深度学习在计算机视觉各项任务中的应用
点击“计算机视觉life”关注,置顶更快接收消息!
本文转载自数学与人工智能

Mask-RCNN进行对象检测和实例分割
现在,只有一个问题:如何设计你的模型呢?
计算机视觉是一个广泛而复杂的领域,解决方案并没有那么清晰。CV中的许多标准任务也需要特殊的考虑:分类,检测,分割,姿态估计、图像增强和复原等等。虽然,用于这些任务的最先进的网络都具有共同的模式,但是它们仍然需要自己的独特设计。
那么该怎么为不同的任务建立模型呢?让我们一起来看看如何用深度学习完成这些计算机视觉任务。
Classification
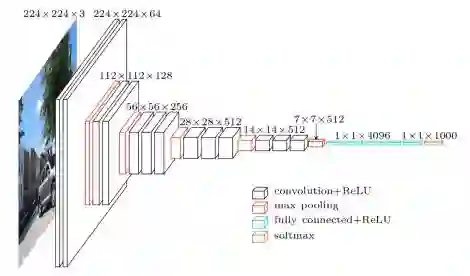
分类是所有视觉任务中最知名的。图像分类网络以固定大小的图像作为输入。输入图像可以具有任意数量的通道,但对于RGB图像通常为3。当我们设计网络的时候,图像分辨率在理论上可以是任何大小,只要它能够支持我们在整个网络中执行的下采样量。
比如说,如果我们进行4次下采样,那么我们输入图像的分辨率最少得24 = 16 x 16。
随着网络的深入,我们试图将所有信息压缩并用一维向量表示,这时空间分辨率会降低。为了保证网络能够始终拥有持续提取所有信息的能力,将按比例地增加特征图的数量以适应分辨率的降低。即在下采样过程中我们会损失空间信息,为了适应这种损失,扩展特征图来增加语义信息。
在进行了了一定数量的下采样后,将特征展开为1维向量,并馈入一系列全连接层。最后一层输出数据集的分类。
Object Detection
物体检测器有两种类型:one-stage和two-stage.
两种类型都始于anchor boxes,这些是默认的边界框。检测器是去学习这些候选区域和真实区域之间的差异,而不是直接预测边框。
在two-stage 检测器中,通常会有两个网络:候选区域提取网络(box proposal network)和分类网络(classification network)。box proposal network提取它认为物体最可能出现的区域的坐标。这些是和anchor box关联起来的。分类网络获取每个边界框,并对其中的物体进行分类。
在one-stage检测器中,提取和分类网络融入同一个阶段中。该网络直接预测边界框坐标和分类物体。因为两部分被融在一起,one-stage检测器运行速度比two-stage检测器运行速度更快。当然,因为两个任务分别进行,two-stage检测器拥有更高的精确度。
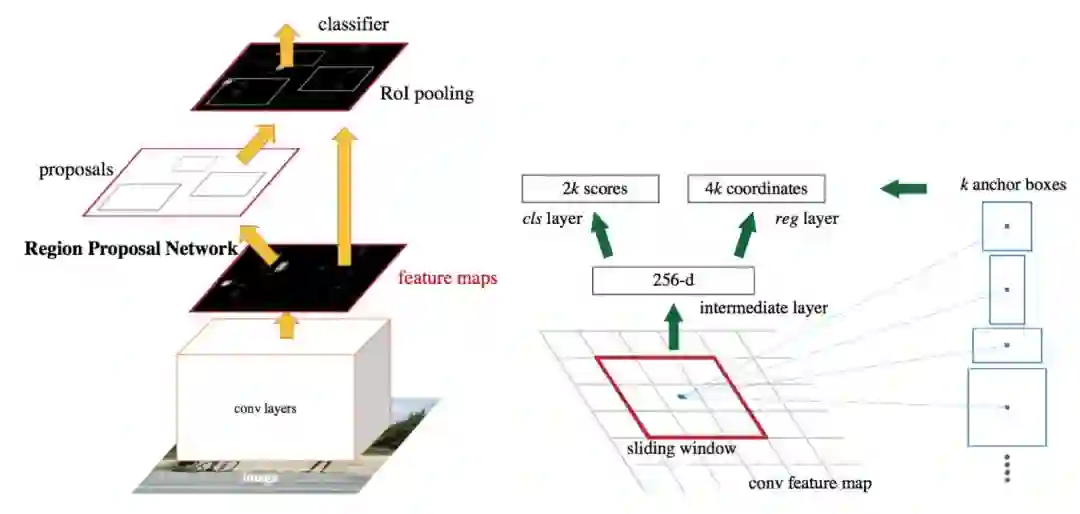
Faster-RCNN two-stage物体检测器结构
