ICLR2020满分论文:PPO带来的性能提升来源于code-level?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:https://zhuanlan.zhihu.com/p/99061859 作者:风清云
本文来自知乎专栏,仅供学习参考使用,著作权归作者所有。 如有侵权,请私信删除。
一、摘要
二、简单回顾PPO与TRPO
TRPO(Trust Region Policy Optimization)[2]的核心优化公式如下:
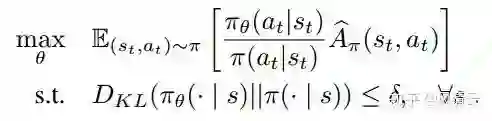
PPO(Proximal Policy Optimization)[3] 的核心优化公式如下:
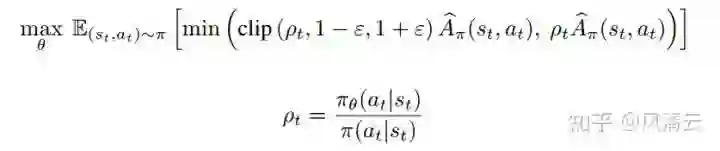
三、PPO论文中未提到的代码层面的优化技巧
作者在原文中共列出了9条在PPO的代码中用到而论文中未提出来的优化技巧,由于作者只是用了前4个优化技巧进行实验,因此笔者在这里只介绍前4个代码层面的技巧。
1、Value function clipping
在RL中计算TD-error时常用的表达式为:
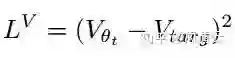
而在PPO的代码中对值函数进行了裁切后,才计算TD-error:
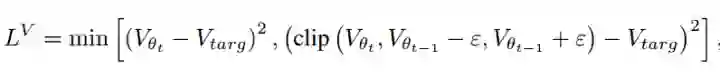
2、Reward scaling(不知道scale怎么翻,反正就是乘个尺度)

3、Orthogonal initialization and layer scaling
PPO的网络参数使用的是正交初始化,而不是随机初始化(这和常规不同)和layer scaling的技巧。
4、Adam learning rate annealing
PPO用的Adam优化方法,学习率是退火式下降的,而非固定不变的。(不是直接tf.train.Adamoptimizer(learning_rate).minimize(...))
后续的几个优化技巧很简单,比如对状态向量进行归一化,裁切,对奖励进行裁切,激活函数的选择等。具体参考[1]
四、实验结果
 来源:[1]
来源:[1]
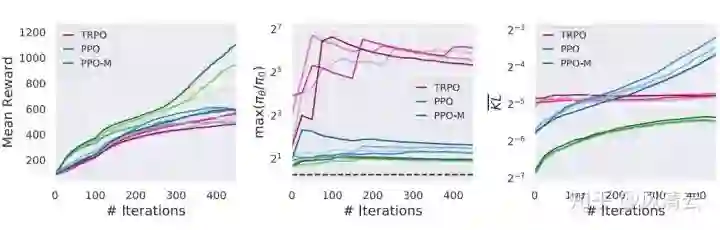 来源:[1]
来源:[1]
再来看两个更加清晰的表格。
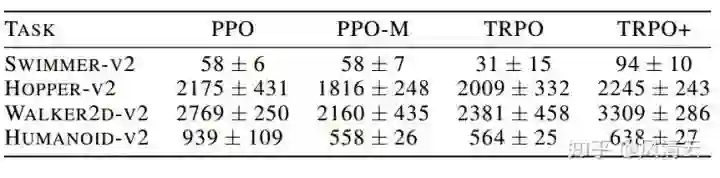 来源:[1]
来源:[1]
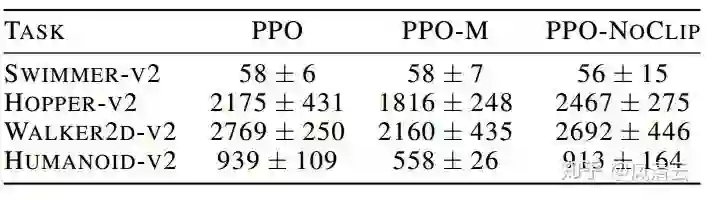 来源:[1]
来源:[1]
表格内容可以理解为五中算法在不同TASK上的得分情况。根据上述表格,可以得出以下结论:
(1)PPO-M在三个TASK上的表现要明显逊于PPO,且TRPO在所有TASK中的表现均远逊于TRPO+。而这之间的差别是是否使用了代码层面的优化技巧,这表明了代码层面的优化技巧对agent的性能表现有很大的影响;
(2)PPO-NoCLIP和PPO在四个TASK上的表现可以说是无明显差别。这表明了PPO论文里提出的裁切技巧的使用与否对agent的性能表现没有很大的影响(至少不如代码层面的优化技巧带来的影响)。
五、总结
最后作者建议在设计RL算法时,应该仔细考虑算法中的每个部分可能对agent的性能带来的影响,一旦一个算法过于复杂,则难以分析究竟是哪一部分给agent带来的优异表现。
贴出作者原文的建议:
 来源:[1]
来源:[1]
笔者认为作者提出的建议是非常值得学习考虑的。现在到处用的都是Deep RL,如果不仔细理解每一个技巧能够带来的性能影响,而是code tricks以一把梭的形式全部扔到炉子里去炼,则得出的丹药所具备的功能都不知道来源于哪一味原材料,这是非常不严谨的。
参考文献:
【1】Implementation Matters in Deep RL: A Case Study on PPO and TRPO,openreview.net/forum?
【2】John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International Conference on Machine Learning, pp. 1889–1897, 2015a.
【3】John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




