即插即用!Triplet注意力机制让Channel和Spatial交互更加丰富
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI人工智能初学者

-
论文下载地址和代码开源地址:https://github.com/LandskapeAI/triplet-attention
https://arxiv.org/abs/2010.03045
在本文中研究了轻量且有效的注意力机制,并提出了Triplet Attention,该注意力机制是一种通过使用Triplet Branch结构捕获跨维度交互来计算注意力权重的新方法。对于输入张量,Triplet Attention通过旋转操作和残差变换建立维度间的依存关系,并以可忽略的计算开销对通道和空间信息进行编码。该方法既简单又有效,并且可以轻松地插入经典Backbone中。
1、简介和相关方法
最近许多工作提出使用Channel Attention或Spatial Attention,或两者结合起来提高神经网络的性能。这些Attention机制通过建立Channel之间的依赖关系或加权空间注意Mask有能力改善由标准CNN生成的特征表示。学习注意力权重背后是让网络有能力学习关注哪里,并进一步关注目标对象。这里列举一些具有代表的工作:
1、SENet(Squeeze and Excite module)
2、CBAM(Convolutional Block Attention Module)
3、BAM(Bottleneck Attention Module)
4、Grad-CAM
5、Grad-CAM++
6、
-Nets(Double Attention Networks)
7、NL(Non-Local blocks)
8、GSoP-Net(Global Second order Pooling Networks)