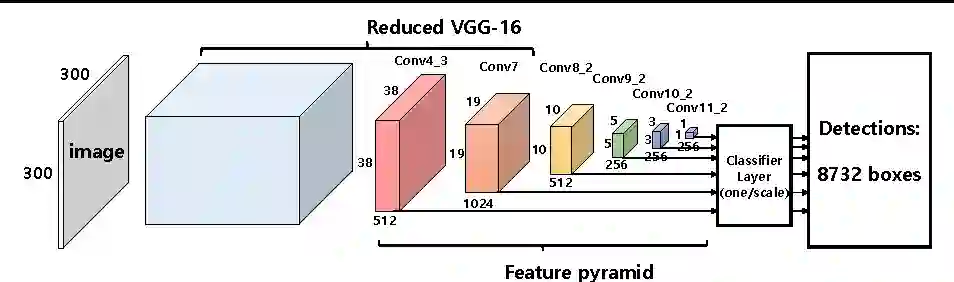
SSD one-stage物体检测器结构
Segmentation
分割在视觉任务中有些特殊,因为用于图像分割的网络需要同时学习低层级和高层级的信息。低层级信息用于按照像素,准确分割图像中的每块区域和物体,高层级信息直接用于分类这些像素。这使得网络设计要结合来自模型底层(对应着低层级的空间信息)和高层(对应着高层级的语义信息)的信息。
下面,我们首先将图像输入一个分类网络。然后,从网络的每一级提取特征,得到从低层到高层的信息。每级信息在结合之前都是独立处理的。在融合所有信息的时候,我们对特征图进行上采样以得到与输入图像分辨率一致的特征图。
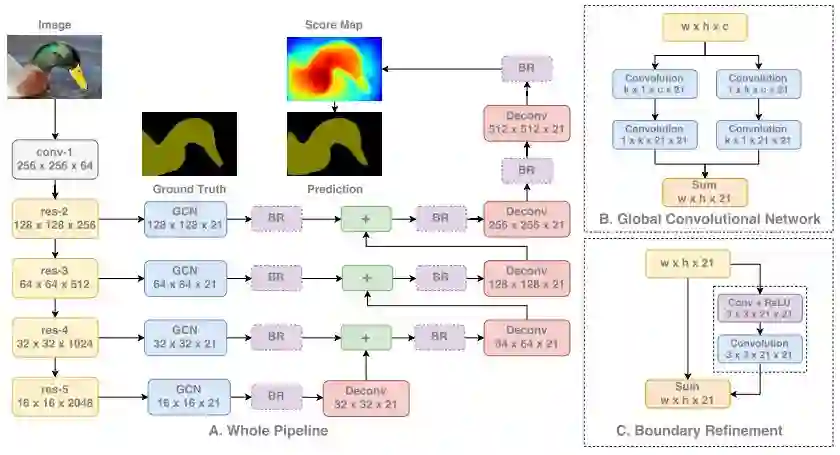
GCN 分割结构
Pose Estimation
姿态估计模型需要完成两个任务:(1)检测图像中身体部分的关键点 (2)将这些关键点正确的连接。
完成这分为三个部分:
1、用标准的分类网络提取图像中的特征;
2、基于这些特征,训练一个子网络来预测一组2D热图。每一组热图都与特定关键点关联并且包含了关键点是否存在于图像的置信度;
3、还是基于分类网络提取到的特征,我们训练一个子网络来预测一组2D向量场,其中每个向量场编码关键点之间的关联程度。有高关联度的关键点则是相互连通的。
将子网络与模型一起训练,使得关键点检测和连接同时进行优化。
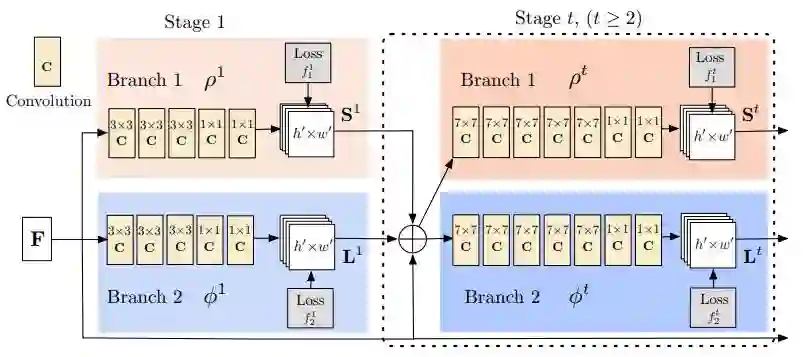
OpenPose姿态估计架构
Enhancement and Restoration
图像增强和复原是很独特的。我们不对它们做任何下采样,因为我们真正关心的是细节的准确度。下采样会完全丢失这些信息,因为它会减少大量像素。相反的,所有处理过程都是在图像完整分辨率下进行的。
输入我们想要增强或者恢复的图像到网络中,没有任何修改,保证完整的分辨率。网络简单地由许多卷积和激活函数组成。这些模块通常来自于图像分类使用的模块,例如Residual Blocks、Dense Blocks、Squeeze Excitation Blocks等等。
最后一层没有任何激活函数,甚至没有sigmoid或者softmax函数,因为我们想直接预测图像像素,不需要任何概率。
上述就是这类网络的全部内容。在图像的全分辨率下进行大量的处理来获得高空间精度,这种方式也可以用于其他任务中。
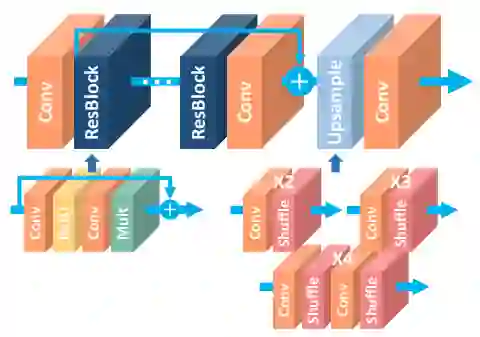
EDSR Super-Resolution 架构
