开发 | 干货满满,阿里天池CIKM2017 Rank4比赛经验分享
AI科技评论按:由深圳气象局与阿里巴巴联合承办的CIKM AnalytiCup 2017第一赛季已经宣告结束。本次比赛的目标是利用雷达数据(多普勒雷达回波外推数据),来建立一个准确的降水预报模型。
这次比赛吸引了1395支队伍参赛,排行榜也已在阿里天池平台进行公示。
在这次比赛中,来自中国科学院的怀北村明远湖队(队员Zhang Rui, Qiao Fengchun, Guo Ran)在GitHub上分享了自己的代码和方法,他们在第一阶段获得第三名,第二阶段获得第四名。AI科技评论将他们发布的内容进行了整理,如下:
背景介绍
在这次比赛中,主办方提供了一组不同时间跨度(间隔为6分钟,共15个时间跨度)和不同高度下(0.5km、1.5km、2.5km、3.5km)测量的雷达图,每个雷达图都包含目标站点和目标站点周围区域的雷达反射率值。每个雷达图覆盖以目标站点为中心,面积为101 * 101平方公里的区域。该区域被标记为101×101格,目标站点位于中心,即(50,50)。
数据集中包含真实的雷达图和气象观测中心收集到的目标站点降水量。
比赛的任务是预测在未来1-2个小时内每个目标站点的总降雨量。
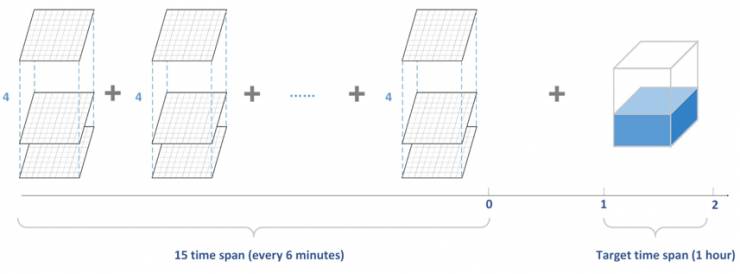
数据处理过程
Percentil Method百分位数法
他们采用统计的方法来降低雷达数据的维度。对于每个雷达图,他们对目标站附近到整个地图范围内不同大小的区域都选取了雷达反射率值的25、50、75、100百分位。
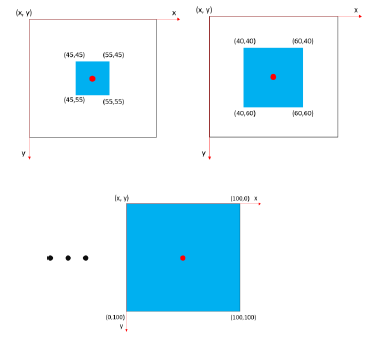
图:以目标站点为中心选取不同的区域
Wind法
他们首先将原始数据(15*4*101*101)压缩成稍小的数据(15*4*10*10),然后通过判断风向,将数据压缩到15*4*6*6个特征。整个预处理过程都是利用卷积神经网络的方法,特别是卷积运算和最大池化。
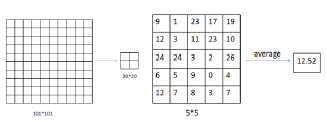
图:卷积计算表征
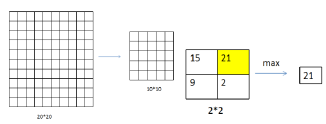
图:池化计算表征
他们利用第四层的数据来判断风向。然后,为了计算最终风向,用两种方法来选择有代表性的数据。第一种方法在每10*10单元中使用最大的值作为表征,第二种方法则采用最大的5个数据的平均值作为表征。
在选出有代表性的数据之后,通过每两个时间间隔之间数据的偏差值算出移动方向,最终基于给定的阈值统计不同移动方向的数目,按照数目最多移动方向的确定最终风向。
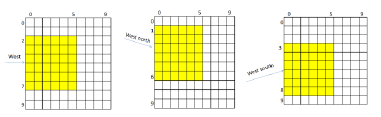
图:当风向为西、西北、西南时提取特征的方法
模型
在这次任务中,他们的模型结合了Random Forestry、XGBoost和双向GRU单元(Bidirectional Gated Recurrent Unit)等,得出了较为满意的结果。
运用的工具
Python 3.6
Keras
XGBoost
Sklearn
代码地址
https://github.com/zxth93/CIKM_AnalytiCup_2017
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————




