综述 | 盘点卷积神经网络中的池化操作
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
池化操作(Pooling)是CNN中非常常见的一种操作,池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。
主要功能有以下几点:
-
抑制噪声,降低信息冗余 -
提升模型的尺度不变性、旋转不变形 -
降低模型计算量 -
防止过拟合
一提到池化操作,大部分人第一想到的就是maxpool和avgpool,实际上还有很多种池化操作。
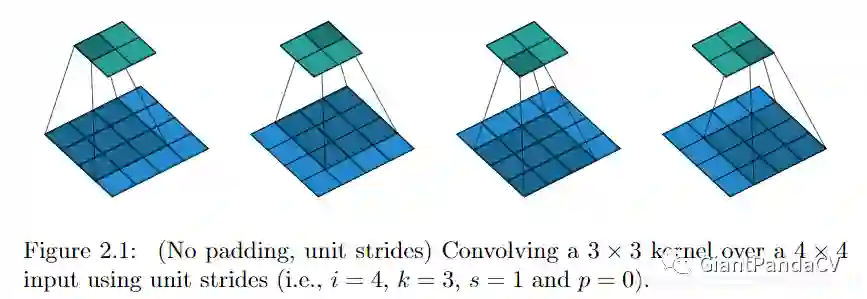
大部分pooling操作满足上图的模型,假设输入大小为 , 输出大小为 , kernel size简称 , stride简称 ,满足以下公式:
1. 最大/平均池化
最大池化就是选择图像区域中最大值作为该区域池化以后的值,反向传播的时候,梯度通过前向传播过程的最大值反向传播,其他位置梯度为0。
使用的时候,最大池化又分为重叠池化和非重叠池化,比如常见的stride=kernel size的情况属于非重叠池化,如果stride<kernel size 则属于重叠池化。重叠池化相比于非重叠池化不仅可以提升预测精度,同时在一定程度上可以缓解过拟合。
>>>
import torch
>>>
import torch.nn.functional
as F
>>> input = torch.Tensor(
4,
3,
16,
16)
>>> output = F.max_pool2d(input, kernel_size=
2, stride=
2)
>>> output.shape
torch.Size([
4,
3,
8,
8])
>>>
>>>
import torch
>>>
import torch.nn.functional
as F
>>> input = torch.Tensor(
4,
3,
16,
16)
>>> output = F.avg_pool2d(input, kernel_size=
2, stride=
2)
>>> output.shape
torch.Size([
4,
3,
8,
8])
>>>
2. 随机池化
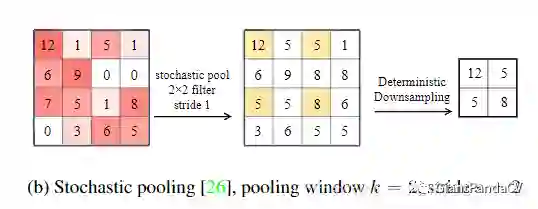
Stochastic pooling如下图所示,特征区域的大小越大,代表其被选择的概率越高,比如左下角的本应该是选择7,但是由于引入概率,5也有一定几率被选中。
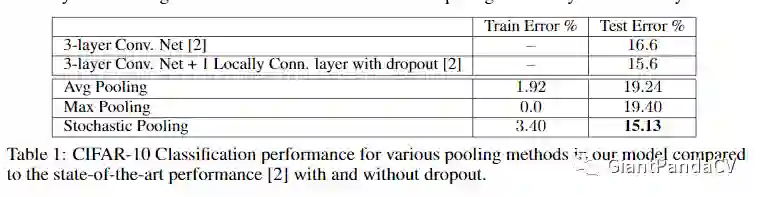
下表是随机池化在CIFAR-10上的表现,可以看出,使用随机池化效果和采用dropout的结果接近,证明了其有一定防止过拟合的作用。
更详细内容请看论文:《Stochastic Pooling for Regularization of Deep Convolutional Neural Networks》
3. 中值池化
与中值滤波特别相似,但是用的非常少,中值池化也具有学习边缘和纹理结构的特性,抗噪声能力比较强。
4. 组合池化
