深度 | 最优解的平坦度与鲁棒性,我们该如何度量模型的泛化能力
选自inFERENCe
作者:Ferenc Huszár
机器之心编译
参与:陈韵竹、刘晓坤
深度网络最优解附近的平坦度一直是我们理解模型泛化性能的重点,通常较为平坦的最优解有更好的鲁棒性。而本文作者则进一步提出一个好的指标可能不仅涉及平均损失函数极小值附近的平坦度,还涉及两个平坦度指标之间的比率。
我看到大家在 Twitter 和 Reddit 中谈论这篇论文《Visualizing the Loss Landscape of Neural Nets》,于是撰写此文。
这篇论文与《Sharp Minima Can Generalize For Deep Nets》这篇极具洞察力的论文有关。
不可避免地,我开始以一种普遍性的角度思考极小值平坦度和泛化能力之间的关系。因此,我没有详细描述以上两篇论文,而是阐述了自己的一些思考。欢迎大家批评指教!
本文要点
极小值的平坦度(flatness of minima)被认为与深度网络的泛化能力有关。
正如 Ding et al (2017) 所表明的那样,平坦度对于参数重设(reparametrization)非常敏感,因此不能单独用平坦度预测泛化能力。
Li et al (2017) 使用了一种参数归一化的形式,这一方案对于参数重设更具有鲁棒性。此外,绘制了一些对比深度神经网络的奇特图像。
虽然上述分析对 Dinh 等人所考虑的特定类型的参数重设而言具有不变性,但是它对其他类型的不变性而言可能仍具敏感性,所以这些图表和结论仍具有不确定性。
然后,我回到起点,思考如何构建与结构不相关的泛化指标,例如考虑平坦度比率。
最后,我想到,可以从基本原理的角度开发一个泛化的局部测量指标。所得到的度量取决于从不同小批量中计算的梯度的数据和统计特性。
平坦度、泛化和 SGD
深度网络的损失函数表面往往存在许多局部极小值。其中,许多网络在训练误差方面表现得同样好,但是它们可能具有非常不同的泛化能力。即,损失函数值极小值处的网络在训练集上可能表现得很好,也可能很差。有趣的是,小批量随机梯度下降(SGD)得到的极小值点似乎比大批量 SGD 有更好的泛化能力。所以,有一个大问题:局部极小值的哪种可测属性能预测泛化能力?这与 SGD 又有什么关系?
至少在 1997 年,Hochreiter 和 Schmidhuber 猜测极小值的平坦度是一个很好的衡量标准。然而,正如 Dinh et al(2017)指出的那样,平坦度对于神经网络的参数重设是敏感的:我们可以在不改变输出的情况下对神经网络进行参数重设,同时使尖锐的极小值点看起来任意平坦,反之亦然。因此,单纯利用平坦度这一指标无法解释或预测良好的泛化能力。
Li et al(2017)提出了一种归一化方案,该方案在极小值附近对空间进行缩放。对于 Dinh 等人所使用的参数重设类型,该方案能让一维、二维图像的表观平坦度具有不变性。他们说,这使得我们能在极小值周围的损失函数表面得到更可信的可视化结果。此外,他们还使用一维图和二维图解释不同架构之间的差异,如 VGG 和 ResNet。我个人并不赞同这一观点,但似乎 ICLR 的审稿人很大程度上同意这一观点(https://openreview.net/forum?id=HkmaTz-0W)。上述方法理论基础很薄弱,且只针对一种可能类型的参数重设。
