【论文】NAACL2019 抽取式摘要之 SUMO
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要13分钟
跟随小博主,每天进步一丢丢


论文题目:Single Document Summarization as Tree Induction
论文作者:Yang Liu, Ivan Titov and Mirella Lapata.
下载链接:https://www.aclweb.org/anthology/N19-1173.pdf
代码:https://github. com/nlpyang/SUMO.
来源:NAACL 2019
分类:NLP / 文本摘要 / 抽取式摘要
太长不看版
本文提出了一种端到端的抽取式文本摘要模型(Structured Summarization Model, SUMO),将单文档抽取式摘要看作一个树归纳问题。
将输入文档归纳为一个多根树,每个树根是组成摘要的句子,树根的子树则是与树根的摘要句内容相关或者解释摘要句的句子。
通过不断迭代细化逐渐构成树🌲。
主要思想
本文将单文档抽取式摘要问题定义为树归纳(tree induction)问题。
以前的方法依赖于语言驱动的文档表示来生成摘要,我们的模型在预测输出摘要时引入了一个多根依赖树。树中的每个根节点都是一个摘要句,其附属的子树是内容与摘要句相关或解释摘要句的句子。
我们设计了一种新的迭代改进算法:通过反复细化先前迭代预测的结构来逐渐生成树。我们在两个基准数据集上进行了实验,证明了我们的summarizer可以与最先进的方法相媲美。
1.问题定义
传统的抽取式摘要的方法常常是类似于序列标注顺序的为句子打分,缺点:
没有考虑文档的结构,而这部分的信息很重要。
缺乏可解释性,虽然能够识别摘要句,但却不能使它们的预测合理化。
文档及其对应树的示例如图1所示;节点对应文档句子,蓝色节点表示应该在摘要中的句子,白色节点与其父摘要语句相关或包含。

本文提出了一个新的框架,使用结构化注意力(Kim et al., 2017)同时作为抽取式摘要的目标和注意力权重。模型是端到端训练的,它在预测输出摘要时引入文档级依赖树,并通过帮助解释文档内容如何有助于模型的决策,在摘要过程中带来更多的可解释性。
贡献:
提出了一种新的概念:将抽取式摘要看成树归纳问题。
利用结构化注意(structured attention),基于迭代结构改进方法,来学习文档表示;
大规模的评估研究表明,我们的方法在与最先进的方法可比的同时,能够使模型预测合理化。
2.模型结构
2.1. baseline
本文baseline是传统的序列二分类(Zhang et al., 2018; Dong et al., 2018; Nallapati et al.,2017; Cheng and Lapata, 2016)使用交叉熵loss;encoder由sentence-level Transformer (TS) 和document-level Transformer (TD)构成,都是相同的结构,使用Transformer architecture(Vaswani et al., 2017)。
其中Transformer包含N个相同的层,每个层有两个子层:
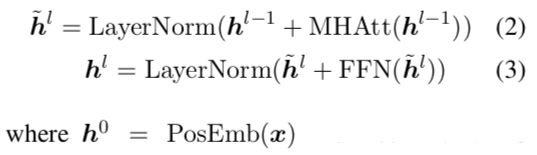
其中FFN是两层前馈神经网络+ReLU。
句子表示的计算方式:word过TS然后进行weighted-pooling。如下。
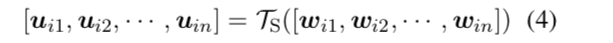
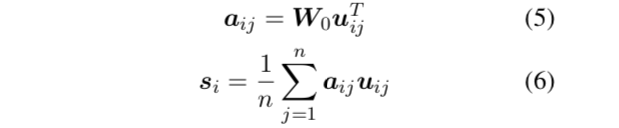
接下来融合文档信息,最后使用sigmoid进行二分类。
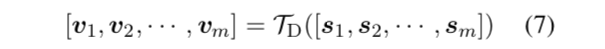
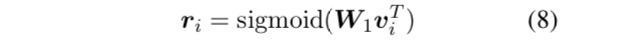
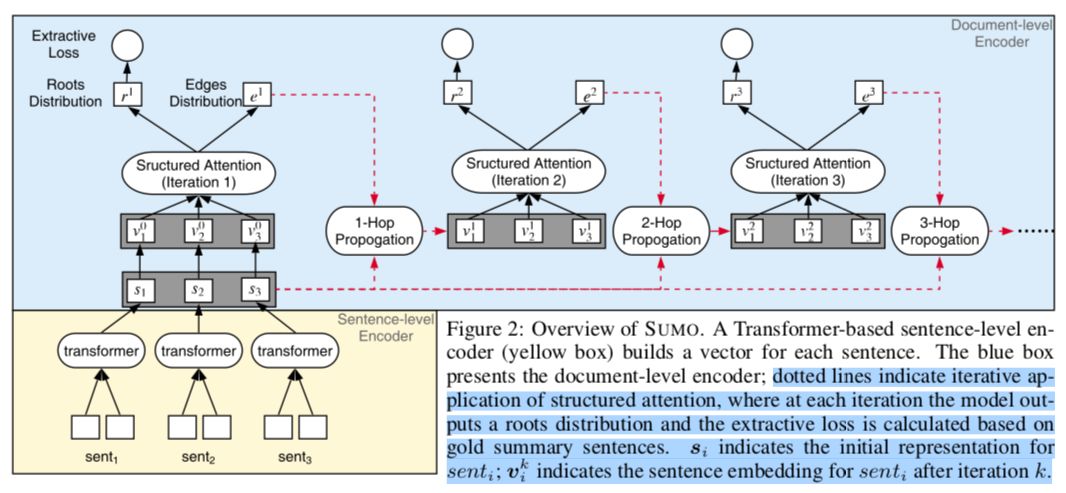
2.2. Structured Summarization Model
