从1750亿到1.6万亿,人工智能未来:除了大模型,还有什么?

自1956年的达特茅斯会议开启“人工智能元年”,该领域经过了两起两落。到2006年前后,虽然Hinton等人已发表论文证明,通过增加神经网络的层数,可以学到更好的数据表征,并进一步提升模型的性能,但是大家认为这还是新瓶换旧酒,还在迟疑中。直到深度学习概念的推广,在语言识别等领域获得成功。特别是2012年AlexNet在ImageNet的比赛中取得重大突破,性能提升10多个百分点。深度神经网络的实际效果进一步得到肯定,并掀起了人工智能的第三波热潮。CV“四小龙”亦在此时间段前后成立,开启感知智能的创业浪潮。
ResNet和AlphaGo等成果的推出,进一步完善神经网络的训练并拓展了其应用范围,从而将这波浪潮推到新高度。2018年秋季谷歌推出BERT,横扫了11项自然语言处理(NLP)任务,随后OpenAI亦相继推出GPT-2、GPT-3,让大家看到认知智能落地的潜在性。
时光如梭,2021年悄然过去。蓦然回首,2021年的AI大事件有哪些呢?新的一年,AI又将呈现怎样的发展趋势?我们将按下述几个主题展开:
大模型不断推出,提高行业准入壁垒;
构建基石模型, 拓展应用边界;
考虑公平和伦理,保证落地的安全和责任。

大模型不断推出,提高行业准入壁垒
从业界的角度看,2021年的一个关键词是“大模型”。
如图1所示,当GPT-3的模型规模达到1750亿参数后,国外大厂又提出了各样的模型,进一步提高了模型的大小。具有代表性的成果有:
Switch Transformer:谷歌于2021 年1月11日提出,声称参数量从GPT-3的1750亿提高到1.6万亿。Switch Transformer基于稀疏激活的专家模型(Mixture of Experts), 论文中提到在计算资源相同的情况下,训练速度可以达到 T5 (Text-To-Text Transfer Transformer)模型的4-7倍[1]。
MT-NLG:2021 年年底,英伟达与微软联合发布了MT-NLG (Megatron-Turing Natural Language Generation),该模型含参数5300亿个,宣称是目前最大的且最强的语言生成预训练模型[2]。
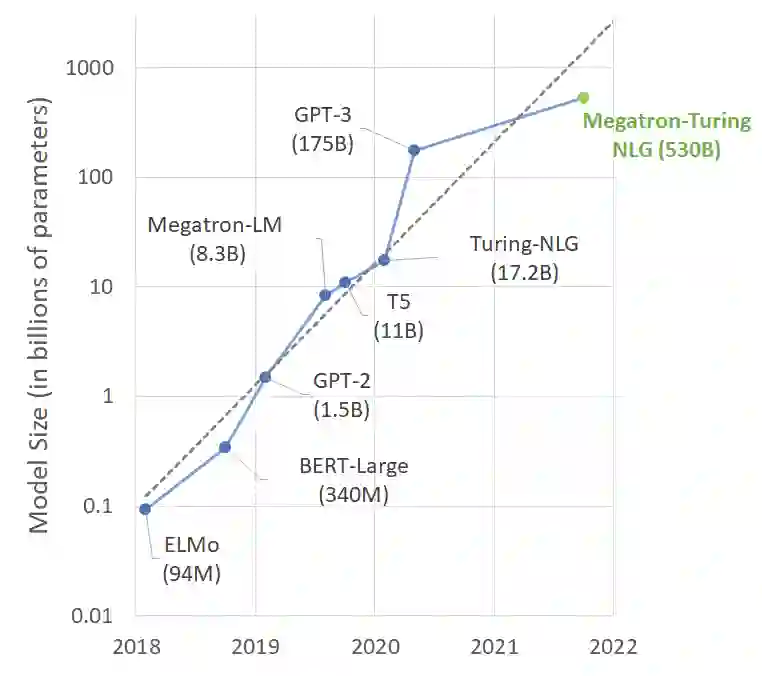
图1. NLP预训练模型参数随着时间发展的趋势(图片源自[2])
国内在今年亦推出了万亿级的预训练模型和开源计划。例如:
悟道 2.0:2021 年6月,北京智源研究院发布悟道 2.0,参数规模达到1.75万亿,是GPT-3的10倍,超过了谷歌Switch Transformer的1.6万亿参数记录[3]。
“封神榜”大模型:2021 年 11 月,在深圳IDEA大会上,粤港澳大湾区数字经济研究院(简称“IDEA”)理事长沈向洋正式宣布,开启“封神榜”大模型开源计划,涵盖五个系列的亿级自然语言预训练大模型,其中包括了最大的开源中文BERT大模型“二郎神”系列[3]。
目前,预训练大模型已成为各家打造人工智能基础设施的利器,从而提高行业的准入壁垒。实现大模型,需要超大规模的算力和海量的数据。这对普通公司或者一般实验室会造成一定的困难。然而就技术而言,目前的大模型离我们期望的通用人工智能还有很大的差距。如何让电脑有更多的创意,知识不断地积累,还需要进行大量的技术探索和创新。在落地的时候还需要更多地跟场景结合,甚至需要场景创新,才能更好地服务相关行业。