组合池化则是同时利用最大值池化与均值池化两种的优势而引申的一种池化策略。常见组合策略有两种:Cat与Add。常常被当做分类任务的一个trick,其作用就是丰富特征层,maxpool更关注重要的局部特征,而average pooling更关注全局特征。
def add_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return
0.5 * (x_avg + x_max)
def cat_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return torch.cat([x_avg, x_max],
1)
5. Spatial Pyramid Pooling
SPP是在SPPNet中提出的,SPPNet提出比较早,在RCNN之后提出的,用于解决重复卷积计算和固定输出的两个问题,具体方法如下图所示:
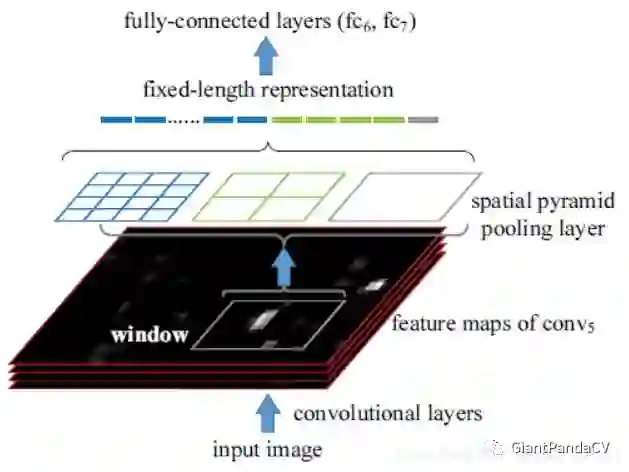
在feature map上通过selective search获得窗口,然后将这些区域输入到CNN中,然后进行分类。
实际上SPP就是多个空间池化的组合,对不同输出尺度采用不同的划窗大小和步长以确保输出尺度相同,同时能够融合金字塔提取出的多种尺度特征,能够提取更丰富的语义信息。常用于多尺度训练和目标检测中的RPN网络。
### SPP ###
[maxpool]
stride=
1
size=
5
[route]
layers=
-2
[maxpool]
stride=
1
size=
9
[route]
layers=
-4
[maxpool]
stride=
1
size=
13
[route]
layers=
-1,
-3,
-5,
-6
### End SPP ###
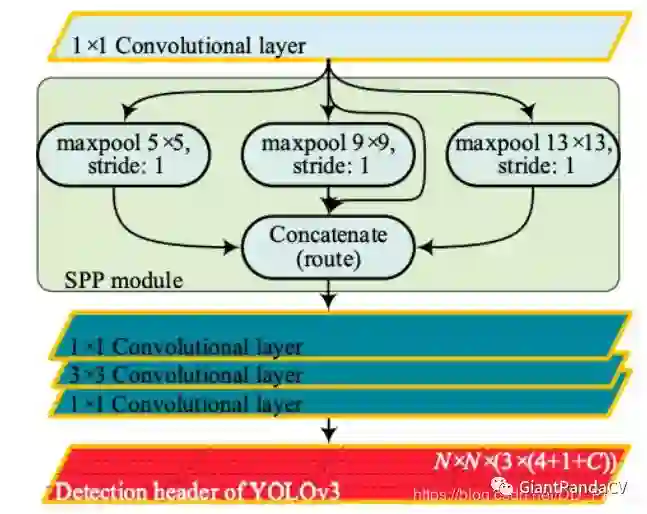
再来看一下官方提供的yolov3和yolov3-spp在COCO数据集上的对比:
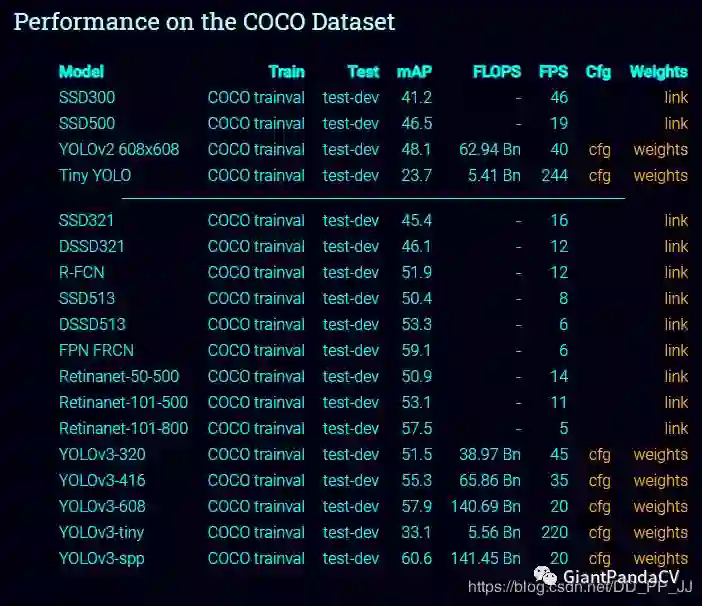
可以看到,在几乎不增加FLOPS的情况下,YOLOv3-SPP要比YOLOv3-608mAP高接近3个百分点。
分析一下SPP有效的原因:
-
从感受野角度来讲,之前计算感受野的时候可以明显发现,maxpool的操作对感受野的影响非常大,其中主要取决于kernel size大小。在SPP中,使用了kernel size非常大的maxpool会极大提高模型的感受野,笔者没有详细计算过darknet53这个backbone的感受野,在COCO上有效很可能是因为backbone的感受野还不够大。 -
第二个角度是从Attention的角度考虑,这一点启发自CSDN@小楞(链接在参考文献中),他在文章中这样讲:
出现检测效果提升的原因:通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
Attention机制很多都是为了解决远距离依赖问题,通过使用kernel size接近特征图的size可以以比较小的计算代价解决这个问题。另外就是如果使用了SPP模块,就没有必要在SPP后继续使用其他空间注意力模块比如SK block,因为他们作用相似,可能会有一定冗余。
ps: 这个想法还没有进行试验的验证,有兴趣的可以将YOLOv3-spp中的kernel size改为19,然后在COCO数据集上测试,看是否能够超越60.6。
