一文梳理腾讯 QQ 浏览器 2021AI 算法大赛冠军方案。
历时两个多月的
腾讯 QQ 浏览器 2021AI 算法大赛
[9] 已经告一段落,大赛自 2021 年 8 月 15 日启动以来,受到了全球 AI 算法爱好者及业界的广泛关注。整个赛程历时 68 天,覆盖全球 279 个城市,共吸引来自 276 个不同高校、企业和社会的算法精英 1853 人,组成 852 支队伍参赛,其中进入决赛的 TOP 20 队伍就涵盖了北京大学、清华大学、复旦大学、香港科技大学、中科院大学、华南理工大学、浙江大学、西安交大、中山大学、西安电子科技大学等顶尖院校,也有来自德国、加拿大等国际高校的学生,期间共完成了近 7000 次提交。
![]()
腾讯 QQ 浏览器为优秀参赛团队提供价值共计 41.7 万人民币的总奖池,除此之外每个赛道前 15 名队伍将会额外收获校招直通复试卡,前 8 名队伍可获得 QQ 浏览器实习生直通终面卡。
首届 AI 算法大赛议题设置 “多模态视频相似度” 和“自动超参数优化”两大赛道,以下为 “自动超参数优化” 赛道冠军团队,来自
北京大学的队伍 PKU-DAIR 的方案分享
。(
PKU-DAIR 队成员:姜淮钧、沈彧、黎洋
)
PKU-DAIR 团队的三位成员来自
北京大学崔斌教授 DAIR 实验室的 AutoML 自动化机器学习项目组
。团队研究方向包括超参数优化(HPO)、神经网络结构搜索(NAS)、自动化机器学习系统(AutoML System)等。团队不仅在国际顶级会议上发表了多篇论文,为提高 AutoML 技术的易用性与可用性,团队还相继在 GitHub 开源了黑盒优化系统 OpenBox[1][7]、自动化机器学习系统 MindWare[2][8]等。
在本次自动化超参数优化赛道中,团队基于实验室自研开源黑盒优化系统 OpenBox 进行调参。初赛时使用 OpenBox 系统中的并行贝叶斯优化(Bayesian optimization)算法,决赛在初赛基础上加入早停机制。比赛代码已在 Github 上开源[3]。下面将进行详细介绍。
![]()
在信息流推荐业务场景中普遍存在模型或策略效果依赖于 “超参数” 的问题,而“超参数 " 的设定往往依赖人工经验调参,不仅效率低下维护成本高,而且难以实现更优效果。因此,本次赛题以超参数优化为主题,从真实业务场景问题出发,并基于脱敏后的数据集来评测各个参赛队伍的超参数优化算法。
参赛者需要提交超参数生成的算法代码,算法每一轮需要提供一组超参数,裁判程序会返回超参数对应的 reward。参赛者的算法要求在限定的迭代轮次和时间内,找到 reward 尽可能大的一组超参数,最终按照找到的最大 reward 来计算排名。
针对该赛题,优化器需要在每轮以同步并行方式推荐 5 个超参数配置,共执行 20 轮推荐,即总共搜索 100 个超参数配置。对每个超参数配置均执行完整资源的验证,并且在比赛的问题抽象中,不同超参数的验证时间相同。
根据现有研究,贝叶斯优化是超参数优化(黑盒优化)问题上 SOTA 的方法,而且比赛场景中的超参数空间维度不超过 6 维,并非超高维问题,较适合贝叶斯优化方法,因此我们选定贝叶斯优化作为初赛的搜索算法。另外,问题中所有的超参数均为连续型(离散浮点型)超参数,这决定了我们的超参数空间定义方法、贝叶斯优化代理模型以及优化器的选择,接下来也将分别进行介绍。
超参数优化是典型的黑盒优化问题,即对于目标函数(超参数 - 奖励函数),具体表达式或导数信息是不可知的,只能通过尝试输入获取输出来推测目标函数的内部情况。
贝叶斯优化是解决黑盒优化问题的一个迭代式框架,优化流程包括如下步骤:
使用代理模型(surrogate model)对已有观测历史数据(尝试过的超参数和对应的奖励)进行建模拟合;
使用采集函数(acquisition function)评估搜索空间内的超参数,平衡探索与利用。对采集函数执行优化,找到验证价值最大(使采集函数值最大)的下一组超参数;
在目标函数上评估超参数,得到奖励;
将新评估的超参数和结果加入观测历史数据,重复以上步骤。
注:以下代码分为文字版和图示版,代码以图示版为准。
贝叶斯优化算法封装在 OpenBox 系统中,代码实现的主要流程如下:
def get_suggestions(self, history_container, batch_size): self.surrogate_model.train(X, Y) self.acquisition_function.update(eta=incumbent_value, ...) challengers = self.optimizer.maximize(...) return batch_configs_list
![]()
首先,我们使用 ConfigSpace 库 [4] 定义超参数空间。由于赛题中的超参数均为离散浮点型,并可近似为等间距分布,因此使用 Int 型定义超参数(本质上和使用 Float 定义相同,但避免了赛题中超参数取值范围边缘可能出现不同间距的问题)。在 ConfigSpace 库中,Float 型和 Int 型超参数均被视作连续型,在执行优化时会自动将参数范围缩放至[0, 1]。
贝叶斯优化需要一定数量的历史数据才能启动,我们使用了一种贪心法生成初始超参数配置。该方法从随机候选配置中,逐步挑选距离已有配置最远的配置加入初始配置集合。使用该方法进行初始化能更好地探索超参数空间,经测试效果稍好于完全随机初始化方法。初始化配置数设置为 10 个。该方法集成在 OpenBox 系统中,可通过 init_strategy="random_explore_first" 调用。
贝叶斯优化中的代理模型(surrogate model)有多种选择,包括高斯过程(Gaussian process)、概率随机森林(probabilistic random forest)、Tree Parzen Estimator(TPE)等,其中高斯过程在连续超参数空间上(如数学问题)优化效果较好,概率随机森林在含有分类超参数的空间上优化效果较好。本次比赛只包含连续型超参数,经测试,高斯过程作为代理模型效果最好。高斯过程使用 OpenBox 系统默认的 Matern5/2 核,核超参数通过最大似然 (maximize log likelihood) 得到。
我们使用常用的 Expected Improvement(EI)函数作为贝叶斯优化的采集函数(acquisition function)。在优化采集函数时,我们使用系统中的 "random_scipy" 优化器。该优化器在结合局部搜索与随机采样的基础上,使用 L-BFGS-B 算法对采集函数执行优化。测试表明,相较于单纯使用随机采样,该方法能对采集函数进行更为充分的优化,从而更大程度发挥 GP 模型和 EI 函数的潜能。
传统的贝叶斯优化每轮只能推荐一个超参数配置,因此设计并行推荐方法是一个值得考虑的问题。我们尝试了系统中实现的并行贝叶斯方法,包括 "median_imputation" 中位数插补法,即使用历史观察结果的中位数,填补并行 batch 中推荐配置的性能,重新训练代理模型并得到下一个并行推荐配置,以及 "local_penalization" 局部惩罚法,对并行已推荐配置在采集函数上施加局部惩罚,这两种方法的目的都是提高对超参数空间的探索性。不过经过测试,在本次比赛问题上这些方法的效果不佳,最终我们采用多次优化采集函数并去重的方式执行并行推荐,达到了较好的性能。
此外,为增大贝叶斯优化的探索性,保证算法收敛,我们设置每次推荐时使用随机搜索的概率为 0.1。
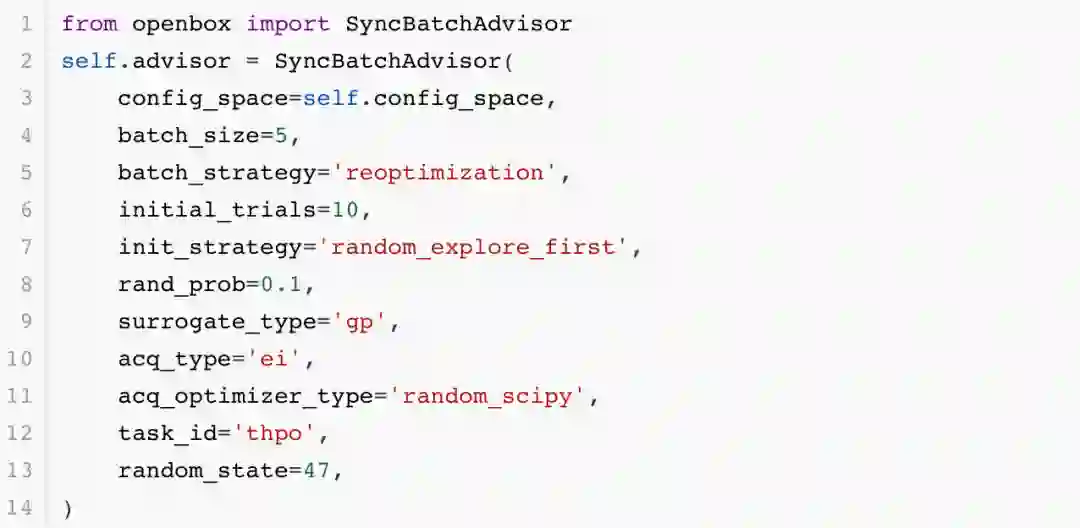
初赛代码仅需调用 OpenBox 系统中的并行贝叶斯优化器 SyncBatchAdvisor,即可实现上述功能:
from openbox import SyncBatchAdvisorself.advisor = SyncBatchAdvisor( config_space=self.config_space, batch_size=5, batch_strategy='reoptimization', initial_trials=10, init_strategy='random_explore_first', rand_prob=0.1, surrogate_type='gp', acq_type='ei', acq_optimizer_type='random_scipy', task_id='thpo', random_state=47,)