在baseline的Transformer模型中,使用基于softmax的multi-head attention对句子间的关系进行建模,但这只捕获了浅层结构信息。我们的摘要模型SUMO (Structured Summarization Model),它将句子分为有摘要价值的和没有摘要价值的,同时将源文档的结构归纳为一个多根树。
该模型与baseline的Transformer model具有相同的sentence-level encoder(TS)(图2的底部框),但在doc-level encoder上两个重要方面有所不同:
使用结构化注意力(structured attention)来建模底层树的根(总结句)(见图2蓝框);
通过迭代改进,从过去的猜测中逐步推断出更复杂的结构(参见图2上的区块)。
1)Structured Attention
得到文档句子编码si后,SUMO首先计算句子 senti 的非归一化的根得分(unnormalized root score) ri ,作为句子 senti 在文档树中被选择为根的程度。(9)
接着计算了句子对⟨senti , sentj ⟩的非归一化得分ẽij,作为树中句子 senti 可能成为 sentj 的父亲的程度。(如图2蓝区块所示)(10)
为了引入结构偏差,SUMO将这些分数规范化为在文档依赖树中形成边的边缘概率[边缘概率:一件事情发生的概率,不再考虑其他事件]。
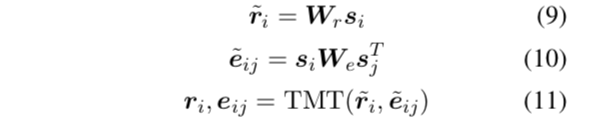
我们用树矩阵定理Tree-Matrix-Theorem (TMT; Koo et al. 2007; Tutte 1984) 计算根边缘概率 ri 和边边缘概率 eij (Liu和Lapata 2017)。TMT算法如下图所示:

Koo et al. (2007) and Liu and Lapata (2017) for more details
与Liu和Lapata(2017)计算单根树的边缘概率不同的是,我们的树有多个根。
2)迭代结构改进
SUMO本质上将摘要简化为一个 rooted-tree parsing问题,然而一次就能精准的预测一棵树是有问题的,如下:
首先,在预测树时,模型只访问根(摘要句)的标签,而子树的连接是潜在存在的且没有明确的训练信号。正如之前的工作(Liu和Lapata, 2017)所表明的,TMT的单一应用会导致浅层的树结构。
其次,计算根分数 r̃ 和边分数 ẽij 将只能基于一阶特性,然而与“兄弟姐妹和孙子” 有关的高阶信息在语篇分析中被证明是有用的。
因此我们使用一个迭代推断潜在树的推理算法来解决这些问题。与多层神经网络结构(如Transformer或RNN)不同,在每一层都根据前一层的输出更新单词表示;我们只在每次迭代中细化树结构,单词表示不会跨多个层传递。
在早期的迭代中,模型学习浅层和简单的树,信息主要在邻近节点之间传播;随着结构变得更精细,信息在全局范围内传播得更多,从而允许模型学习更高阶的特性。算法2提供了我们细化过程的细节(注意456行是前文提到的structure-attention):


该算法中的 ek 表示边(子树)的信息,用在迭代中信息的保存,可以更好的计算根节点;rk 表示根(摘要句)。
The k-Hop-Propagation函数类似于图卷积网络GCNs中的计算(Kipf Welling, 2017;Marcheggiani Titov, 2017)。GCNs最近已经被应用于潜在树(Corro和Titov, 2019),但是没有与迭代细化相结合。
训练时,我们将模型的损失函数定义为所有迭代的损失之和:
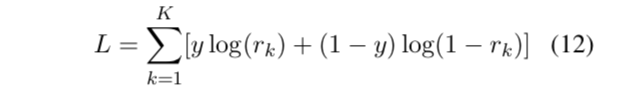
测试时,SUMO使用顶层的根概率作为总结句的分数,对于每篇文章都生成三句摘要句。
3.实验
3.1 Summarization Datasets
两个基准数据集:
the CNN/DailyMail news highlights dataset (Hermann et al., 2015);
包含新闻文章和相关的摘要。使用Hermann(2015)的标准分割进行训练、验证和测试(90,266/1,220/1,093 CNN和196,961/12,148/10,397 DailyMail),非匿名实体。
the New York Times Annotated Corpus (NYT; Sandhaus 2008).
