GAIL(Imitating driver behavior with GAN)
论文:https://arxiv.org/pdf/1701.06699.pdf
摘要:
精确预测和仿真人们驾驶行为在人工智能系统中尤为重要。传统模型采用简单的参数化模型和行为克隆。论文提出了一个新的方法来解决先验分布中的连续误差问题,可以使得在存在扰动的情况下的行为变得更加具有鲁棒性。
论文提出了Generative Adversarial Imitation Learning 用于训练循环策略,GAIL表现比基于规则的控制器和优异,并且可以在一个真实的高速仿真环境下最大化 likelihood。GAIL可以同时基于人类驾驶员的应急反应产生行为,也可以长时间保持控制。
介绍:
人类驾驶模型(基于人的驾驶习惯模型)针对与规则和数据导向,imitation learning(IL)基于神经网络相对于规则系统有更少的参数behavior-cloning(BC)将模仿学习看做一个监督学习问题,用于拟合专家数据。BC在仿真情况下精度不满足要求,Inverse reinfor-cement learning (IRL)假设专家在优化策略时,不知道奖励函数。由于IRL在计算上要求非常巨大,论文采用通过直接优化策略而模仿专家行为,不第一时间学习价值函数。
论文的主要工作:① 论文提出使用GAIL优化循环神经网络(RNN),RNN的使用时,策略表现比使用前向传播优异。② 论文使用GAIL进行了道路仿真,专家指令由真实的人类行为给定。论文提出使用LIDAR数据进行映射分析,并实验。
策略表示:
论文提出策略表示需要满足以下三个条件:① 非线性 ② 高维度 ③ 随机性 。非线性和高维度,论文使用神经网络满足要求,随机性,论文使用添加一个随机高斯分布如图所示:神经网络的输出 μ 和 logv 共同组成该高斯分布。
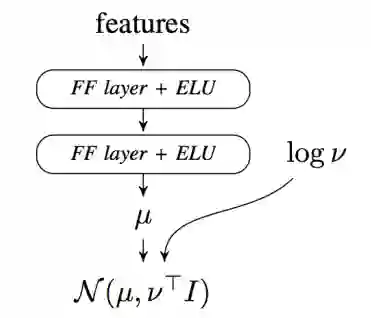
前馈神经网络直接映射输入和输出,最常用的结构是多层感知机 multilayer perceptrons (MLP),由相互联系的层之间的权重和元素之间的非线性因素组成。
MLP在完全展示探索环境时,具有限制性,论文使用循环策略Gated Recurrent Unit(GRU),该网络参数少,表现优异。
策略优化:
Trust Region Policy Optimization(TRPO):TRPO通过一个优化限制来更新策略参数来保证策略在一个单步更新中不会改变太多,进而限制噪声所造成的影响。但是TRPO同样需要一个精确的奖励方程,该方程又很难得到,所以论文提出了下述GAIL算法。
Generative Adversarial Imitation Learning(GAIL):GAIL训练出一个策略,该策略表现的像专家的策略一样,然后来欺骗分类器,该分类器用于分辨专家策略和训练出来的策略(有点像GAN的思路,一个生成器,一个辨别器,两者博弈直到辨别器不能分辨真实数据和生成数据为止)。算法方程如下:
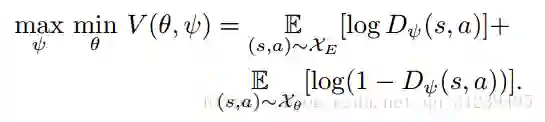
最终价值函数方程如下:
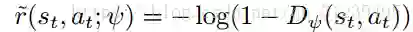
该价值函数方程用于不断的近似表示真实的价值函数方程。如下图所示:
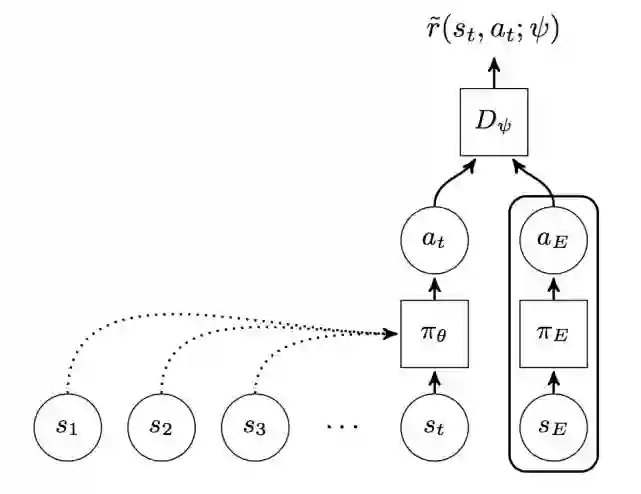
实验结果:
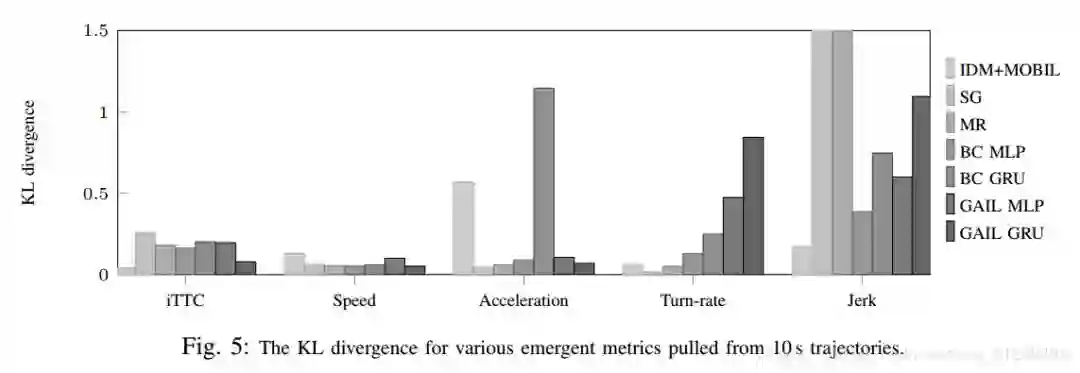
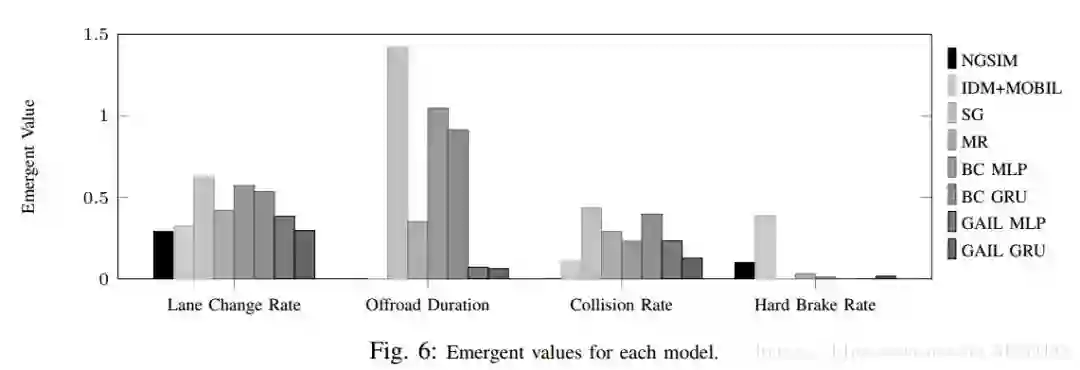
博客链接:https://blog.csdn.net/qq_31239495/article/details/82980773
欢迎指正