构建基石模型,拓展应用边界
大模型的不断推出,基本上基于深度神经网络和自学习的方式进行,各个模型趋于“同质化”(Homogenization)。因此,斯坦福大学的Percy Liang于2021年3月份召集了100多位研究学者,发起了基石模型(Foundation Models)的讨论,并于8月发表了一篇200多页的关于基石模型的综述报告[5]。
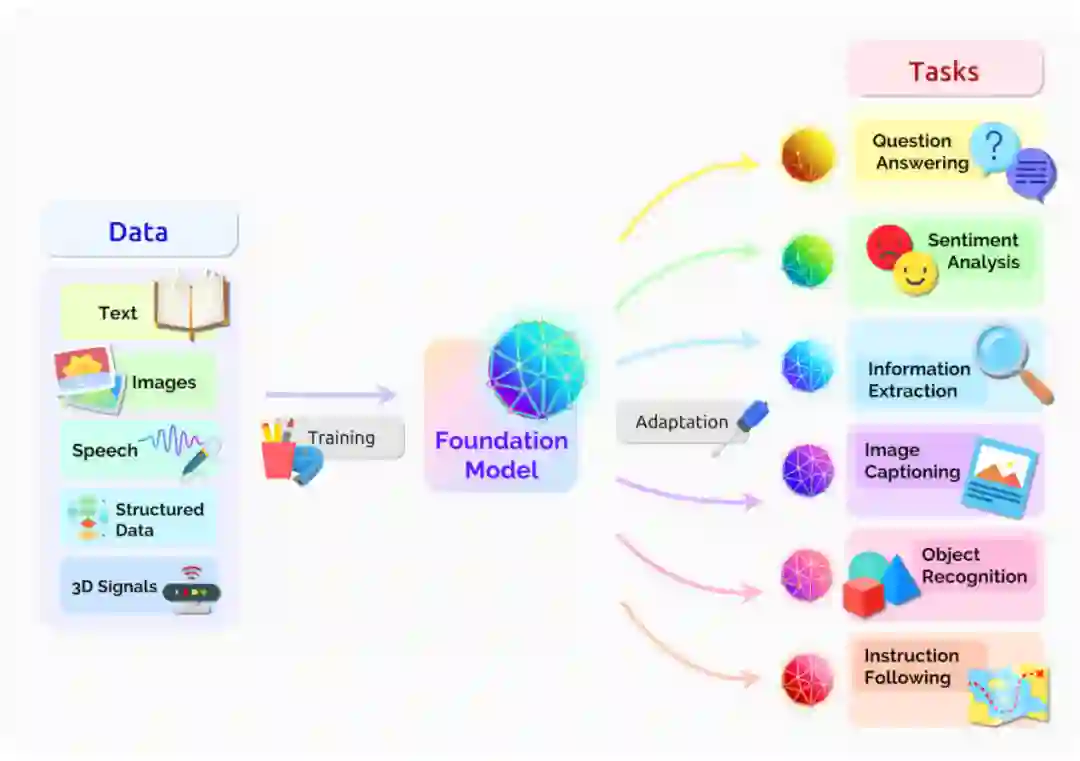
图2 基石模型经文本、图像、语音等多模态数据训练,微调后服务下游应用(图片源自[5])
该报告定义了基石模型,试图囊括目前大模型的能力、应用、相关技术和社会影响。主要从语言、视觉、机器人、推理、交互、理解等讨论基石模型的能力,在应用方面主要探讨医疗、法律和教育这三个对社会很重要的学科。
与此同时,在构建基石模型方面,亦出现了几个有影响力的工作,拓展了应用的边界。例如:
Copilot:6月,微软收购的GitHub联合OpenAI推出首个AI代码生成器[6]。该工具基于GPT-3,即Transformer的架构,通过训练从GitHub上爬取数十亿行开源代码和相关英文注释,实现代码的自动生成,试图进一步辅助程序员的代码开发。
FLAVA: 到年底, Facebook (现称Meta)亦基于Transformer[8]推出FLAVA (A Foundational Language And Vision Alignment Model),试图用一个统一的模型适用于自然语言处理、计算机视觉、多模态的不同任务,论文显示在此三种领域共计35个任务,都有着出色的表现[8]。该模型利用Vision Transformer (ViT) [9]的方式对图像进行编码,BERT[10]的方式对文本进行编码,并设计相应的多模态编码方式和相应的损失函数,对模型进行训练,并获得很好的性能。
在学术界,对比学习、多模态多任务联合学习,已经广泛使用于基石模型的训练中。但是模型的解释性和拓展性还有很多的探索空间。

