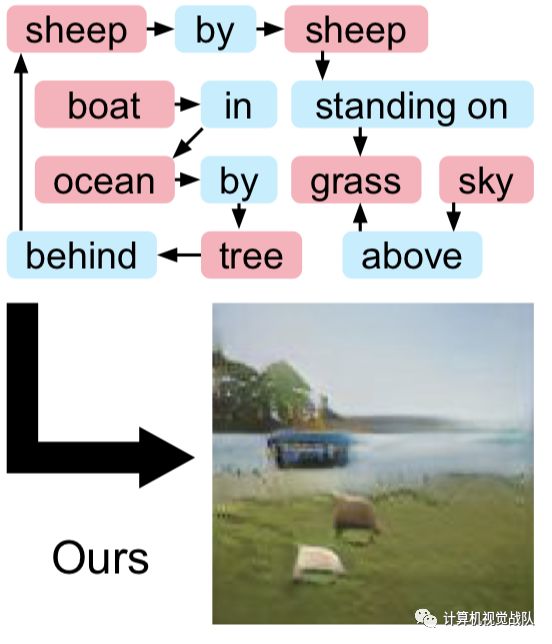
加一步,多面临三重挑战
通过增加的一个步骤,可能会遇到更多的挑战。为了生成更符合物理世界规律的图像,生成过程中所用到素材必须取自真实世界的图像。
第一个挑战就是要构建一个能处理真实图像的输入处理器;
生成的每一个物体都必须看起来真实,而且能正确反映出多个物体的空间透视关系;
整个图中所有物体整合到一起,得是看起来是自然和谐不别扭的。
通过上面的图,可以看出下面那个图就是李飞飞团队做出来的效果,比较一下,就会发现差距确实很大。下面我们就简要的说说具体的实现。
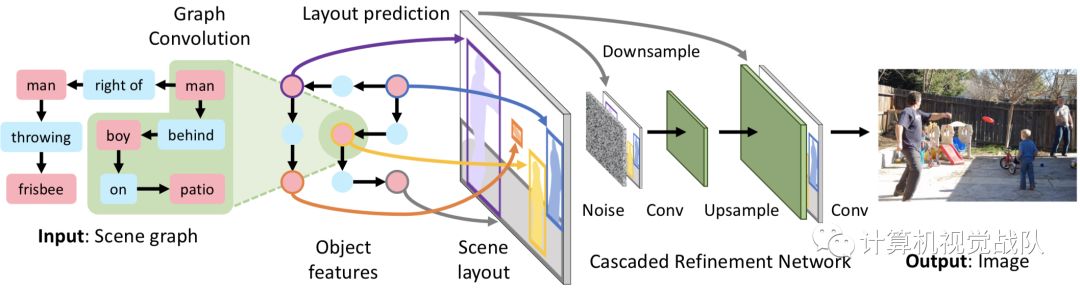
现有的根据自然语言生成图像的方法,难以生成语言描述中包含多个物体和之间关系的图。于是,作者提出了一个图像生成网络模型,该模型用图卷积处理输入场景图,根据bounding box等计算场景布局,然后把布局用级联细化网络转换成图像。这个网络是针对一对鉴别模型进行训练的,Dimg和Dobj分别用来鉴别真实图像和真实对象,来确保输出的图像真实自然。
模型
在讲模型之前,先给大家说下生成对抗网络(GAN)的概念:
GAN框架,最少(但不限于)拥有2个组成部分,一个是生成模型G,一个是判别模型D。在训练过程中,会把生成模型生成的样本和真实样本随机地传送一张给判别模型D。