【学界】CVPR 2019 论文大盘点—目标检测篇
来源:极市平台
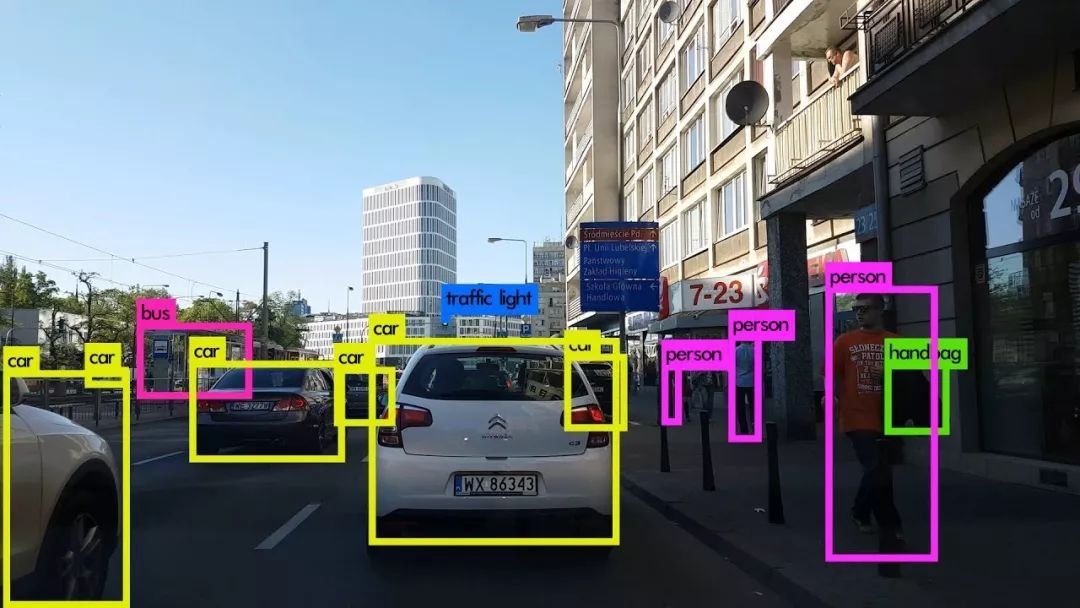
本文盘点了CVPR 2019 所有有关目标检测的文章,并简单做了分类。总计 56 篇,绝大多数含开源代码,很多已经被大家所熟悉,比如KL-Loss、ScratchDet、ExtremeNet、NAS-FPN、GIoU 等。
可以在以下网站下载这些论文:
http://openaccess.thecvf.com/CVPR2019.py
如果想要下载所有CVPR 2019 论文,请点击这里:
CVPR2019最全整理:全部论文下载,Github源码汇总、直播视频、论文解读等
更多论文盘点:
二阶段算法
提出了一种新的边界框回归损失,同时学习边界框变换和定位差异
卡耐基梅隆大学、旷视
Bounding Box Regression with Uncertainty for Accurate Object Detection
Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang
https://github.com/yihui-he/KL-Loss
将 balanced 概念应用到 IoU 检测候选框、特征融合、损失计算三个方面
浙江大学、商汤科技、香港中文大学、悉尼大学
Libra R-CNN: Towards Balanced Learning for Object Detection
Jiangmiao Pang, Kai Chen, Jianping Shi, Huajun Feng, Wanli Ouyang,
Dahua Lin
https://github.com/OceanPang/Libra_R-CNN
一种新的 Reasoning-RCNN,其利用人类的各种常识知识,赋予任何检测网络对所有目标区域进行自适应全局推理的能力
华为诺亚方舟实验室、中山大学
Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale
Object Detection
Hang Xu, ChenHan Jiang, Xiaodan Liang, Liang Lin, Zhenguo Li
https://github.com/chanyn/Reasoning-RCNN
提出了一种可扩展的并行化方法来实现区域候选框中的 NMS
新加坡南洋理工大学
MaxpoolNMS:GettingRid of NMS Bottlenecks in Two-Stage Object
Detectors
Lile Cai, Bin Zhao, Zhe Wang, Jie Lin, Chuan Sheng Foo, Mohamed Sabry
Aly, Vijay Chandrasekhar
提出一个 RoI Transformer 的模块,实现对有向和密集填充对象的检测
武汉大学
Learning RoI Transformer for Oriented Object Detection in Aerial Images
Jian Ding, Nan Xue, Yang Long, Gui-Song Xia, Qikai Lu
一阶段算法
一种从零开始训练的目标探测器 ScratchDet,充分利用原始图像信息的 Root-ResNet,结合 ResNet 与 VGGNet 加强对小目标的检测
京东 AI 研究院、中国科学院、中山大学
ScratchDet: Training Single-Shot Object Detectors from Scratch
Rui Zhu, Shifeng Zhang, Xiaobo Wang, Longyin Wen, Hailin Shi, Liefeng Bo, Tao Me
https://github.com/KimSoybean/ScratchDet
提出 ExtremeNet,一个自底向上的对象检测框架,它检测对象的四个极端点(最顶部、最左侧、最底部、最右侧)
UT Austin
Bottom-up Object Detection by Grouping Extreme and Center Points
Xingyi Zhou, Jiacheng Zhuo, Philipp Krähenbühl
https://github.com/xingyizhou/ExtremeNet
提出一种新目标检测框架来处理类不平衡问题,一种 error-driven 学习算法优化了基于 AP 不可微非凸目标函数
上海交通大学、中国 Intel Labs、马来西亚多媒体大学、腾讯 YOUTU
实验室、北京大学
Towards Accurate One-Stage Object Detection with AP-Loss
Kean Chen, Jianguo Li, Weiyao Lin, John See, Ji Wang, Lingyu Duan, Zhibo Chen, Changwei He, Junni Zou
提出了一种简单有效的学习技术,在不影响 YOLO 检测器速度的前提下,显著地改进 YOLO 的 mAP
德黑兰大学、西雅图艾伦人工智能研究所
Assisted Excitation of Activations: A Learning Technique to Improve Object Detectors
Mohammad Mahdi Derakhshani , Saeed Masoudnia , Amir Hossein Shaker , Omid Mersa,Mohammad Amin Sadeghi, Mohammad Rastegari , Babak N. Araabi
anchor-free 算法
基于无 anchor 机制的特征选择,可以结合特征金字塔嵌入到单阶段检测器中,将线特征选择应用于与 anchor 无关的分支的训练上