6. Global Average/Max Pooling
>>>
import torch
>>>
from torch.nn
import AdaptiveAvgPool2d
>>> input = torch.zeros((
4,
12,
18,
18))
# batch size, fileter, h, w
>>> gap = AdaptiveAvgPool2d(
1)
>>> output = gap(input)
>>> output.shape
torch.Size([
4,
12,
1,
1])
>>> output.view(input.shape[
0],
-1).shape
torch.Size([
4,
12])
>>>
7. NetVLAD池化
这部分来自:DeepLearning-500-questions#5
NetVLAD是论文《NetVLAD: CNN Architecture for Weakly Supervised Place Recognition》提出的一个局部特征聚合的方法。
在传统的网络里面,例如VGG啊,最后一层卷积层输出的特征都是类似于Batchsize x 3 x 3 x 512的这种东西,然后会经过FC聚合,或者进行一个Global Average Pooling(NIN里的做法),或者怎么样,变成一个向量型的特征,然后进行Softmax or 其他的Loss。
这种方法说简单点也就是输入一个图片或者什么的结构性数据,然后经过特征提取得到一个长度固定的向量,之后可以用度量的方法去进行后续的操作,比如分类啊,检索啊,相似度对比等等。
那么NetVLAD考虑的主要是最后一层卷积层输出的特征这里,我们不想直接进行欠采样或者全局映射得到特征,对于最后一层输出的W x H x D,设计一个新的池化,去聚合一个“局部特征“,这即是NetVLAD的作用。
NetVLAD的一个输入是一个W x H x D的图像特征,例如VGG-Net最后的3 x 3 x 512这样的矩阵,在网络中还需加一个维度为Batchsize。
NetVLAD还需要另输入一个标量K即表示VLAD的聚类中心数量,它主要是来构成一个矩阵C,是通过原数据算出来的每一个 特征的聚类中心,C的shape即 ,然后根据三个输入,VLAD是计算下式的V:
输入与输出如下图所示:

将这个把上面的a替换后,即是NetVLAD的公式,可以进行反向传播更新参数。
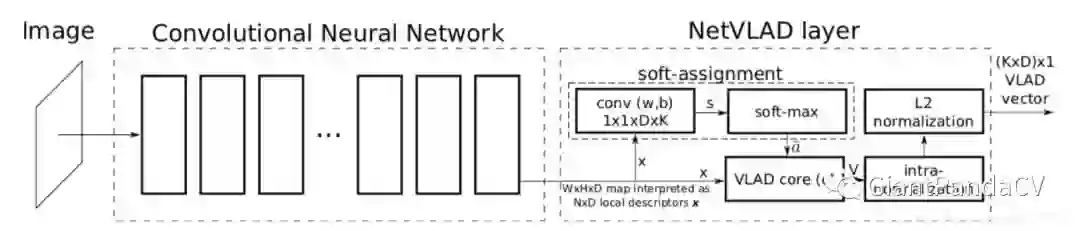
原论文中采用将传统图像检索方法VLAD进行改进后应用在CNN的池化部分作为一种另类的局部特征池化,在场景检索上取得了很好的效果。
后续相继又提出了ActionVLAD、ghostVLAD等改进。
评价:这个NetVLAD Layer和SENet非常相似,可以看做是通道注意力机制的实现,不过具体实现方法有别于SENet。
8. 双线性池化
Bilinear Pooling是在《Bilinear CNN Models for Fine-grained Visual Recognition》被提出的,主要用在细粒度分类网络中。双线性池化主要用于特征融合,对于同一个样本提取得到的特征x和特征y, 通过双线性池化来融合两个特征(外积),进而提高模型分类的能力。