9、GC-Net(Global Context Networks)
10、CC-Net(Criss-Cross Networks)
11、SPNet
等等方法(这些方法都值得大家去学习和调研,说不定会给你的项目带来意想不到的效果)。
以上大多数方法都有明显的缺点(Cross-dimension),Triplet Attention解决了这些缺点。Triplet Attention模块旨在捕捉Cross-dimension交互,从而能够在一个合理的计算开销内(与上述方法相比可以忽略不计)提供显著的性能收益。
2、本文方法
2.1、分析
本文的目标是研究如何在不涉及任何维数降低的情况下建立廉价但有效的通道注意力模型。Triplet Attention不像CBAM和SENet需要一定数量的可学习参数来建立通道间的依赖关系,本文提出了一个几乎无参数的注意机制来建模通道注意和空间注意,即Triplet Attention。
2.2、Triplet Attention
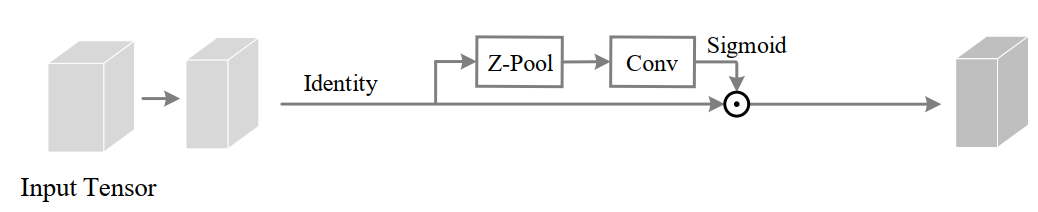
所提出的Triplet Attention见下图所示。顾名思义,Triplet Attention由3个平行的Branch组成,其中两个负责捕获通道C和空间H或W之间的跨维交互。最后一个Branch类似于CBAM,用于构建Spatial Attention。最终3个Branch的输出使用平均进行聚合。
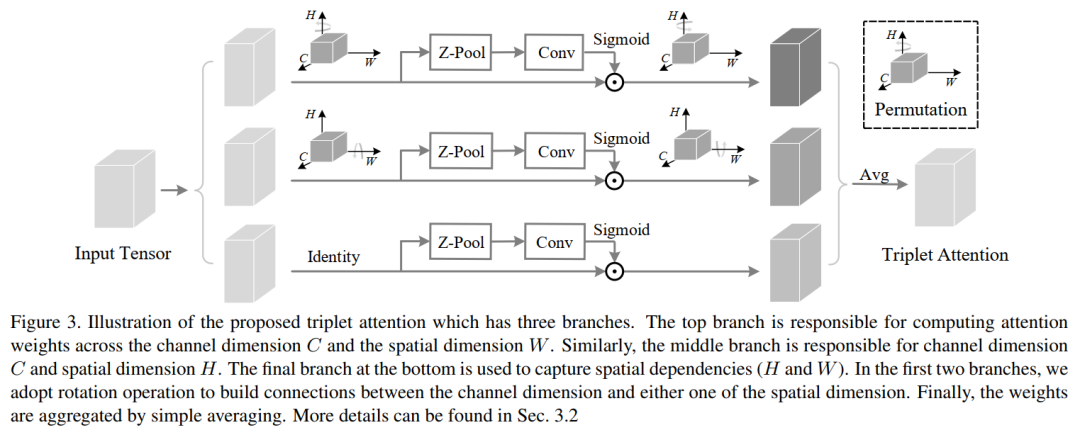
1、Cross-Dimension Interaction
传统的计算通道注意力的方法涉及计算一个权值,然后使用权值统一缩放这些特征图。但是在考虑这种方法时,有一个重要的缺失。通常,为了计算这些通道的权值,输入张量在空间上通过全局平均池化分解为一个像素。这导致了空间信息的大量丢失,因此在单像素通道上计算注意力时,通道维数和空间维数之间的相互依赖性也不存在。