卡内基梅隆大学
Feature Selective Anchor-Free Module for Single-Shot Object Detection
Chenchen Zhu, Yihui He, Marios Savvides
极市干货|第40期直播回放:诸宸辰-CVPR2019:基于Anchor-free特征选择模块的单阶目标检测
视频目标检测
利用视频或者图片中的动作信息为目标的位置提供线索
南加利福尼亚大学、Facebook AI
Activity Driven Weakly Supervised Object Detection
Zhenheng Yang, Dhruv Mahajan, Deepti Ghadiyaram, Ram Nevatia,
Vignesh Ramanathan
https://github.com/zhenheny/Activity-Driven-Weakly-Supervised-Object-
Detection
显著性目标检测
通过扩大卷积神经网络中的池化的作用解决显著目标检测问题
南开大学、深圳大学
A Simple Pooling-Based Design for Real-Time Salient Object Detection
Jiang-Jiang Liu, Qibin Hou, Ming-Ming Cheng, Jiashi Feng, Jianmin Jiang
https://github.com/backseason/PoolNet
一个新的互动式学习模型(MLM)利用显著目标检测、前景轮廓检测和边缘检测的监督来训练显著性检测网络
A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision
Runmin Wu, Mengyang Feng, Wenlong Guan, Dong Wang, Huchuan Lu,Errui Ding
https://github.com/JosephineRabbit/MLMSNet
将上下文感知金字塔特征提取模块(CPFE)用于多尺度高层次特征映射来获得丰富的上下文特征,重点关注有效的高层次上下文特征和
低层次空间结构特征
哈尔滨工业大学
Pyramid Feature Attention Network for Saliency detection
Ting Zhao, Xiangqian Wu
https://github.com/CaitinZhao/cvpr2019_Pyramid-Feature-Attention-Network-for-Saliency-detection
一种用于显著目标检测的统一框架——迭代式自顶向下和自底向上显著性相结合的过程
南开大学
An Iterative and Cooperative Top-down and Bottom-up Inference Network
for Salient Object Detection
Wenguan Wang, Jianbing Shen, Ming-Ming Cheng, Ling Shao
在基于非深度学习的方法中提出一个对比度损失来利用对比度先验,提出了一种流体金字塔策略更好地利用多尺度交叉模态特征
南开大学
Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object
Detection
Jiaxing Zhao, Yang Cao, Deng-Ping Fan, Xuan-Yi Li, Le Zhang, Ming-Ming Cheng
https://github.com/JXingZhao/ContrastPrior
一种新的级联部分解码器框架,抛弃较浅层的特征,对较深层的特征进行细化
中国科学院计算机科学与技术学院、大数据挖掘与知识管理重点实验
室、国科学院计算技术研究所
Cascaded Partial Decoder for Fast and Accurate Salient Object Detection
Zhe Wu, Li Su, and Qingming Huang
https://github.com/wuzhe71/CPD
利用标题作为辅助语义任务,在复杂场景中增强显著性目标检测
大连理工大学、Adobe 研究所、海军航空大学
CapSal: Leveraging Captioning to Boost Semantics for Salient ObjectDetection
Lu Zhang, Jianming Zhang, Zhe Lin, Huchuan Lu, You He
由一个深度监督的编解码器和一个残差细化模块组成新的边界感知显著性目标检测网络 BASNet
加拿大阿尔伯塔大学
BASNet: Boundary-Aware Salient Object Detection
Xuebin Qin, Zichen Zhang, Chenyang Huang, Chao Gao, Masood Dehghan,
Martin Jagersand
https://github.com/NathanUA/BASNet
视频显著性检测
收集大型的 DAVSOD 数据库,提出一个 SSAV 基础网模型,其通过一个具有显著性位移感知的 LSTM 模型来预测视频的显著性
南开大学、Inception Institute of Artificial Intelligence、北京理工大学
Shifting More Attention to Video Salient Objection Detection
Deng-Ping Fan, Wenguan Wang, Ming-Ming Cheng, Jianbing Shen
https://github.com/DengPingFan/DAVSOD