![]()
代码以图示为准
每轮执行推荐时,调用 advisor 的 get_suggestions 接口:
def suggest(self, suggestion_history, n_suggestions): history_container = self.parse_suggestion_history(suggestion_history) next_configs = self.advisor.get_suggestions(n_suggestions, history_container) next_suggestions = [self.convert_config_to_parameter(conf) for conf in next_configs] return next_suggestions
![]()
决赛问题在初赛的基础上,对每个超参数配置提供 14 轮的多精度验证结果,供算法提前对性能可能不佳的配置验证过程执行早停。同时,总体优化预算时间减半,最多只能全量验证 50 个超参数配置,因此问题难度大大增加。如何设计好的早停算法,如何利用多精度验证数据是优化器设计的关键。
我们对本地公开的两个数据集进行了探索,发现了一些有趣的性质:
对于任意超参数配置,其第 14 轮的奖励均值位于前 13 轮置信区间内的概率为 95%。
对于任意超参数配置,其前 13 轮中任意一轮的均值比第 14 轮均值大的概率为 50%。
对于任意超参数配置,其 14 轮的置信区间是不断减小的,但均值曲线是任意波动的。
我们也对两两超参数配置间的关系进行了探索,比较了两两配置间前 13 轮的均值大小关系和第 14 轮的均值大小关系的一致性,发现:
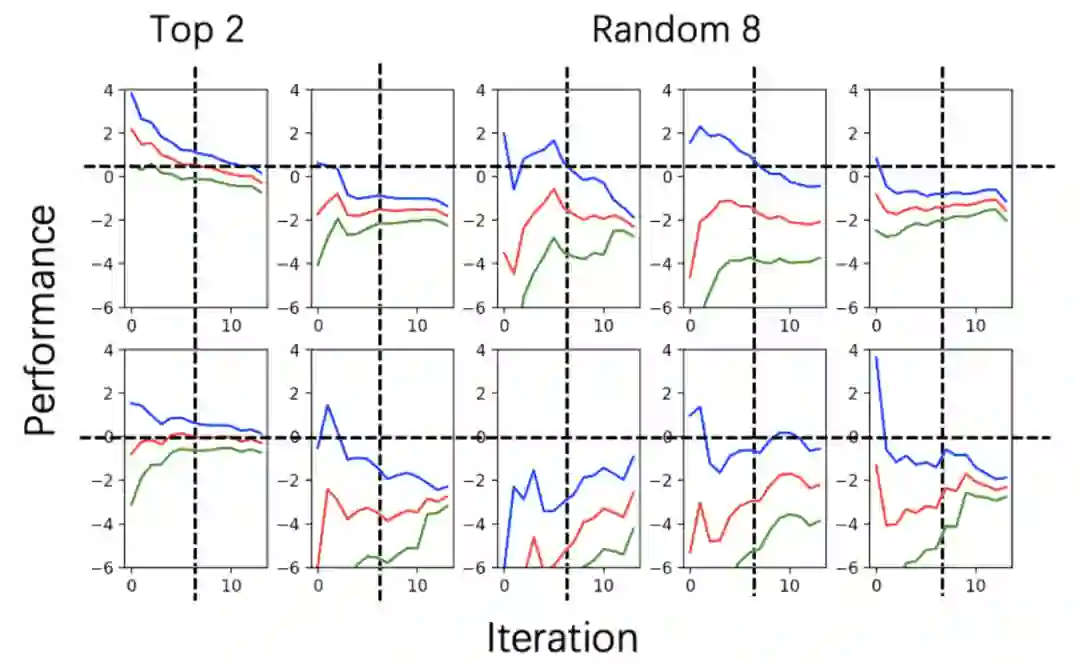
下图为 data-30 空间中最终奖励排名前 2 的超参数和随机 8 个超参数的奖励 - 轮次关系:
![]()
图:data-30 搜索空间中 2 个最好配置和 8 个随机配置的奖励 - 轮数曲线,包含置信上界(蓝色)、均值(红色)、置信下界(绿色)曲线。
我们在比赛开源代码仓库中提供了上述 “数据探索” 代码。
上述数据探索结果表明,根据前 13 轮的置信区间,我们可以推测第 14 轮奖励均值的位置。利用前 13 轮的均值大小关系,我们可以估计第 14 轮最终均值的大小关系,但是由于数据噪音的存在,排名靠前的超参数配置大小关系无法通过部分验证结果预估。由此我们设计了两种早停算法,分别是基于置信区间的早停和基于排名的早停,将在下一部分详细描述。
过于激进的早停策略在比赛中仍然存在问题。如果使用贝叶斯优化只对全量验证数据建模,由于总体优化预算时间很少,早停会减少可用于建模的数据量,使得模型不能得到充分训练。为解决这一问题,我们引入插值方法,增加模型可训练数据。
基于以上考量,最终我们的决赛算法在初赛贝叶斯优化算法的基础上,前期执行完整贝叶斯优化使模型得到较为充分的拟合,后期使用早停技术与插值法,加速超参数验证与搜索过程。下面将对早停模块做详细介绍。
由于超参数配置之间的部分验证轮次均值大小关系与最终均值大小关系存在一定的相关性,我们受异步多阶段早停算法 ASHA[5]的启发,设计了基于排名的早停算法:一个超参数如果到达需要判断早停的轮次,就计算其性能均值处于历史中同一轮次的超参数性能均值的排名,如果位于前 1/eta,则继续验证,否则执行早停。
依据 95% 置信区间的含义,我们还设计了另一种早停方法,即使用置信区间判断当前超参数配置是否仍有验证价值。如果某一时刻,当前验证超参数的置信区间上界差于已完全验证的性能前 10 名配置的均值,则代表至少有 95% 的可能其最终均值差于前 10 名的配置,故进行早停。使用本地数据验证,以空间中前 50 名的配置对前 1000 名的配置使用该方法进行早停,早停准确率在 99% 以上。