虽然后期提出基于Spatial和Channel的CBAM模型缓解了空间相互依赖的问题,但是依然存在一个问题,即,通道注意和空间注意是分离的,计算是相互独立的。基于建立空间注意力的方法,本文提出了跨维度交互作用(cross dimension interaction)的概念,通过捕捉空间维度和输入张量通道维度之间的交互作用,解决了这一问题。
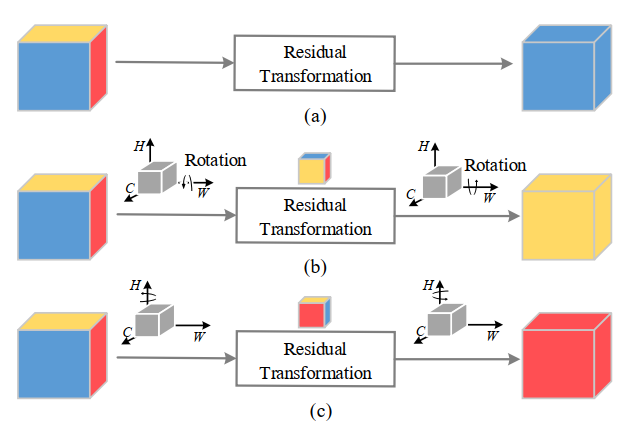
这里是通过三个分支分别捕捉输入张量的(C, H),(C, W)和(H, W)维间的依赖关系来引入Triplet Attention中的跨维交互作用。
2、Z-pool
Z-pool层负责将C维度的Tensor缩减到2维,将该维上的平均汇集特征和最大汇集特征连接起来。这使得该层能够保留实际张量的丰富表示,同时缩小其深度以使进一步的计算量更轻。可以用下式表示:

class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=11)
3、Triplet Attention
给定一个输入张量 ,首先将其传递到Triplet Attention模块中的三个分支中。
在第1个分支中,在H维度和C维度之间建立了交互:
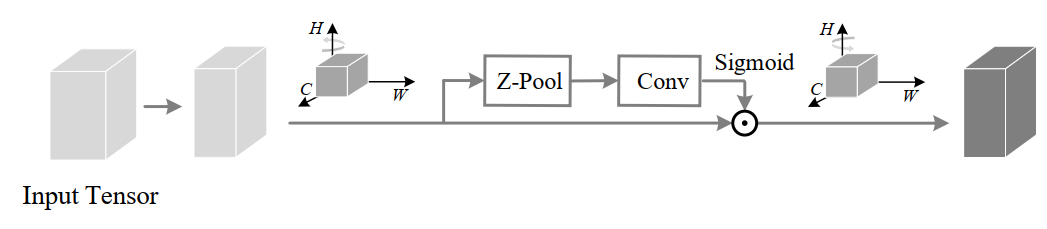
为了实现这一点,输入张量 沿H轴逆时针旋转90°。这个旋转张量表示为 的形状为(W×H×C),再然后经过Z-Pool后的张量 的shape为(2×H×C),然后, 通过内核大小为k×k的标准卷积层,再通过批处理归一化层,提供维数(1×H×C)的中间输出。然后,通过将张量通过sigmoid来生成的注意力权值。在最后输出是沿着H轴进行顺时针旋转90°保持和输入的shape一致。
在第2个分支中,在C维度和W维度之间建立了交互:
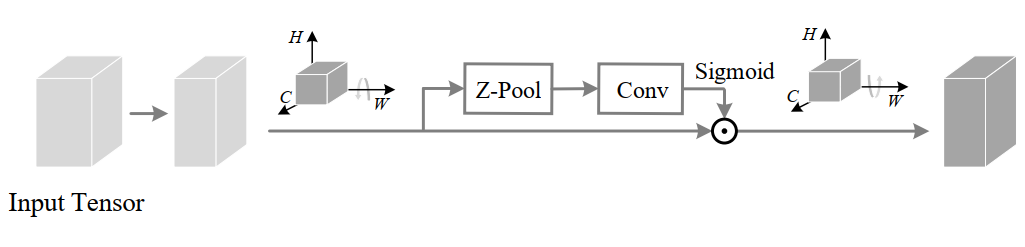
为了实现这一点,输入张量 沿W轴逆时针旋转90°。这个旋转张量表示为 的形状为(H×C×W),再然后经过Z-Pool后的张量 的shape为(2×C×W ),然后, 通过内核大小为k×k的标准卷积层,再通过批处理归一化层,提供维数(1×C×W)的中间输出。然后,通过将张量通过sigmoid来生成的注意力权值。在最后输出是沿着W轴进行顺时针旋转90°保持和输入的shape一致。
在第3个分支中,在H维度和W维度之间建立了交互:
**最终输出的Tensor:
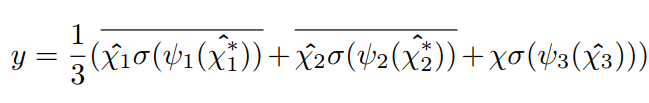
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(TripletAttention, self).__init__()
self.ChannelGateH = SpatialGate()
self.ChannelGateW = SpatialGate()
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.ChannelGateH(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.ChannelGateW(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.SpatialGate(x)
x_out = (1/3)*(x_out + x_out11 + x_out21)
else:
x_out = (1/2)*(x_out11 + x_out21)
return x_out
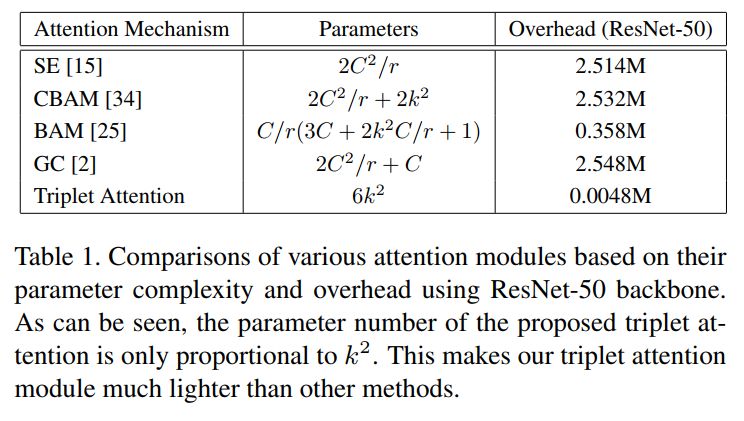