平坦度度量
跟随着 Dinh 等人的思路,如果在参数重设的情况下泛化能力具有不变性,用来预测泛化能力的度量值也不应随之改变。以我的直觉,有一种实现不变性的好思路,即考虑两个值的比率——也许是两个平坦度的值——这两个值以同样的方式受参数重设的影响。
我认为,比较单一小批量损失函数的平均平坦度和平均损失函数的平坦度很有意义。为什么呢?这是因为损失函数平均值可能以不同的方式在极小值附近平坦化:其平坦可能因为它是许多平坦函数的平均值——这些函数图像相似,并且其极小值位置相近;其平坦也可能因为它是许多尖锐函数的平均值——这些尖锐函数的极小值散乱分布于平均极小值的附近。
凭直觉讲,前一种方案在数据子采样(subsampling)中更为稳定,因此从泛化的角度来看更为有利。后一种解决方案对于我们正在研究的某个特定小批次非常敏感,所以它有可能会导致更糟糕的泛化能力。
我们来给这部分做一个小结。我认为,仅关注平均损失函数的平坦度并不合理;而通过观察数据子采样对平坦度的影响更可能是理解泛化能力的关键。
局部泛化度量
在 Jorge Nocedal 的 ICLR 演讲谈到大批量 SGD 后(https://iclr.cc/archive/www/lib/exe/fetch.php%3Fmedia=iclr2017:nocedal_iclr2017.pdf),Leon Buttou 发表了一条评论,我认为这评论一针见血。从训练集采样小批量的过程,在某种程度上模拟了从一些基础数据分布中采样训练集和测试集的效果。因此有可能,从一个小批量到另一个小批量的泛化能力,也就代表了一个方法从训练集到测试集的泛化能力。
我们如何利用这种想法,提出某种基于小批量,特别是依据函数锐度或局部偏导数而构建的泛化能力度量方法?
首先,我们考虑随机过程 f(θ),这可以通过评估一个随机小批量的损失函数得到。随机性来自对数据进行的子采样。这是以 θ 为变量的损失函数概率分布。我认为,应该在任何给定的 θ 值下寻找泛化能力指标,并将其作为这个随机过程的局部性质。
为了简化问题,我们首先假定从这个过程中得到的每个 f(θ) 都是凸函数,或者至少有一个唯一的全局极小值。在这个随机过程中,如何描述模型从一个小批量到另一个小批量的泛化能力?
我们独立地绘制 f_1(θ) 和 f_2(θ) 两个函数图(即,独立地评估两个小批量的损失函数)。我认为,以下将是一个有意义的度量:
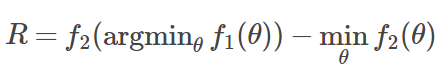
基本上,我们需要知道在 f_1 的极小值点处 f_2 的值,并与 f_2 的全局极小值进行比较,这是一种 Regret Expression,因此我用 R 表示。
然而,在深度学习中,损失函数 f_1 和 f_2 是非凸的,它们有许多局部极小值。所以一般来说,这个定义并不是特别有用。然而,在特定的参数值 θ 的小邻域内对 R 进行局部计算是有意义的。让我们考虑拟合一个受限的神经网络模型,其参数取值范围只在 θ 变量的 ϵ 邻域以内。如果 ϵ 足够小,我们可以假设损失函数在这个 ϵ 球面内具有唯一的全局极小值。此外,如果 ϵ 足够小,则可以使用对 f_1 和 f_2 的一阶泰勒近似,解析地在 ϵ 球面内找到近似极小值。为此,我们只需要在 θ 处计算梯度。如下图所示:
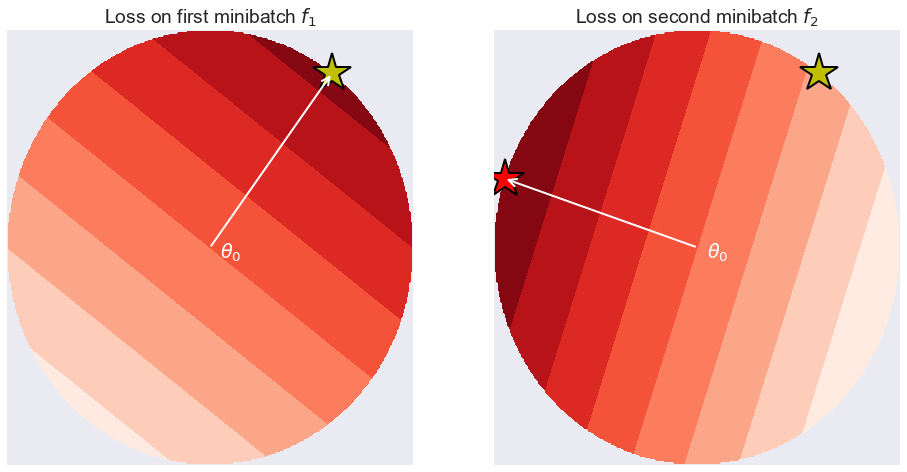
左图显示了仅限于 θ 附近的 ϵ 球内在某小批量 f_1 上的假想损失函数。我们可以假设 ϵ 足够小,因此 f_1 在这个局部区域内是线性的。除非梯度恰好为 0,否则极小值将落在 ϵ 球的表面上,正好在 θ-ϵ(g_1/‖g_1‖ ) 处,其中 g_1 是 θ 处的 f_1 的梯度。图中的黄色五角星标注了这一点。右图是 f_2 的情况。它也是局部线性的,但是它的梯度 g_2 可能不同。ϵ 球内的 f_2 的最小值在 θ-ϵ(g_2/‖g_2‖) 处,如红色五角星所示。我们可以考虑如上所述的 regret-type expression,即评估黄五星位置的 f_2 值,并减去它在红五星位置上的值。将其表示如下(其中我已对 R 除以 ϵ):
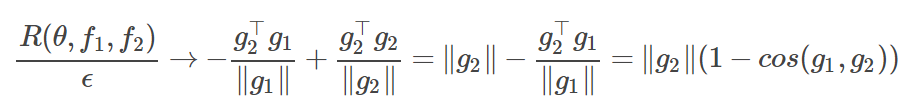
实际上,人们会对两个小批量取期望值以获得取决于 θ 的表达式。所以,我们刚刚提出了一个局部泛化能力指标,它是用不同小批量上的梯度期望值来表示的。该度量是局部的,这是因为它对于每个 θ 而言都有一个特定值。它依赖于数据,因为它取决于我们从小批量中采样的分布 p_D。
本指标取决于两个量:
来自不同小批量的梯度的预期相似性 1-cos(g_1,g_2),它可以看出各种小批量的数据是否在相似的方向上推动 θ。大多数情况下,在梯度采样于类球形对称分布的区域,这一项接近于 1。
梯度 ‖g_2‖ 的大小。有趣的是,可以将其表达为
。
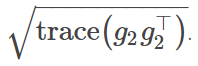 。
。当我们计算上式的期望值时,假设大部分余弦相似度是 1,我们最终得到这个表达式:
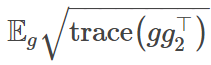
其中,期望值是在小批量中计算得到的。注意经验 Fisher 信息矩阵(empirical Fisher information matrix)迹的范数:
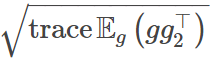
可以用来衡量极小值周围平均损失函数的平坦度,所以它们之间可能会有一些有趣的联系。但是,由于 Jensen 不等式,它们实际上并不完全等同。
小结
本文始于对一篇论文的回顾。但是后来我认为那篇论文并不是很有意义,因此我转而分享了一些关于如何解决泛化难题的不同想法。很有可能前人做过类似的分析,也有可能这种分析完全无用。无论如何,欢迎反馈。
第一个观察结果是,一个好的指标可能不仅涉及平均损失函数极小值附近的平坦度,而可能还涉及两个平坦度指标之间的比率。这样的指标在结构的参数重设下可能保持不变。
对此进一步考虑,我试图开发一个超越平坦度之外的泛化能力局部指标,它包括了测量梯度对数据子采样的敏感度。
由于数据子采样是泛化(训练集 vs 测试集)和小批量随机梯度下降中都出现的情况,所以,这些度量可能有助于利用 SGD 实现更好的泛化。

原文链接:http://www.inference.vc/sharp-vs-flat-minima-are-still-a-mystery-to-me/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