包含110,540篇文章和摘要。根据发布日期分为100,834个训练和9,706个测试样本Durrett(2016)。还遵循了他们的过滤过程,删除了短于50个单词的摘要的文档。
3.2 Implementation Details
The vocabulary size = 30K.
300D word embeddings which were initialized randomly from N (0, 0.01).
The sentence-level Transformer has 6 layers and the hidden size of FFN = 512.
The number of heads in MHAtt = 4.
Adam was used for training (β1 = 0.9, β2 = 0.999).
learning rate schedule from Vaswani. (2017) with warming-up on the first 8,000 steps.
SUMO and related Transformer models produced 3-sentence summaries for each doc at test time (for both CNN/DailyMail and NYT datasets).
3.3. Automatic Evaluation
我们使用ROUGE F1 (Lin, 2004)对摘要质量进行了评估。ROUGE-1和ROUGE-2 评估信息性,最长公共子序列 ROUGE-L 评估流利性。
我们实验了SUMO的两种变体,一种是一层structure attention,另一种是三层。表1展示实验结果。
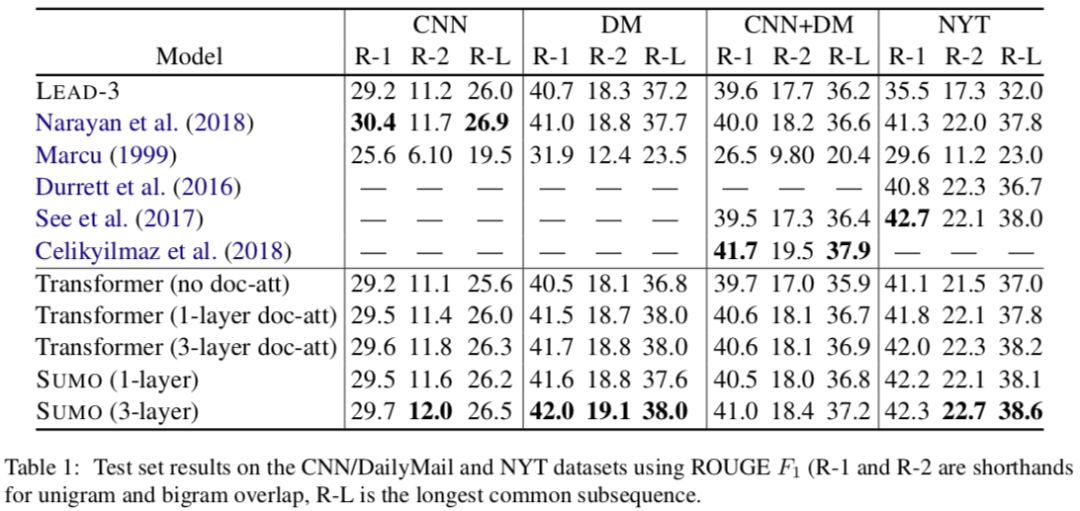
我们观察拥有三层结构化attention的SUMO表现最好,这证实了我们的假设,即文档结构有利于摘要的抽取。表1中的结果还显示SUMO和所有基于Transformer模型的文档注意(doc-att: document-level self-attention)的性能都优于LEAD-3。SUMO(3层)比最先进的方法更有竞争力。SUMO优于Marcu(1999),尽管后者使用了语言上的文档表示。
其中:
REFRESH (Narayan et al.)是一个通过全局优化ROUGE和增强学习的抽取式摘要系统。
Marcu(1999)是另一个基于RST解析的抽取式摘要器。它利用语篇结构和核概念对句子进行重要性评分,并选取最重要的句子作为总结。我们对Marcu(1999)的重新实现使用了Zhao和Huang(2017)的解析器来获得RST树。
Durrett(2016)开发了一个集成了语法一致性和一致性的压缩模型的摘要系统。
See(2017)提出了一种基于编解码器架构的抽象摘要系统。