判别模型D的目标是尽可能正确地识别出真实样本(输出为“真”,或者“1”),和尽可能正确地揪出生成的样本,也就是假样本(输出为“假”,或者“0”);而生成模型的目标则和判别模型相反,就是尽可能最小化判别模型揪出它的概率。这样G和D就组成了一个min-max game,在训练过程中双方都不断优化自己,直到达到平衡——双方都无法变得更好,也就是假样本与真样本完全不可区分。
本次技术基于两个模型训练:
一、图像生成模型
可以先将图片人工给出关系,如下:
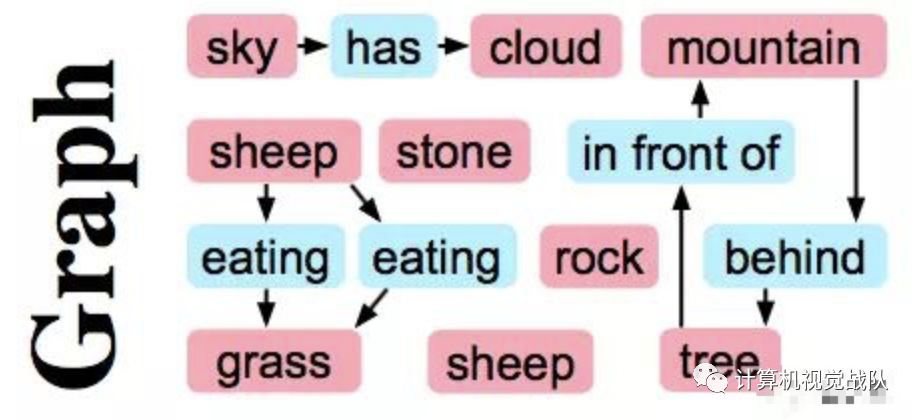
然后用模型预测物体之间的位置,大概给出一个图片元素的布局,如下:
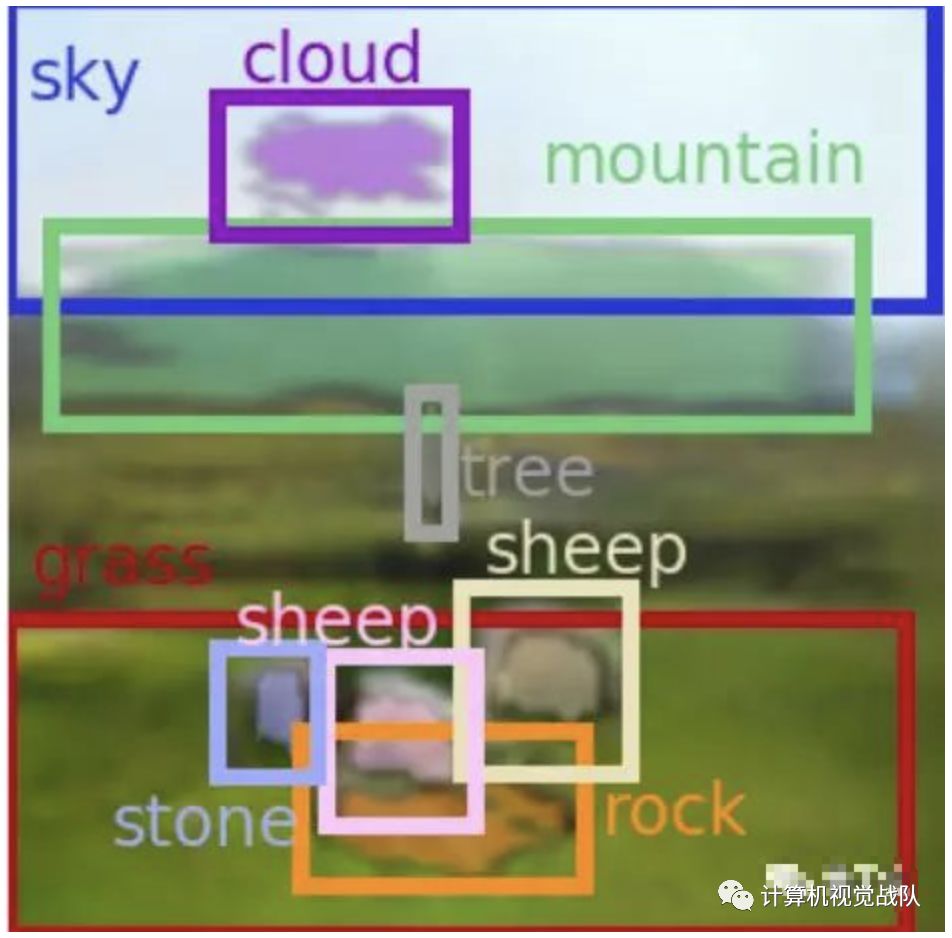
最后根据多个判别模型保证输出的图像是符合真实感知的。
模型的输入是描述对象和之间关系的场景图,场景图被Graph Convolution network [1]处理,图卷积网络沿着场景图的边计算所有对象的嵌入向量。这些向量被传入到Object Layout Network[2]中用于预测对象的bounding boxes和Segmentation masks,将向量的边界框和掩膜结合就能得到对象的布局,将所有对象布局结合就能形成scene layout。然后用一个级联细化网络Cascaded Refinement Network(CRN)[3]将布局转换为生成图像。这个模型是针对一对鉴别器网络进行对抗训练的,训练的时候模型观察真实的对象边界框和分段掩膜,测试的时候这些用的是预测的值。