经过测试,结合贝叶斯优化时两种方法效果近似,我们最终选择使用基于排名的早停方法。无论是哪种方法,都需要设计执行早停的轮次。早停越早越激进,节省的验证时间越多,但是得到的数据置信度越低,后续执行插值时训练的模型就越不准确。为了权衡早停带来的时间收益和高精度验证带来的数据收益,我们选择只在第 7 轮(总共 14 轮)时判断每个配置是否应当早停。早停判断准则依据 eta=2 的 ASHA 算法,即如果当前配置均值性能处于已验证配置第 7 轮的后 50%,就进行早停。
以下代码展示了基于排名的早停方法。首先统计各个早停轮次下已验证配置的性能并进行排序(比赛中我们使用早停轮次为第 7 轮),然后判断当前配置是否处于前 1/eta(比赛中为前 1/2),否则执行早停:
def prune_mean_rank(self, iteration_number, running_suggestions, suggestion_history): bracket = dict() for n_iteration in self.hps['prune_iters']: bracket[n_iteration] = list() for suggestion in running_suggestions + suggestion_history: n_history = len(suggestion['reward']) for n_iteration in self.hps['prune_iters']: if n_history >= n_iteration: bracket[n_iteration].append(suggestion['reward'][n_iteration - 1]['value']) for n_iteration in self.hps['prune_iters']: bracket[n_iteration].sort(reverse=True) stop_list = [False] * len(running_suggestions) for i, suggestion in enumerate(running_suggestions): n_history = len(suggestion['reward']) if n_history == CONFIDENCE_N_ITERATION: print('full observation. pass', i) continue if n_history not in self.hps['prune_iters']: print('n_history: %d not in prune_iters: %s. pass %d.' % (n_history, self.hps['prune_iters'], i)) continue rank = bracket[n_history].index(suggestion['reward'][-1]['value']) total_cnt = len(bracket[n_history]) if rank / total_cnt >= 1 / self.hps['prune_eta']: print('n_history: %d, rank: %d/%d, eta: 1/%s. PRUNE %d!' % (n_history, rank, total_cnt, self.hps['prune_eta'], i)) stop_list[i] = True else: print('n_history: %d, rank: %d/%d, eta: 1/%s. continue %d.' % (n_history, rank, total_cnt, self.hps['prune_eta'], i)) return stop_list
![]()
对于贝叶斯优化的数据建模,我们尝试了多精度集成代理模型 MFES-HB[6]拟合多精度观测数据。该方法虽然能应对低精度噪声场景,但在决赛极其有限的优化时间限制内,可能无法快速排除噪声的干扰,导致效果不如仅使用最高精度数据建模。
我们最终选择只利用最高精度数据进行建模。为了弥补早停造成的高精度数据损失,我们引入插值方法,增加用于模型训练的数据量,具体来说,就是对早停的配置,设置一个完整验证时的性能均值,插入优化历史执行建模。对于插入值的选取,我们使用已完整验证配置的最终均值中位数进行插值。