考虑公平和伦理,保证落地的安全和责任
尽管目前AI技术在刷脸支付、自动驾驶、智能语音、智能安防等应用的商业化探索和落地,已开始改变我们的生活模式,并带来巨大的便利,AI技术仍要面对更多、更复杂的场景。2021 年是AI技术迫切需要落地的一年。在落地的过程中,我们经常需要面对如下问题:
落地场景是否有好的数据?
AI技术如何更好地降本增效、规模化和商业化?
如何保证AI技术者掌握相关业务知识,并理解业务需求?
而从AI技术层面看,AI落地的三要素是: 算力、算法和数据。这就涉及到公平性和伦理的问题。特别是,最近几年数据的隐私安全、AI算法的责任,都成为社会的关注热点。在今年我国亦出台相关法律从不同层面保障用户的隐私和利益,包括
数据层面:6月《数据安全法》通过,11月《个人信息保护法》开始生效,包括2016年通过的《网络安全法》从不同的角度规范数据的使用和保护用户个人信息。
算法层面:1月颁布了《互联网信息服务算法推荐管理规定》和9月亦印发《关于加强信息服务算法综合治理的指导意见》的通知,进一步加强了互联网信息服务算法安全治理。
伦理规范:6月28日世卫组织亦发布“卫生领域人工智能的伦理和治理”的报告,提出人工智能为所有国家的公众利益服务的六项原则。9月25日,我国亦发布《新一代人工智能伦理规范》,为从事人工智能相关活动的自然人、法人和其他相关机构等提供伦理指引。11月25日联合国教科文组织亦举行新闻发布会,介绍该组织正式通过的首份人工智能伦理问题全球性协议。
AI技术在落地的过程,要兼具安全和确定相关的责任方,同时还要顾及公平和伦理。随着众多新的法案的出台,后续的落地会受到更多的监管和共同治理,走向“科技向善、AI向善”的道路。

小结与展望
目前人工智能技术距离理想的通用人工智能的路还很长,2021年有更多的大厂试图构建相应的基石模型,并把AI技术拓展到更大的应用范围。
在技术层面,还需要大量的探索,例如,是否有更好的架构替代基于深度神经网络的架构?是否有更快的方式提升计算性能?大模型如何在实际场景很好地落地?相关的技术,如Neurosymbolic AI、量子计算都很值得研究。
在应用层面,AI跟科学发现、AI制药、AI跟大数据应用结合等等,都有很多的机会。如何将算法与场景结合、技术与产业融合,是未来实现AI落地应用必须思考的问题。国内已有一些机构或团队正在探索研产结合的可能路径,例如IDEA的CTO Labs合作计划,聚集科研人才和产业科技团队,共同挖掘产业痛点,更有效推进核心技术研发和落地。最近亦与数说故事合作,在数说的产品中提供关键技术模块。



参考文献:
[1] William Fedus, Barret Zoph, Noam Shazeer: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. CoRR abs/2101.03961 (2021).
[2] Paresh Kharya and Ali Alvi. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model.
[3] 全球最大智能模型“悟道2.0”重磅发布. https://hub.baai.ac.cn/view/8375.
[4] 2021 IDEA大会重磅宣布,“封神榜”大模型开源计划开启——“封神榜”大模型系列宣告开源,有多“神”?https://idea.edu.cn/news/20211124222723.html.
[5] Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, et al.: On the Opportunities and Risks of Foundation Models. CoRR abs/2108.07258 (2021).
[6] Gershgorn, Dave. GitHub and OpenAI launch a new AI tool that generates its own code. The Verge. 29 June 2021 [6 July 2021].
[7] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, Douwe Kiela: FLAVA: A Foundational Language And Vision Alignment Model. CoRR abs/2112.04482 (2021).
[8] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021.
[9] IDEA合作企业数说故事产品上新 携手推动商业应用智能化.
https://zhuanlan.zhihu.com/p/458813386. 2022-01-18.

《新程序员003》正式上市,50余位技术专家共同创作,云原生和数字化的开发者们的一本技术精选图书。内容既有发展趋势及方法论结构,华为、阿里、字节跳动、网易、快手、微软、亚马逊、英特尔、西门子、施耐德等30多家知名公司云原生和数字化一手实战经验!


☞IntelliJ 平台彻底停用 Log4j 组件!