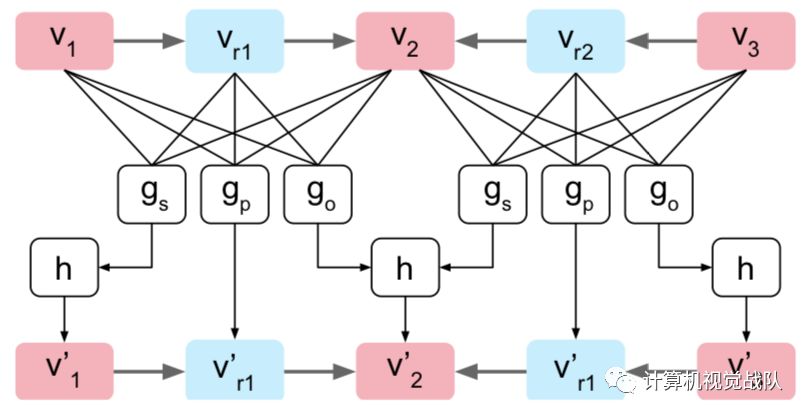
Graph Convolution network:图卷积网络是由多个图卷积层构成的,单个图卷积层如下所示。
Object Layout Network:由两部分组成,Mask regression network和Box regression network。
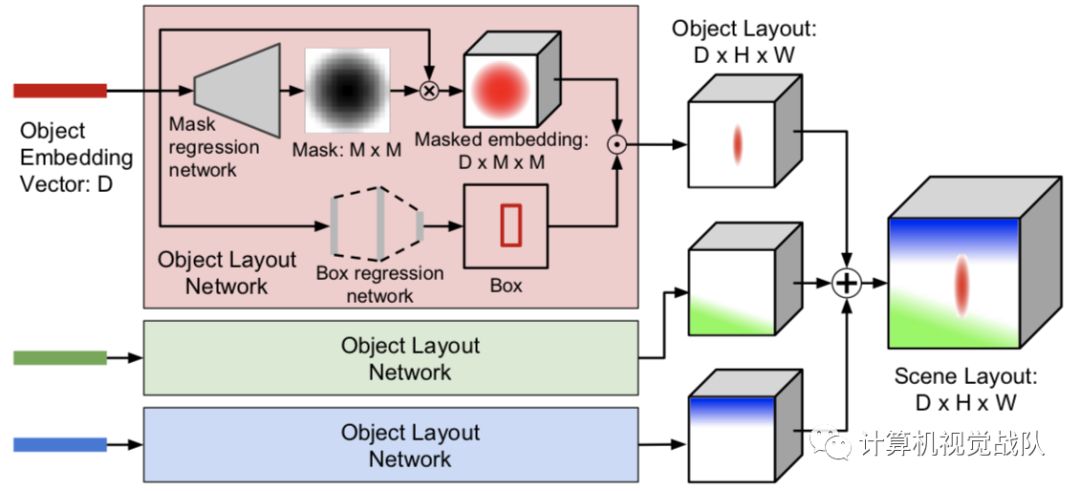
Cascaded Refinement Network(CRN):级联微调网络。
级联微调网络由一系列的卷积细化模块构成,每个模块之间是2倍空间分辨率的关系,这就允许以一种由粗到精的方式去生成图片。每个模块接收根据模块输入的分辨率下采样后的场景布局和前一个模块的输出。这些输入串联并传递到卷积层,然后在传递到下一个模块之前对输出进行上采样。
二、一对判别模型Dimg和Dobj
图像判别器Dimg确保生成的图像的整体外观是真实的,它将规则间隔,重叠的图像块集合分类为真实或伪造。
对象判别器Dobj确保图像中的每个对象看起来都是真实的;其输入是一个对象的像素,使用双线性插值法裁剪并重新缩放到固定大小。除了将每个对象分类为真实还是假的,Dobj还确保每个对象都可以使用预测对象类别的辅助分类器来识别; Dobj和f都尝试最大化Dobj正确分类对象的概率。
训练的时候有6个损失:


实验
