这个卷积神经网络能够识别出“恐怖分子”!(Paper+数据集)
人脸识别一直充满了挑战。
像戴假发,改变发型、发色,戴眼镜,剃掉胡子或留起胡子等等对于面部的物理伪装都会对身份识别产生严重的影响,而脸识别的表现也会大大降低。
因此,本文介绍将一种全新的伪装人脸识别架构,通过空间融合深度神经网络(SpatialFusion deep convolutional network)提取面部关键点(Facial key-points)识别伪装过的人脸。
论文的作者是来自剑桥大学的Amarjot Singh、印度国家理工学院的Devendra Patil、G Meghana Reddy、印度科学院的SN Omkar。将发表于下月的ICCV Workshop。
摘要
伪装人脸识别(Disguised FaceIdentification)架构:利用空间融合深度神经网络提取面部关键点,连接面部关键点形成星状网络结构,分类框架根据星状网络的连接方向进行面部身份识别。
提供了简单和复杂两个面部伪装数据库(FaceDisguise Datasets):研究者未来可以利用这两个数据库训练深度学习网络探测面部关键点。
包括面部表情分类、面部对齐、视频中的人脸追踪等一系列面部关键点技术的应用近年来越发收到重视。
方法可以主要总结为两类: 第一类使用特征提取算法,如Gabor -- 提取具有纹理和基于形状的特征以检测不同的面部关键点;第二类方法利用概率图形模型来捕获像素和特征之间的关系来检测面部关键点。
深度网络在不同计算机视觉任务中的优越性能,促使了使用深度网络进行面部关键点检测的研究。
但深度网络在该领域的应用是具有挑战性的,原因之一就是训练深度网络网络所需的标记数据的数量不足,因此设计者必须使用迁移学习。迁移学习通常表现良好,但也会由于训练数据量的不足,难以精调预先训练的深度网络,导致表现不尽如人意。
本文介绍了一种面部关键点的检测框架,用于识别伪装的人脸。
该框架首先使用深度卷积网络来检测14个面部关键点,如图1所示,这被认为是面部识别的必要条件。然后将检测到的点连接以形成星形网状结构(图2)。
分类框架根据星状网络的连接方向进行面部身份识别。本文还介绍了两个乙标注的面部伪装数据集,以提高依赖于大型训练数据集的深度卷积网络。

图1:图左展示出了数据集标注的14个面部关键点。 描述如下:眼睛区域(青色):P1-左眼眉外角,P2-左眉眉内角,P3-右眉内角,P4-右眉外角,P5-左眼外角,P6-左眼中心,P7-左眼内角,P8-右眼内角,P9-右眼中心,P10-右眼外角; 鼻子区域(黄色):P11鼻子; 唇部区域(绿色)P12-唇部左角,P13-唇部中心,P14-唇部右角。右图是部分面部关键点的特写。
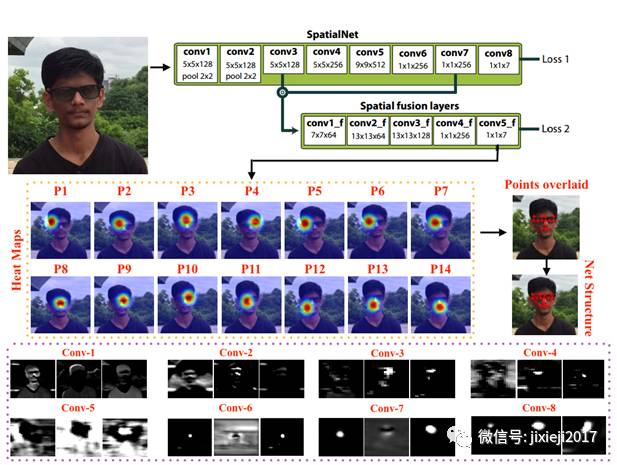
图2:关键点检测流程:该图显示了由空间融合卷积网络以热图形式生成的所有P1-P14关键点的位置。 该图还显示了通过连接关键点形成的网状结构。还显示了8个卷积基层的激活图像。
论文分为以下几个部分:先介绍本文的数据集,再介绍我们提出的伪装人脸识别(DFI)框架,接着介绍对比实验结果 。
▍简单和复杂的面部伪装数据集