def set_impute_value(self, running_suggestions, suggestion_history): value_list = [] for suggestion in running_suggestions + suggestion_history: n_history = len(suggestion['reward']) if n_history != CONFIDENCE_N_ITERATION: continue value_list.append(suggestion['reward'][-1]['value']) self.impute_value = np.median(value_list).item()
![]()
本文介绍了自动化超参数优化赛道的冠军方案,包括贝叶斯优化算法和早停方法。很幸运能够拿到此次比赛的冠军。感谢赛事主办方为我们提供了富有现实意义的比赛场景,让我们积累了宝贵的比赛经验和超参数优化实际经验。希望我们的分享能够对大家有所帮助。
https://github.com/PKU-DAIR/open-box
https://github.com/PKU-DAIR/mindware
https://github.com/PKU-DAIR/2021_AIAC_Task2_1st
[4] https://github.com/automl/ConfigSpace
[5] Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ekaterina Gonina, Jonathan Bentzur, Moritz Hardt, Benjamin Recht, and Ameet Talwalkar. 2020. A System for Massively Parallel Hyperparameter Tuning. Proceedings of Machine Learning and Systems 2 (2020), 230–246.
[6] Yang Li, Yu Shen, Jiawei Jiang, Jinyang Gao, Ce Zhang, and Bin Cui. 2021. MFES-HB: Efficient Hyperband with Multi-Fidelity Quality Measurements. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 8491–8500.
[7] Yang Li, Yu Shen, Wentao Zhang, Yuanwei Chen, Huaijun Jiang, Mingchao Liu, Jiawei Jiang, Jinyang Gao, Wentao Wu, Zhi Yang, Ce Zhang, and Bin Cui. 2021. OpenBox: A Generalized Black-box Optimization Service. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (2021).
[8] Yang Li, Yu Shen, Wentao Zhang, Jiawei Jiang, Bolin Ding, Yaliang Li, Jingren Zhou, Zhi Yang, Wentao Wu, Ce Zhang, and Bin Cui. 2021. VolcanoML: Speeding up End-to-End AutoML via Scalable Search Space Decomposition. Proceedings of VLDB Endowment 14 (2021), 2167–2176.
https://algo.browser.qq.com/
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
完成对车辆车牌的检测和识别,并对行人以及车辆的品牌,颜色,种类进行检测。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com