Celikyilmaz(2018)是生成式摘要的state-of-the-art,使用了多个agents来表示文档以及使用agents进行解码的分层注意机制。
3.4. Human Evaluation
按照问答范式来对摘要从文档中保留关键信息的程度进行评分,我们基于gold summary创建了一组问题,假设它突出了最重要的文档内容。然后,检查参与者是否能够只通过系统输出的摘要来回答这些问题。系统输出摘要能够回答的问题越多,就越能更好地概括整个文档。我们从CNN/DailyMail和NYT的数据集中随机选择了20个文档,分别为每个gold summary写了多个问答对。一共出了71道题,每道题从2道到6道不等。我们要求参与者只阅读摘要并尽可能回答所有相关问题,不需要阅读原始文档或gold summary。
我们采用了与Clarke和Lapata(2010)相同的评分机制,即一个正确的答案被标记为1分,部分正确的答案被标记为0.5分,否则为0分。参与者要评估由LEAD-3、我们的3层SUMO模型和多个最先进的系统生成的摘要。
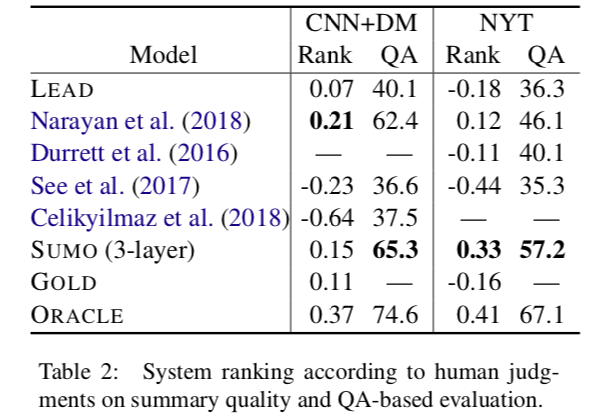
表2 (QA列)给出了基于QA的评估结果。根据SUMO的summary,参赛者在CNN/DailyMail上的正确率为65.3%,在NYT上的正确率为57.2%。
(RANK列)评估了总结的总体质量,要求参与者根据以下标准对summary进行排序:信息量、流利性和简洁性。这项研究是在Amazon Mechanical Turk platform 上进行的,使用的是Best-Worst 度量(Louviere et al.,2015),这是一种比成对比较更省力的方法,已经被证明比评分量表产生更可靠的结果(Kiritchenko and Mohammad, 2017)。
参与者被出示了一份来自7个系统中3个系统的文章和摘要,并根据上面提到的标准来决定哪一个摘要更好,哪一个更差。每个系统的评分是用它被选为最佳的次数减去它被选为最差的次数的百分比来计算的。评分范围从-1(最差)到1(最好)。如表2 (Rank列)所示,我们可以发现绝大多数参与者更喜欢SUMO和REFRESH (Narayan et al.,2018)。
4.结论
在这篇论文中,我们提供了一个新的视角,将抽取式摘要概念化为一个树归纳问题。
我们提出了SUMO,该模型将一个文档变为多根依赖树,其中根是有摘要价值的句子,而附加在根上的子树是阐述或解释摘要内容的句子。SUMO使用在以前的迭代中学习到的信息,通过迭代细化过程构建潜在结构,从而生成复杂的树。在两个数据集上进行的实验表明,SUMO与最先进的方法相比具有竞争力,并能归纳出有意义的树结构。
在未来,我们希望将SUMO可以用在生成式摘要上(即学习文档和句子的潜在结构)并可以在弱监督的环境下进行实验,虽然没有摘要,但可以从文章的标题或主题推断出标签。
译者:西柚媛
编辑:西柚媛