3D目标检测
一种充分利用立体图像中稀疏、密集、语义和几何信息的自动驾驶三维目标检测方法,以同时检测和关联对象在左图像和右图像。通过使
用左右 RoI 的基于区域的光度对准来恢复精确的 3D 边界框
DJI 大疆、香港科技大学
Stereo R-CNN based 3D Object Detection for Autonomous Driving
Peiliang Li, Xiaozhi Chen, Shaojie Shen
https://github.com/HKUST-Aerial Robotics/Stereo-RCNN
一种度量精确的端到端单目三维目标检测和形状检索的深度学习方法。提出了一种新的损失公式,将二维检测、定位和尺度估计提升到三维空间
慕尼黑工业大学、丰田研究院、
Monocular Lifting of 2D Detection to 6D Pose and Metric Shape
Fabian Manhardt, Wadim Kehl, Adrien Gaidon
一种单目三维目标检测方法 MonoPSR,使用精确的目标域减少搜索空间
多伦多大学
Monocular 3D Object Detection Leveraging Accurate Proposals and Shape
Reconstruction
Jason Ku, Alex D. Pon, Steven L. Waslander
一种用于单目三维目标检测的深度拟合度评分网络
清华大学、中国智能技术与系统国家重点实验室、国家信息科学技术
研究中心、华为诺亚方舟实验室
Deep Fitting Degree Scoring Network for Monocular 3D Object Detection
Lijie Liu, Jiwen Lu, Chunjing Xu, Qi Tian, Jie Zhou
提出了一种基于点云的三维目标检测方法 PointRCNN
香港中文大学
PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud
Shaoshuai Shi, Xiaogang Wang, Hongsheng Li
https://github.com/sshaoshuai/PointRCNN
提出了一种基于单个 RGB 图像的自动驾驶场景下的高效三维目标检测框架
香港中文大学、商汤科技、悉尼大学、北京航空航天大学
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
Buyu Li, Wanli Ouyang, Lu Sheng, Xingyu Zeng, Xiaogang Wang
提出利用多个相关任务来实现精确的多传感器三维目标检测。提出一种新的多传感器融合结构,实现了完全融合的特征表示
Uber、多伦多大学
Multi-Task Multi-Sensor Fusion for 3D Object Detection
Ming Liang, Bin Yang, Yun Chen, Rui Hu, Raquel Urtasun
一种用于立体图像三维目标检测的立体三角学习网络(TLNet),不需要计算像素级深度图,可以很容易地集成到单目检测器中
清华大学、微软研究院
Triangulation Learning Network: From Monocular to Stereo 3D Object
Detection
Zengyi Qin, Jinglu Wang, Yan Lu
将基于图像的深度映射转换为 pseudo-lidar 表示
康奈尔大学
Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D
Object Detection for Autonomous Driving
Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
提出了一种有效的端到端学习概率三维目标检测器的方法。
Uber
LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
Gregory P. Meyer, Ankit Laddha, Eric Kee, Carlos Vallespi-Gonzalez, Carl
K. Wellington
域自适应方法
一种用于目标检测的无监督域自适应方法,由 DD(Domain
Diversification)和 MRL(Multidomain-invariant Representation Learning)
两阶段组成
韩国先进科学技术学院
Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection
Taekyung Kim, Minki Jeong, Seunghyeon Kim, Seokeon Choi, Changick Kim
解决了现有目标检测器对新目标域的无监督自适应问题
Massachusetts Amherst 学校
Automatic adaptation of object detectors to new domains using self-training
Aruni RoyChowdhury Prithvijit Chakrabarty Ashish Singh SouYoung Jin Huaizu Jiang Liangliang Cao Erik Learned-Miller
http://vis-www.cs.umass.edu/ unsupVideo/
人脸检测
一种新的表示攻击检测方法
西班牙 Alcala 大学
Deep Anomaly Detection for Generalized Face Anti-Spoofing