4、Complexity Analysis
通过与其他标准注意力机制的比较,验证了Triplet Attention的效率,C为该层的输入通道数,r为MLP在计算通道注意力时瓶颈处使用的缩减比,用于2D卷积的核大小用k表示,k<<<C。
3、实验结果
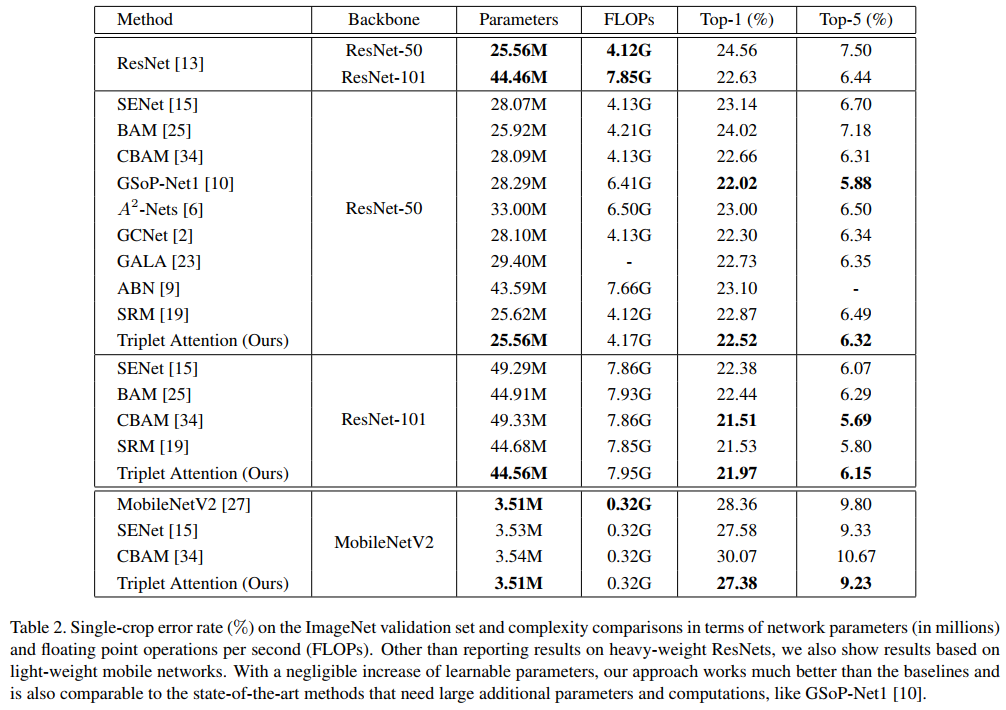
3.1、图像分类实验
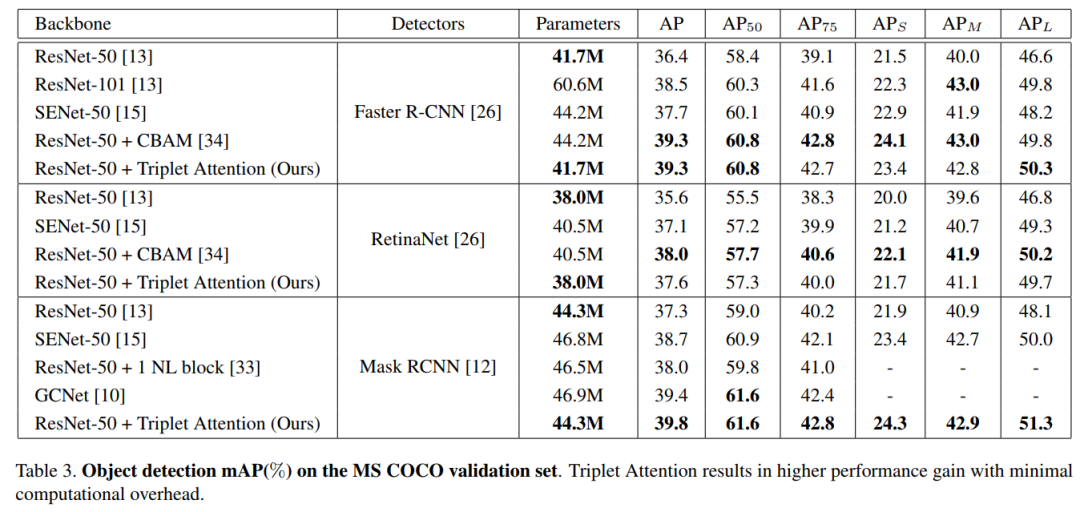
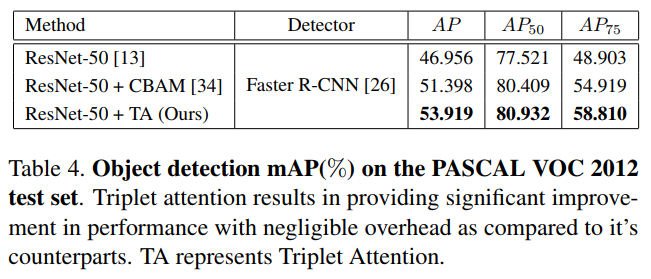
3.2、目标检测实验
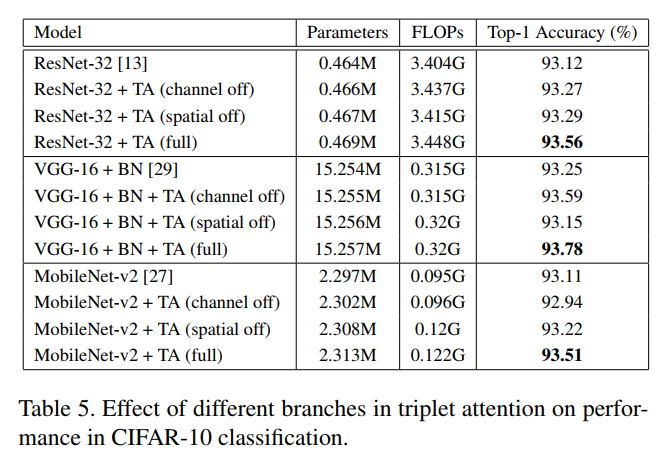
3.3、消融实验
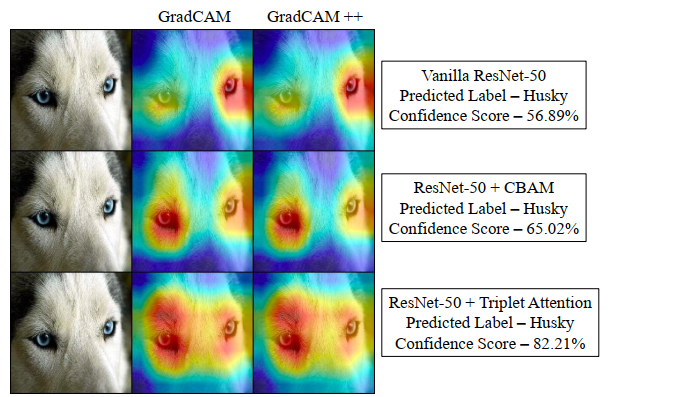
3.4、HeatMap输出对比
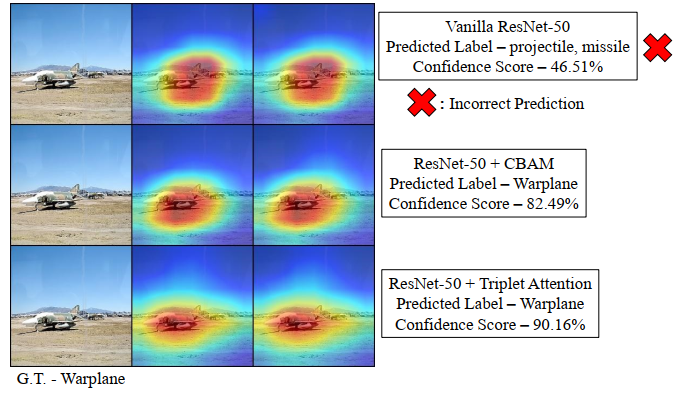
4、总结
在这项工作中提出了一个新的注意力机制Triplet Attention,它抓住了张量中各个维度特征的重要性。Triplet Attention使用了一种有效的注意计算方法,不存在任何信息瓶颈。实验证明,Triplet Attention提高了ResNet和MobileNet等标准神经网络架构在ImageNet上的图像分类和MS COCO上的目标检测等任务上的Baseline性能,而只引入了最小的计算开销。是一个非常不错的即插即用的注意力模块。
更为详细内容可以参见论文中的描述。
References
[1] Rotate to Attend: Convolutional Triplet Attention Module
论文下载
在CVer公众号后台回复:1015,即可下载本论文
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



