【牛津大学博士论文】基于强化学习的无地图机器人导航,Reinforcement Learning Based MRN

https://ora.ox.ac.uk/objects/uuid:c466b944-2243-4017-aa7c-46419ddf6c94
导航是移动机器人所需要的最基本的功能之一,允许它们从一个源穿越到一个目的地。传统的办法严重依赖于预先确定的地图的存在,这种地图的取得时间和劳力都很昂贵。另外,地图在获取时是准确的,而且由于环境的变化会随着时间的推移而退化。我们认为,获取高质量地图的严格要求从根本上限制了机器人系统在动态世界中的可实现性。本论文以无地图导航的范例为动力,以深度强化学习(DRL)的最新发展为灵感,探讨如何开发实用的机器人导航。
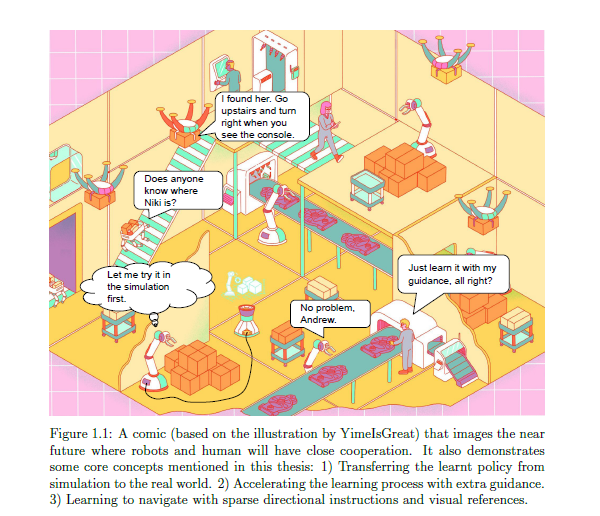
DRL的主要问题之一是需要具有数百万次重复试验的不同实验设置。这显然是不可行的,从一个真实的机器人通过试验和错误,所以我们反而从一个模拟的环境学习。这就引出了第一个基本问题,即弥合从模拟环境到真实环境的现实差距,该问题将在第3章讨论。我们把重点放在单眼视觉避障的特殊挑战上,把它作为一个低级的导航原语。我们开发了一种DRL方法,它在模拟世界中训练,但可以很好地推广到现实世界。
在现实世界中限制移动机器人采用DRL技术的另一个问题是训练策略的高度差异。这导致了较差的收敛性和较低的整体回报,由于复杂和高维搜索空间。在第4章中,我们利用简单的经典控制器为DRL的局部导航任务提供指导,避免了纯随机的初始探索。我们证明,这种新的加速方法大大减少了样本方差,并显著增加了可实现的平均回报。
我们考虑的最后一个挑战是无上限导航的稀疏视觉制导。在第五章,我们提出了一种创新的方法来导航基于几个路点图像,而不是传统的基于视频的教学和重复。我们证明,在模拟中学习的策略可以直接转移到现实世界,并有能力很好地概括到不可见的场景与环境的最小描述。
我们开发和测试新的方法,以解决障碍规避、局部引导和全球导航等关键问题,实现我们的愿景,实现实际的机器人导航。我们将展示如何将DRL作为一种强大的无模型方法来处理这些问题。
https://ora.ox.ac.uk/objects/uuid:c466b944-2243-4017-aa7c-46419ddf6c94

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RLMRN” 可以获取《基于强化学习的无地图机器人导航,Reinforcement Learning Based MRN》专知下载链接索引