Daniel Pérez-Cabo, David Jiménez-Cabello, Artur Costa-Pazo, Roberto J. López-Sastre
https://gitlab.idiap.ch/bob/bob.pad.face/
https://github.com/zboulkenafet/Face-antispoofing-based-on-color- texture-analysis
小样本学习
在单一的端到端训练过程中,同时学习主干网络参数、嵌入空间以及该空间中每个训练类别的分布的新 DML 方法,将结构结合到一个标
准的目标检测模型中
IBM 人工智能研究院、特拉维夫大学电气工程学院、德西尼昂计算机科学系
RepMet: Representative-based metric learning for classification and few-
shot object detection
Leonid Karlinsky, Joseph Shtok, Sivan Harary, Eli Schwartz, Amit Aides, Rogerio Feris, Raja Giryes, Alex M. Bronstein
引入配对机制,提出一种双级模块,使训练检测器适应目标域
新加坡国立大学、华为诺亚方舟实验室
Few-shot Adaptive Faster R-CNN
Tao Wang, Xiaopeng Zhang, Li Yuan, Jiashi Feng
运动目标检测
针对多线性低秩框架下运动目标检测问题,解决了光照和目标位置的
不连续变化问题
阿尔伯塔大学
Moving Object Detection under Discontinuous Change in Illumination
Using Tensor Low-Rank and Invariant Sparse Decomposition
Moein Shakeri, Hong Zhang
提出一种用于检测图像中运动目标的对抗性上下文的模型
加州大学洛杉矶分校视觉实验室
Unsupervised Moving Object Detection via Contextual Information Separation
Yanchao Yang, Antonio Loquercio, Davide Scaramuzza, Stefano Soatto
https://github.com/antonilo/unsupervised_detection
多域目标检测
一种高效的通用目标检测系统,能够处理从人脸和交通标志甚至医学图像的各类图像
加州大学圣地亚哥分校
Towards Universal Object Detection by Domain Attention
Xudong Wang, Zhaowei Cai, Dashan Gao, Nuno Vasconcelos
http://www.svcl.ucsd.edu/projects/universal-detection/.
弱监督目标检测
通过平滑损失函数,将一个复杂的优化问题转化为多个较简单的子问题,转化为多个实例学习,从而产生连续多实例学习(continuous
multiple instance learning, CMIL)。
中国科学院大学、清华大学、鹏城实验室
C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection
Fang Wan, Chang Liu, Wei Ke, Xiangyang, Jianbin Jiao and Qixiang Ye
http://github.com/Winfrand/C-MIL
使用深层生成模型,即离散 DISCO 网络,对复杂的不可分解的条件分布建模。
IIIT Hyderabad、牛津大学艾伦·图灵学院
Dissimilarity Coefficient based Weakly Supervised Object Detection
Aditya Arun, C.V. Jawahar, M. Pawan Kumar
提出一种利用视频获取高精度弱监督目标检测的新方法
加州大学戴维斯分校
You reap what you sow: Generating High Precision Object Proposals for
Weakly-supervised Object Detection
Krishna Kumar Singh, Yong Jae Lee
https: //github.com/kkanshul/w-rpn
神经架构搜索目标检测
在一个新的可扩展搜索空间中发现了一种新的特征金字塔结构
Google Brain
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Golnaz Ghias, Tsung-Yi Lin, Ruoming Pang, Quoc V. Le
https://github.com/tensorflow/tpu/tree/master/models/official/retinanet
其他
提出新的 GIoU 来代替 L1、L2损失函数,提升 regression 效果
美国斯坦福大学计算机科学系、澳大利亚阿德莱德大学计算机科学学院、美国 Aibee 公司
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, Silvio Savarese
提出一种新的 anchor 生成方法—通过图像特征来指导 anchor 的生成。通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的
anchor
香港中文大学 SenseTime 联合实验室、亚马逊 Rekognition、新加坡南
洋理工大学
Region Proposal by Guided Anchoring
