总结机器学习3个时代的算力规律:大模型的出现改变了什么?
预测机器学习领域的进展是很困难,其与行业、政策和社会中的参与者有着重要的相关性。
十年后计算机视觉会好多少?机器能否写出比我们更好的小说吗?我们将能够自动化哪些工作?
这些问题回答起来是很困难,因为它们取决于许多因素。然而,随着时间的推移,所有这些因素的影响中有一个因素——算力,有着惊人地规律。
已有数据显示,2010年之前,训练算力的增长率符合摩尔定律(Moore’s law),大约每20个月翻一番。
从2010年之后深度学习开始来临,训练算力的增长率大幅度提升,大约每6个月翻一番。2015年末,随着许多公司开始开发大规模的机器学习模型,对训练算力的要求提高了10到100倍,于是,一种新的趋势又出现了。
基于上述发现,一支联合团队在其研究COMPUTE TRENDS ACROSS THREE ERAS OF MACHINE LEARNING一文中,将机器学习的算力趋势分为三个时代:前深度学习时代,深度学习时代和大规模时代,很好地梳理出当前的算力演进脉络。
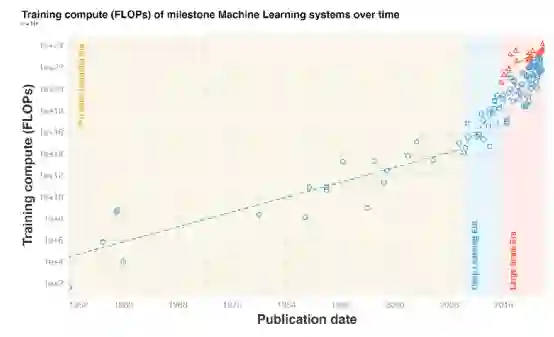
图丨里程碑式大模型信息一览
更具体的,这项研究共有以下三点贡献:
1)策划了一个包含100多个具有里程碑意义的机器学习系统的数据集,并对训练它们所需的算力进行了注释。
2)初步将算力趋势划分为三个不同的时代:深度学习前时代、深度学习时代和大规模时代。这项研究提供了每个时代的倍增时间的估计。
3)在一系列附录中展示了为验证这项研究的结论所开展的一些替代实验,讨论了数据的替代解释以及与以前工作的差异。
另外,这项研究所采用的数据集、数据和交互式可视化均是公开的。
一、深度学习的出现
这项研究根据三个不同的时代和三个不同的趋势来解释这项研究整理的数据。
简而言之,在深度学习开始之前,有一个增长缓慢的时代。2010 年前后,这一趋势加速发展,此后一直没有放缓。另外,在 2015 年到 2016 年出现了大规模模型的新趋势,以相似的速度增长,但超过了之前的一到两个数量级(orders of magnitude,OOM)。

下面,这项研究将首先讨论 2010年至2012年左右向深度学习的过渡时期。然后讨论大约在 2015年至2016 年出现的大规模模型时代。
深度学习出现前后存在两种截然不同的趋势机制。在此之前,训练机器学习系统所需的计算量每 17 到 29 个月翻一番。随后,整体趋势加快,每 4 到 9 个月翻一番。
前深度学习时代的趋势大致符合摩尔定律,根据该定律,晶体管密度大约每两年翻一番——通常简化为计算性能每两年翻一番。
目前尚不清楚深度学习时代从何时开始——从前深度学习时代到深度学习时代的过渡没有明显的不连续性。此外,这项研究将深度学习时代的开始时间分别定在 2010 年和 2012 年,结果几乎没有变化,如表2所示。