主要思想是对于两个不同图像特征的处理方式上的不同。传统的,对于图像的不同特征,我们常用的方法是进行串联(连接),或者进行sum,或者max-pooling。论文的主要思想是,研究发现人类的大脑发现,人类的视觉处理主要有两个pathway, the ventral stream是进行物体识别的,the dorsal stream 是为了发现物体的位置。
论文基于这样的思想,希望能够将两个不同特征进行结合来共同发挥作用,提高细粒度图像的分类效果。论文希望两个特征能分别表示图像的位置和对图形进行识别。论文提出了一种Bilinear Model。
如果特征 x 和特征y来自两个特征提取器,则被称为多模双线性池化(MBP,Multimodal Bilinear Pooling)
如果特征 x = 特征 y,则被称为同源双线性池化(HBP,Homogeneous Bilinear Pooling)或者二阶池化(Second-order Pooling)。
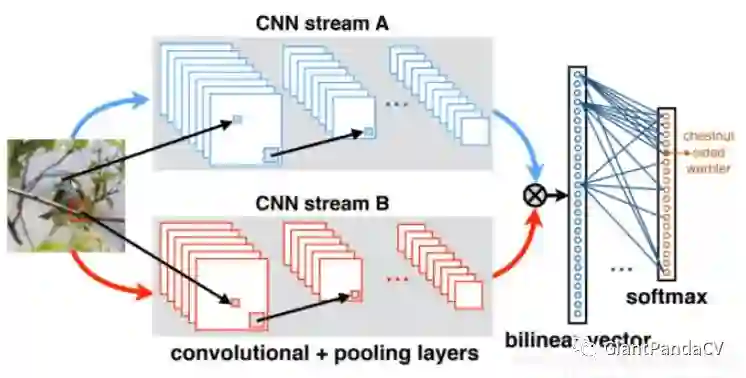
pytorch实现:
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization
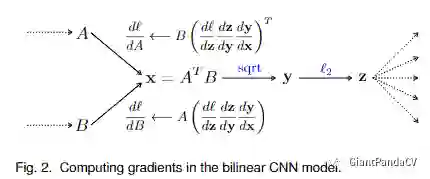
之后又有很多人出于对双线性池化存在的特征维度过高等问题进行各种改进,具体可以看知乎文章:https://zhuanlan.zhihu.com/p/62532887
9. UnPooling
是一种上采样操作,具体操作如下:
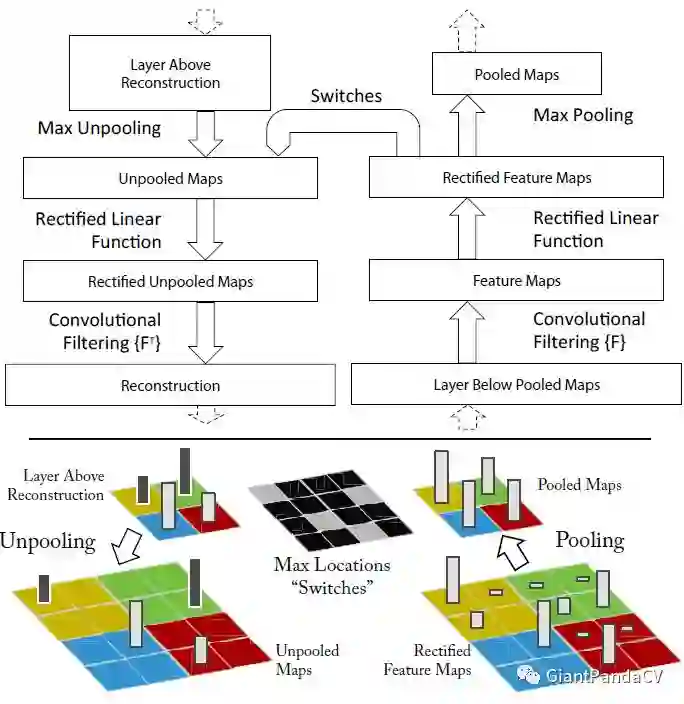
流程描述:
1.在Pooling(一般是Max Pooling)时,保存最大值的位置。
2.中间经历若干网络层的运算。
3.上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
UnPooling不完全是Pooling的逆运算,Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作;对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
参考
https://arxiv.org/pdf/1603.07285.pdf
https://arxiv.org/abs/1301.3557
https://zhuanlan.zhihu.com/p/77040467
https://arxiv.org/pdf/1611.05138.pdf
https://blog.csdn.net/qq_33270279/article/details/103898245
https://github.com/scutan90/DeepLearning-500-questions
https://zhuanlan.zhihu.com/p/62532887
https://blog.csdn.net/qq_32768091/article/details/84145088

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~