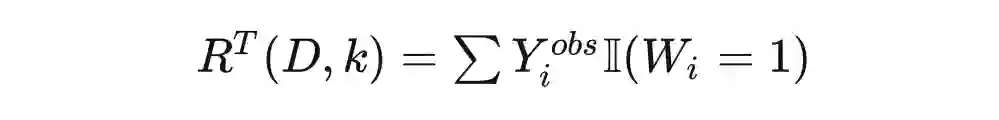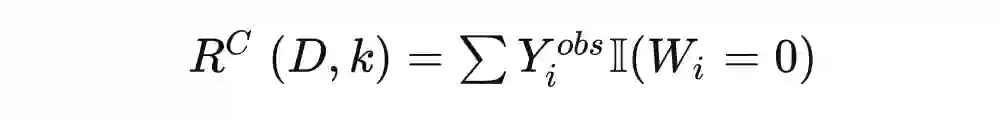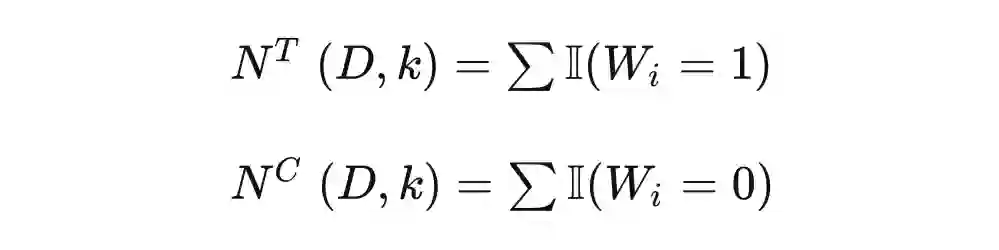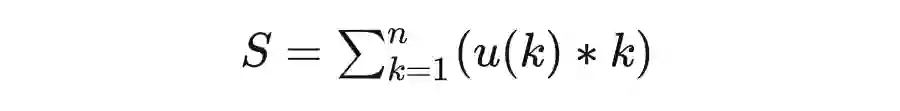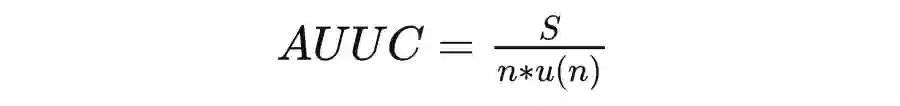在 AUUC 代码中,我们能看到 auuc_score() 函数最终产出了一个随机得分,lift 和 gain 也分别有一条 random 曲线。那么 random 究竟代表着什么呢?它代表了无规律排序下,实验组相对于控制组的期望增值。在大多数情况下,使用归一化的 auuc_score(normalize=True) 函数计算得到的 random 值应该接近 0.5,gain.plot() 画出的 random 应该是一条直线。原因是在多次随机排序下,期望增值应该是稳步上升的。
假如 random 值不是 0.5,图像不是直线时,这意味着什么?
导致不是 0.5 的背后原因可能有很多,可以先分析下是不是以下三种情况。1.实验组和空白组不是平衡的,两者人群不是同质的,这时算 AUUC 没有很大的意义了,应该调平人群后再计算。2.样本的 y 值即响应信号的离群点比较多。3.样本量太小,无法支撑实验组和对照组的匹配。
除此之外,还有一种情况是 random 值为 -0.5,这时整体的 ATE 为负数,所有样本均为负弹,这时候 uplift 值不再是“收益”,更像是“花销”。
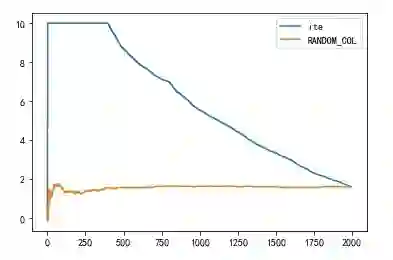
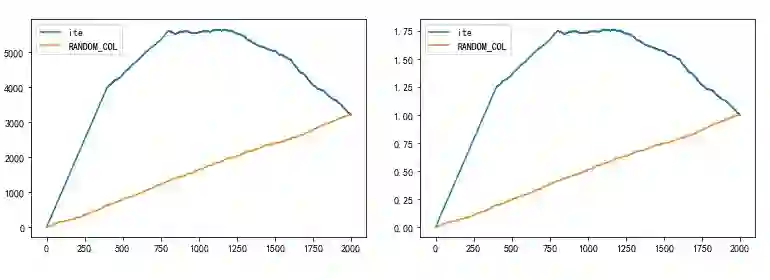
来画个图,观赏下AUUC曲线吧
讲完理论可能还是缺乏真实感,接下来我们造个虚拟数据集画一下 AUUC 曲线。
import numpy as np %matplotlib inline import pandas as pd from EvolveUplift import get_cumlift_change import matplotlib.pyplot as plt y_c = np.array(1000*[0]) y_t = y_c.copy() u = np.array(200*[10]+200*[4]+200*[0]+200*[-2]+200*[-4]) for i in [0,200,400,600,800]: y_t[i:i+200] = y_c[i:i+200]+u[i] r = [] for i in range(0,1000): r.append(y_t[i]) r.append(y_c[i])
y = np.array(r) u = np.concatenate((np.random.normal(10,0.01,[400]), np.random.normal(8,0.01,[400]), np.random.normal(6,0.01,[400]), np.random.normal(4,0.01,[400]), np.random.normal(2,0.01,[400])),axis=0) metric_dfa = pd.DataFrame([u, y, np.array(1000*[1,0])]).T metric_dfa.columns=['ite','y','w'] lift = get_cumlift_change(metric_dfa) lift.plot() gain = lift.mul(lift.index.values, axis=0) gain.plot() print(gain.sum() / gain.shape[0]) print("------------------------") gain = gain.div(np.abs(gain.iloc[-1, :])) gain.plot() print(gain.sum() / gain.shape[0])