Action Recognition
动作识别是少数几个需要视频数据才能较好运行的应用之一。要对动作进行分类,我们需要了解随时间变化的场景,这自然需要视频数据。
我们要训练网络学习空间(spatial)和时间(temporal)信息,即时间和空间上的变化。解决这个问题最好的一个模型是3D CNN。
一个3D CNN,顾名思义,使用3D卷积的卷积网络!和一般CNNs的差别在于,3D CNN的卷积应用于3个维度:宽度、高度、还有时间。
因此,输出的每一个像素的预测计算不仅基于它周围的像素,同时也基于前一帧和后一帧相同位置上的像素。
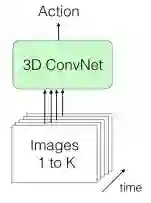
直接输入大批量图像
视频帧可以通过许多方式传递:
(1)直接大批量传递,就像上图所示。因为我们传递的是有序列的帧,所以空间和时间信息都可以得到。
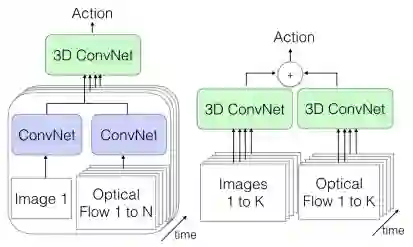
单帧+光流(左)+光流(右)
(2)还可以在一个流中传递单个图像帧(数据的空间信息)和来自视频的对应光流(数据的时间信息)。我们将使用常规的2D CNN来提取特征,然后传递到结合了两种类型信息的3D CNN。
(3)将帧序列输入到一个3D CNN,将视频的光流输入到另一个3D CNN。这两种数据流都能具有可用的空间和时间信息。这会是三种方法中最慢的一种,但是也是最准确的,因为对视频的两种不同表示进行处理,它们包含了所有的信息。
上述的网络都会输出视频的动作分类。
深研资料
原文链接:
https://towardsdatascience.com/how-to-do-everything-in-computer-vision-2b442c469928
图像分割:
https://towardsdatascience.com/semantic-segmentation-with-deep-learning-a-guide-and-code-e52fc8958823
增强和复原
Residual Blocks:
https://arxiv.org/pdf/1512.03385.pdf
Dense Blocks:
https://arxiv.org/pdf/1608.06993.pdf
Squeeze Excitation Blocks:
https://arxiv.org/pdf/1709.01507.pdf
3D CNN:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.442.8617&rep=rep1&type=pdf