现在常用的人脸伪装数据库(小型数据集:AR(http://www2.ece.ohio-state.edu/~aleix/ARdatabase.html)和耶鲁人脸数据库(http://vision.ucsd.edu/content/yale-face-database))仅包含有限的人脸伪装变化,例如围巾和/或太阳眼镜。
训练深度学习网络需要大量图像,包括像眼镜,胡子,不同发型和围巾或帽子的各种伪装组合。
因此,我们提供简单和复杂的两个了分别含有2000张图像的人脸伪装(FG)数据集,每个图像都具有(i)简单和(ii)复杂的背景,并包含具有多种伪装形式,覆盖不同背景和不同照明环境。
每个数据集(简单和复杂)都是由年龄在18岁到30岁之间的男性和女性受试者的2000张图像组成的。
数据集收集了在8个不同的背景,25个主题和10类不同的伪装下的图像。数据集中的伪装包括:(i)太阳眼镜(ii)帽子(iii)围巾(iv)胡须(v)眼镜和帽子(vi)眼镜和围巾(vii)眼镜和胡须(viii)帽和围巾(ix)帽子和胡子(x)帽子,眼镜和围巾10种。数据集的图像如图3所示。

图3:该图显示了简单和复杂人脸伪装(FG)数据集中不同的伪装类型。 从图像中可以看出,复杂背景数据集的样本具有相对复杂的背景。
▍伪装人脸识别 (DIC) 框架
这部分将介绍伪装人脸识别(DisguisedFace Identification)框架。
DIC框架首先使用空间融合卷积网络检测14个面部关键点,空间融合卷积网络通过利用来自密集光流(dense opticalflow)的轨道,在时间上向前和向后的弯曲来预测,将所有相邻帧的面部关键点对准到特定帧。
对于特定帧的置信度由一组来自临近帧的“专家视点”(相应的置信度)增强,从而可以准确预估面部关键点。这使得空间融合卷积网络的预测比其他深度网络更准确。 识别点点连接形成星状网络结构,如图2所示。接下来,识别点将被用来进行分类。
▍面部关键点检测
DIC框架的关键点检测部分使用了空间融合卷积网络进行检测。 面部关键点检测问题可以视为用空间融合卷积网络建模的回归问题。
CNN(卷积神经网络)扫描图像并输出每个关键点的像素坐标。 最后的卷积层(conv-8)输出i×j×k维立方结构(这里64×64×14k = 14个关键点)。
训练目标是使用可用的训练集D =(x,y)估量网络权重参数λ,并且回归(conv8输出)为:
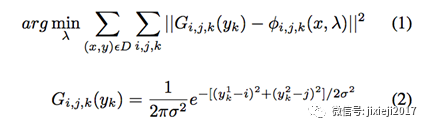
以yk 为中心呈高斯分布。
真实的标签通过在真实键点位置(x,y)处设置具有固定方差的高斯分布合成每个关键点的热图。 l2损失惩罚了预测的热图和地面真实热图之间的像素平方差的平方。我们使用MATLAB中的MatConvNet来训练和验证融合卷积网络。
为了在人脸上形成网状结构,如图4所示,连接起由上述网络产生的位置。
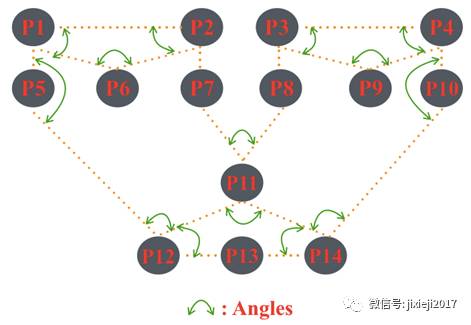
图4:人脸分类:该图显示了面部关键点连接形成网络星型结构的方式。 此结构的角度稍后用于执行面部识别。
▍伪装面部分类