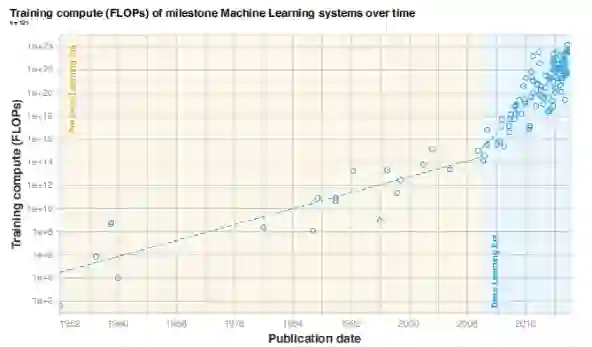
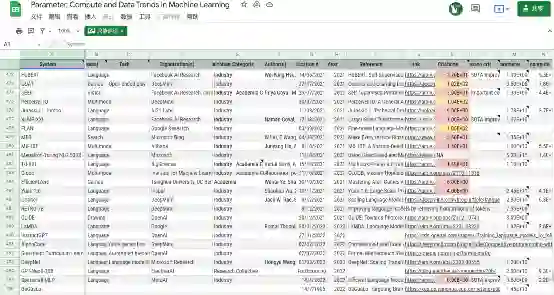
图2. 1952年至2022年间100多个里程碑机器学习系统的训练算力趋势。请注意 2010 年左右趋势的斜率变化。
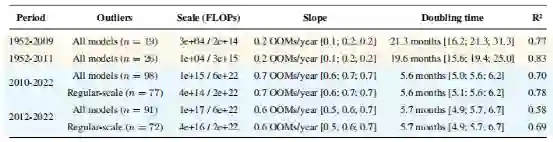
表2 1952 年至 2022 年 ML 模型的对数线性回归结果
二、大模型的出现
2015-2016 年左右出现了大规模模型的新趋势。
这种新趋势始于 2015 年底的 AlphaGo,并一直持续到今天。这些大规模模型是由大公司训练的,其较大的训练预算想必能够打破之前的趋势。
另外,常规比例模型的趋势仍不受干扰。这种趋势在 2016 年前后是连续的,斜率相同,每5到6个月翻一番,见表3大规模模型中计算量增加的趋势明显变慢,每9到10个月翻一番。由于这项研究对这些模型的相关数据有限,所以明显的放缓的趋势也可能是噪声的结果。这项研究发现的结果与2018年Amodei & Hernandez等人的发现形成鲜明的对比,后者发现 2012 年至 2018 年之间的倍增期更快,为3.4个月,而2021年Lyzhov发现2018年至2020年之间的倍增期更长,超过2年。
由于他们的分析数据样本有限且假设单一趋势,因此与这项研究发现的结果存在巨大差异。而这项研究分别研究大规模模型和常规规模模型,且大规模模型的趋势是最近几年才出现,以前的分析无法区分这两种不同的趋势。
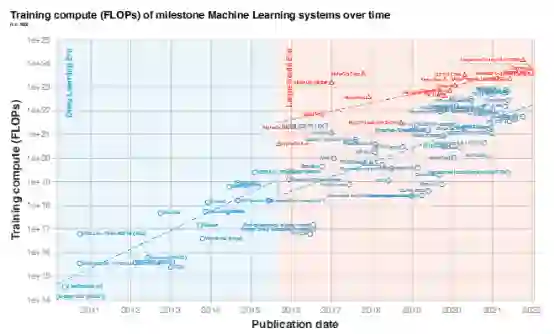
图2. 2010~2022年100多个里程碑式机器学习系统的训练计算趋势。注意 2016 年左右可能出现的大规模模型新趋势。其余模型的趋势在 2016 年前后保持不变。
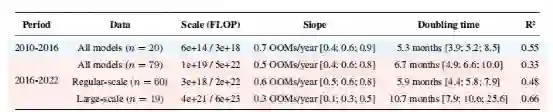
表3. 2010~2022年数据的对数线性回归结果。2015 年之前的常规尺度模型的趋势在之后继续不间断。
三、结论与方向
这项研究通过管理100 多个里程碑式机器学习系统的训练计算数据集来研究算力趋势,并使用这些数据分析趋势如何随着时间的推移而增长。
团队表示,希望这项研究的工作能够帮助其他人更好地了解到机器学习系统的最新进展是由规模增加推动的,从而进一步改进对高级机器学习系统开发的预测。
此外,训练算力的增长趋势,凸显了硬件基础设施和工程师的战略重要性。
机器学习的前沿研究已成为访问大量算力预算或算力集群以及利用它们的专业知识的代名词。
这项研究未涉及的一个方面是用于训练机器学习模型的另一个关键可量化因素——数据,未来可以尝试研究数据集大小及其与算力趋势的关系。
论文链接:
https://arxiv.org/pdf/2202.05924.pdf