Jiaqi Wang, Kai Chen, Shuo Yang, Chen Change Loy, Dahua Lin
https://github.com/openmmlab/mmdetection
一种新的基于深度学习的在密集的场景中精确目标检测方法
Bar-Ilan University、Tel Aviv University、The Open University of Israel
Precise Detection in Densely Packed Scenes
Eran Goldman, Roei Herzig, Aviv Eisenschtat, Jacob Goldberger, Tal Hassner
www.github.com/eg4000/SKU110K_CVPR19
一种新的 NMS 算法——自适应 NMS 算法有效地处理人群中的行人检测问题,更好地细化拥挤场景中的边界框
北京航空航天大学
Adaptive NMS: Refining Pedestrian Detection in a Crowd
Songtao Liu, Di Huang, Yunhong W
一种计算改进上限的新方法,通过将检测的基本置信度与不同的上下文关系或任何其他类型的附加信息相结合
以色列 Ben-Gurion University
Exploring the Bounds of the Utility of Context for Object Detection
Ehud Barnea, Ohad Ben-Shahar
https://github.com/EhudBarnea/ContextAnalysis
提出一个可用于任何 FCN 来估计目标位置的损失函数(weighted Hausdorff distanc),一种方法不用任何边界框来估计一个图像中物体的位置和数量
Purdue 大学视频与图像处理实验室
Locating Objects Without Bounding Boxes
Javier Ribera, David Guera, Yuhao Chen, Edward J. Delp
https://github.com/javiribera/locating-objects-without-bboxe s
提出了部分感知抽样方法,利用人的直觉对目标之间的层次关系进行识别
Preferred Networks 公司
Sampling Techniques for Large-Scale Object Detection from Sparsely
Annotated Objects
Yusuke Niitani , Takuya Akiba , Tommi Kerola, Toru Ogawa Shotaro Sano, Shuji Suzuki
提出了一种基于位置感知的可变形卷积方法和一种利用深层特征对浅层特征图进行过滤的后向注意过滤模块。
伊利诺斯理工学院
Object detection with location-aware deformable convolution and backward attention filtering
Chen Zhang, Joohee Kim
一种用于人群计数的点监督深度检测网络(PSDDN),在训练阶段对人头进行简单的点级标注,在测试阶段对人头进行精细的边界框信息生成
四川大学、雷恩大学
Point in, Box out: Beyond Counting Persons in Crowds
Yuting Liu , Miaojing Shi, Qijun Zhao, Xiaofang Wang
通过有效的区域挖掘和基于区域的区域对齐,提出一种新的目标检测领域自适应框架
香港中文大学、浙江大学、商汤科技
Adapting Object Detectors via Selective Cross-Domain Alignment
Xinge Zhu, Jiangmiao Pang, Ceyuan Yang, Jianping Sh, Dahua Lin
一种利用近目标特征响应的位置差异来实现细粒度特征模拟的方法
新加坡国立大学、华为诺亚方舟实验室
Distilling Object Detectors with Fine-grained Feature Imitation
Tao Wang, Li Yuan, Xiaopeng Zhang, Jiashi Feng
https://github.com/twangnh/Distilling-Object-Detectors
引入空间感知图关系网络(SGRN)来自适应发现和合并关键的语义和空间关系,用于大规模目标检测
华为诺亚方舟实验室、中山大学
Spatial-aware Graph Relation Network for Large-scale Object Detection
Hang Xu, ChenHan Jiang, Xiaodan Liang, Zhenguo Li
提出一种将图像中所有检测到的目标作为输入,利用 Gated Graph 神经网络对目标假设之间的关系进行建模,从而推断出给定任务的优先对象的新方法
德国波恩大学
What Object Should I Use? - Task Driven Object Detection
Johann Sawatzky, Yaser Souri, Christian Grund Juergen Gall
提出三个有效的改进现有的量化感知微调方案
上海科技大学、商汤科技
Fully Quantized Network for Object Detection
Rundong Li, Yan Wang, Feng Liang, Hongwei Qin, Junjie Yan, Rui Fan
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得