在这部分中,我们将一个伪装的人脸与5个非伪装的不同人脸进行比较。如果对于相同人物,其伪装图像和非伪装图像间τ是最小的,则分类被认为是准确的。
通过计算使用网络结构获得的不同关估算方向之间的L1规范,来估计伪装与非伪装的相似性。在网状结构中,如图4所示,鼻部是要测量的各种角度的参考点。
相似度可以根据下列公式计算:
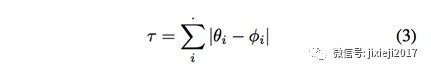
其中τ是相似度,θi表示伪装图像的第i个关键点的方向,并且φi表示非伪影像中的相应角度。
▍实验结果
本节介绍了针对对两个数据集,即:(i)简单背景下的人脸伪装伪装(FG)数据集(ii)复杂背景的人脸伪装(FG)数据集,使用面部伪装识别(DFI)框架。
接下来将描述DFI框架下训练关键点检测空间融合网络,用来评估网络有效性。还将介绍和其他面部关键点检测的深度网络层的比较,和DFI框架分类于应用不同的面部伪装以及与现有技术的比较。
空间融合卷积神经网络的训练
我们从伪装面部数据库中(简单和复杂数据库单独)随机选择了1000个训练图像,500个验证图像和500个测试图像来训练空间融合CNN。
使用批量大小20对网络进行了90次迭代训练。每个输入图像随机裁剪为248×248子图像。 裁剪的部分随机翻转,再随机旋转-40°和+ 40°之间,并在输入网络进行训练之前重新调整为256×256。 输出热图大小为64×64,高斯方差设为1.5。
基础学习率为10-5,20次迭代后减少到10-6。 动量设为0.9。
关键点检测表现
我们分析了两个数据集中提出的伪装人脸识别(DFI)框架的利用空间融合网络关键点检测模块的性能。通过将检测到的关键点的坐标与其在标注数据集中的实际值进行比较来评估模块的性能。
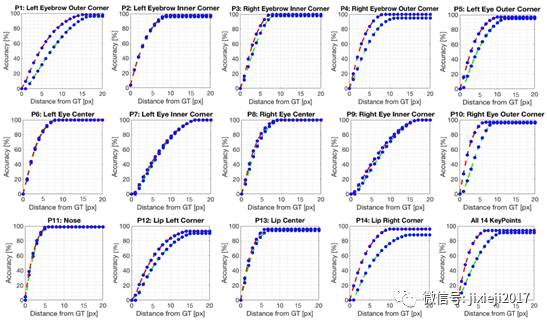
图5:该图显示了简单和复杂的人脸伪装(FG)数据集的所有P1-P14面部关键点的关键点检测性能图。 绿色表示在复杂数据集上计算的关键点精度,而红色代表简单数据集上的精度。
我们以图形的形式呈现了利用空间融合网络关键点检测的性能,该图绘制了距离真实值像素的距离和准确度两个维度,如果关键点位于以真实点像素距离为d的半径内,则认为挂件点的识别是准确的。
对于每个关键点绘制简单(红色)和复杂(绿色)背景的伪装数据集的关键点检测性能,如图5所示。我们可以看出,检测精度随着与真实点的距离增加而提高。
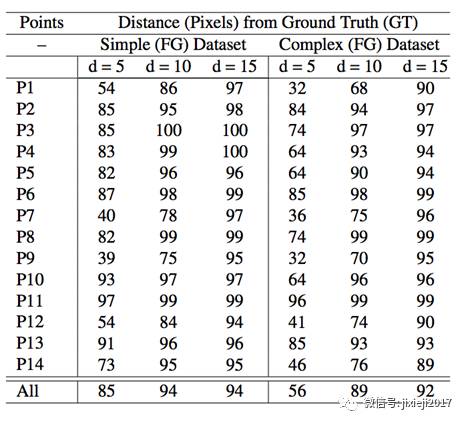
表1提供了两个数据集距离真实点3种距离(d = 5,10,15)的预测关键点的定量比较。如d = 5所示,简单背景数据集的平均关键点检测精度为85%,而复杂背景数据集的准确度为74%。随着距真实点像素距离的增加,两个数据集的精度都会提高。
在复杂数据集上较差的表现可能由于背景的干扰,网络在人脸外部区域检测关键点失败,如图6所示。
仔细观察,在复杂数据集相同像素距离下,外面部关键点P1,P4,P5,P10,P12,P14的精度要比内面部关键点P2,P3,P6,P7,P8,P9, P11低。例如,对于复杂背景数据集,点P1显示出较低的准确度为32%,68%和90%,而简单背景数据集中的准确度为96%,99%和99%。图7中页可以看到上述现象。