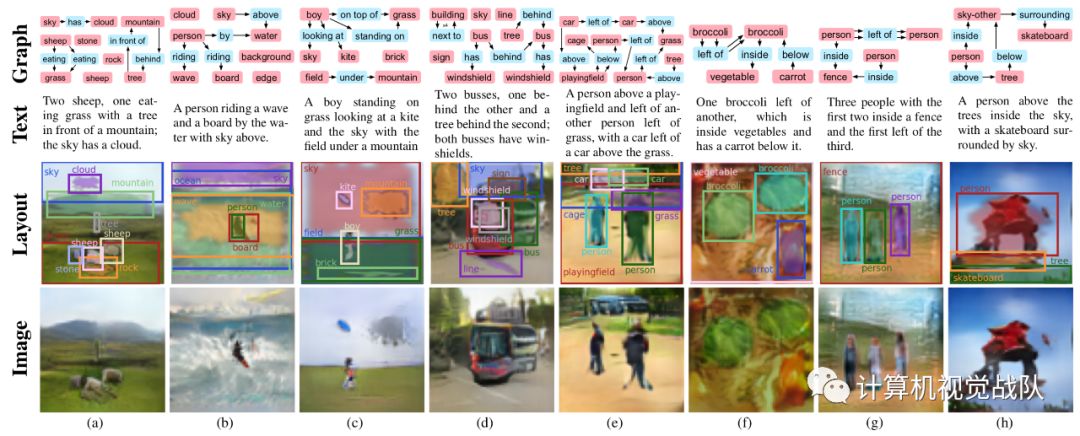

具有生成复杂图像的能力

结果评估
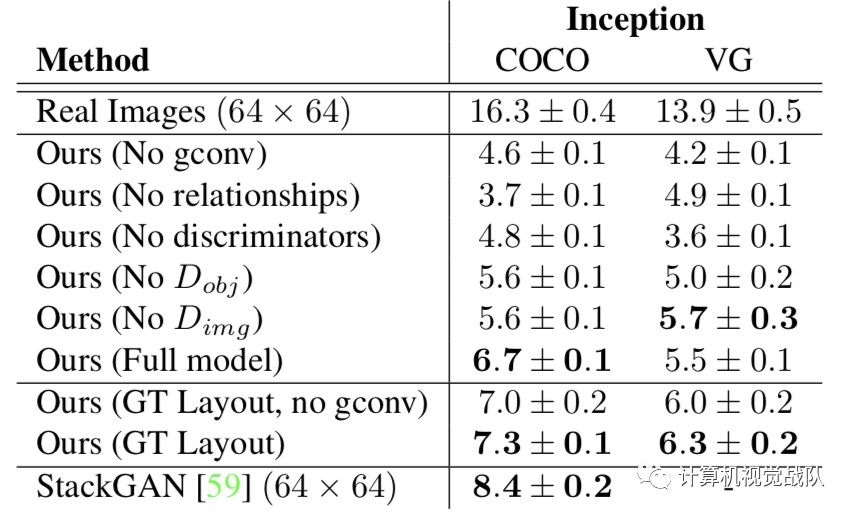
Ablation study using Inception scores
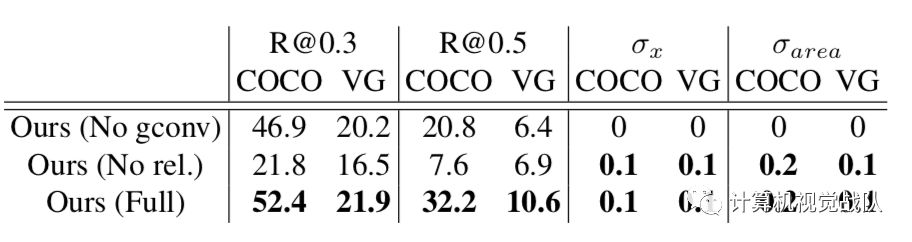
Statistics of predicted bounding boxes
与StackGAN比较

附件实验:

小小总结:
现有的根据自然语言生成图像的方法,难以生成语言描述中包含多个物体和之间关系的图。于是,作者提出了一个图像生成网络模型,该模型用图卷积处理输入场景图,根据bounding box等计算场景布局,然后把布局用级联细化网络转换成图像。这个网络是针对一对鉴别模型进行训练的,Dimg和Dobj分别用来鉴别真实图像和真实对象,来确保输出的图像真实自然。
现有的由文本生成图像的方法主要是结合递归神经网络(RNN)和生成对抗网络(GAN)来实现的。此前出现了很多效果让人惊叹的由文本转图的方法,其中有代表性的为ICCV 2016 2017的StackGAN方法,它在生成花鸟方面的效果确实Amazing,而且能达到256*256的高分辨率。要知道,在这篇文章之前,生成图像的分辨率几乎都局限在64*64。

GAN:实战生成对抗网络
作者:(美)Kuntal Ganguly(昆塔勒.甘古力)