图6:该图显示了从复合背景数据集中选择的图像样本中使用DFI框架中的空间融合网络捕获的关键点和网络结构。 第一行包括5个作为网络输入的意思,第二行显示检测到的面部关键点,而第三行由通过连接不同关键点形成的网络结构的表示组成。

图7:外面部关键点分析:显示了简单和复杂的FG数据集以及检测到的关键点以及网络星型结构的两个样本图像。 从示例中可以看出,DIC框架在简单数据集中能更精确地捕获外面部区域关键点(P1,P4,P5,P10,P11,P13)。
▍根据面部区域分析关键点识别表现
背景对于对于眼睛的外部区域的影响,即P1,P4,P5和P10来说是显着的。 鼻子的关键点监测并未收到背景的影响。嘴唇周边P12,P14收到了背景的严重影响,P13的检测表现在简单数据集和复杂数据集中表现相同,未收背景干扰。
面部要点检测:多人
我们分析模型对包含多个人脸的图像识别的性能。由于我们的模型是仅对包含一个混乱背景的人的图像进行了培训,所以我们使用viola jones 面部检测器首先从给定的图像中找到多个面孔。
再将DIC框架用于每个面部提取关键点,如图8所示。图像中2张人脸的针对简单和复杂数据集的关键点检测分类性能分别为80%和50% ,而3张脸分别为76%和43%。 与单个人脸的在简单和复杂背景数据集的85%和56%的关键点检测性能相比,精度有所降低。

图8:图中显示了使用DIC框架中的空间融合网络模块捕获的关键点和网络结构,用于识别图像中的多个人。
与其他关键点识别架构的比较
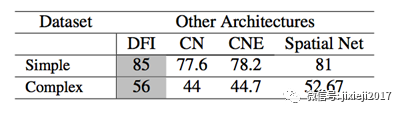
我们将本文中使用的空间融合卷积网络与各种其他架构的关键点检测技术的性能进行比较,如表2所示。我们考虑了3种结构体系,即坐标网络(CN),坐标网络扩展(CNE)和空间网络 。
针对上述架构 的关键点检测精度,提供给d = 5的距离的简单背景人脸伪装数据集和复杂人脸伪装数据集。分析了CN,CNE,SpatialNet和Spa-8网络在简单背景下的关键点检测精度结果分别为77.6%,78.2%,81%和85%。
空间融合网络大幅度优于其他网络。复杂背景面对伪装数据集的分类结果分别为SpatialNet和Spatial Fusion网络的44%,44.7%,52.67%和56%。当背景混乱时,精度急剧下降。
表2:比较坐标网络(CN),坐标扩展(CNE),空间网络和空间融合(DFI)在简单和复杂数据集人脸伪装识别的分类精度(%) 。
其他比较
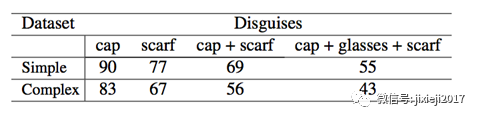
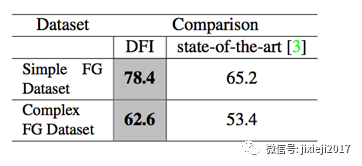
从表中可以看出,伪装分类表现随着伪装的复杂性的增加而降低。
将伪装人脸识别表现与最先进的伪装人脸识别方法相比较:本文提出的方法分别超过13%和9%
Paper:https://arxiv.org/pdf/1708.09317.pdf
编译:北辰
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang



