中科院自动化所团队提出新方法,让AI掌握《星际争霸》微操作(内附论文作者亲自讲解)

2016年3月,AlphaGo以4:1战胜李世乭,一度引发了世界范围内对于“人机大战”的狂热关注;2017年1月,一个名为“MASTER”的神秘棋手60盘连胜狂扫各路棋坛高手,后被证实是AlphaGo的升级版;5月,AlphaGo以3:0战胜世界排名第一的天才棋手柯洁,“世界第一围棋高手”正式易主成为一台计算机。从1997年深蓝击败当时排名世界第一的棋手卡斯帕罗夫开始,AI不断在游戏这一人类智力的“专属领域”攻城掠地,甚至登上巅峰。为什么科学家们孜孜不倦的追求让AI玩游戏?究竟是AI选择了游戏,还是游戏选择了AI?
游戏是测试AI的绝佳平台。一方面,科学家通过训练AI进行棋类博弈有助于改进算法及提高计算机能力。另一方面,AI通过游戏采集众多玩家的行为信息来组成庞大的数据库,例如普林斯顿大学研究人员将AI投放到游戏《GTA5》中,使得AI可以在游戏环境中不断得到训练,从而在面对不同的灯光、气候、路况等条件时,能够做出最优的反应。最终,研究人员成功开发出一项名叫DeepDrive的自动驾驶模拟器。
近日,中国科学院自动化研究所赵冬斌研究员团队提出了一种强化学习+课程迁移学习方法,通过即时战略游戏(RTS)——《星际争霸》来探索多智能体的控制,让AI智能体在组队作战的条件下掌握了微操作的能力。与完全信息、零和博弈、确定性的棋类游戏不同,《星际争霸》是一类典型的社会性游戏,涉及众多不确定、协作与竞争的复杂因素,是对AI智能水平的更大挑战。星际争霸AI旨在解决一系列难题,如时空推理、多智能体协作、对手建模和对抗性规划等问题。由于目前设计一款基于机器学习的全星际游戏AI是不现实的,因此许多研究者将微操作为星际争霸人工智能研究的第一步。在战斗场景中,单位必须在高度动态化的环境中航行,攻击火力范围内的敌人。星际争霸有很多微操方法,包括用于空间导航和障碍规避的潜在领域、处理游戏中的不完整性和不确定性的贝叶斯建模、处理建造顺序规划和单位控制的启发式博弈树搜索,以及用于控制单个单位的神经进化方法。

图片拍摄于2017年12月9号,赵冬斌课题组组织的第二届深度强化学习研讨会顺利召开,与会人员围绕游戏AI、智能驾驶、建筑能源等领域进行了深入交流。
对于星际争霸的微操,传统方法在处理复杂状态、行动空间和学习合作策略方面存在困难。现代方法则依赖于深度学习引入的强大计算能力。另一方面,使用无模型强化学习方法学习微操通常需要大量的训练时间,在大规模场景中,这种情况更为明显。在赵冬斌教授团队的新研究中,试图探索更高效的状态表示以打破巨大状态空间引发的复杂度,同时提出了一种强化学习算法( RL )用以解决星际争霸微操中的多智能体决策问题。此外,研究人员还引入了课程迁移学习(curriculum transfer learning),将强化学习模型扩展到各种不同场景,并提升了采样效率。
该研究主要有三个贡献:一种高效的状态表征方法以处理星际争霸微操中的大型状态空间、共享参数多智能体梯度下降Sarsa(λ)算法、有效的回报函数以及将模型扩展到不同场景的课程迁移学习方法。在小规模场景中,研究人员一方成功学会了战斗并以100%胜率击败了内置AI。在大规模场景中,使用课程迁移学习渐进地训练一组单元,并在目标场景中展现出了优于一些基准方法的性能。通过强化学习和课程迁移学习,研究人员一方能够在星际争霸微操场景中学会合适的策略。
采访
该研究论文被学术期刊IEEE Transactions on Emerging Topics in Computational Intelligence收录后,德先生针对研究背景及未来工作展望等几方面内容向论文作者赵冬斌教授做了独家采访,以下为文字实录:
问:为什么您的团队会选择星际争霸来训练AI?
答:以星际争霸为代表的即时策略游戏,一方面由于迷雾的存在导致此类问题是不完全信息的动态博弈,另一方面由于操作单元种类繁多、数量巨大、决策制定跨度时间长等特点,普遍被认为是人工智能要挑战的下一个领域。为此,像谷歌、脸书等公司已经开始组建团队,以星际争霸作为人工智能的研究平台,开发AI系统,击败顶级人类玩家。我们一直从事相关方向的研究,也希望在这个平台上利用强化学习和深度学习等方法开发先进的AI。
问:在选择强化学习+课程迁移学习的方式之前,是否也采用了其他方法,效果如何?为何强化学习+课程迁移学习的方式能够取得更好的效果?
答:在本文的工作中,我们使用了强化学习方法和课程迁移学习方法,处理星际争霸微操中的多单元控制问题。由于星际争霸微操是一种多智能体的马尔可夫博弈,而强化学习非常适合处理这类序列决策问题,故我们选择强化学习作为主要的方法。这类任务存在明显的延时稀疏回报,使用资格迹的强化学习算法能实现更好的信用分配。为了将模型扩展到更加复杂的场景,我们采用了课程迁移学习的方式渐进式地训练AI。通过与没有采用这种方式的模型进行比较,可以看出课程迁移学习方法能提高学习效率,实现更好的泛化效果。
问:从AI出现之时,让AI打游戏就是很多研究者的目标,我们能说AI学会打游戏了,就是有智能了吗?
答:游戏是测试人工智能的一个典型的平台。从早期的深蓝,到最近的AlphaGo,都是人类通过让AI玩游戏去体现智能。像星际争霸这类即时策略游戏的优化决策更是能体现高级的智能。AI在玩这类游戏时需要在不断的预测、选择和评估中探索可行的策略。游戏引擎给AI提供的信息具有海量、高维、抽象的特点。AI需要将这些信息有效地进行表示、抽象并加以理解,推导出双方在全局和局部区域的态势评估。同时,AI需要控制多种单元相互配合,合理利用不同类型、不同数量单元的特点,制定出协同优化策略。这些都能体现AI在学会玩游戏的过程中具有了智能。
问:这一研究工作在未来能够在哪些方面得以应用?
答:星际争霸的相关研究工作需要融合多种高级人工智能方法,才能获得较高水平的AI。研究此类问题对于人工智能的发展具有重大推动作用。该问题属于不完全信息条件下多智能体之间相互协调的博弈过程,与很多实际问题本质上是相似的。从与日常生活息息相关的智能驾驶和智能交通,到电力系统的优化调度,以及最近爆发的中美贸易争端等,都存在一定的借鉴作用。

扫描二维码,即刻报名参与IV2018
正文
下附研究论文中文版解读:
基于强化学习和课程迁移学习的星际争霸微操
邵坤,朱圆恒,赵冬斌
中国科学院自动化研究所
摘要
近年来,即时战略游戏已成为游戏AI中的一个重要领域。本文提出了一种基于强化学习和课程迁移学习方法,实现了星际争霸微操中的多单元控制。针对游戏环境中的高维状态空间引起的复杂性问题,我们给出了一种高效的状态表示定义。进而提出一种共享参数多智能体梯度下降Sarsa(λ)(PS-MAGDS)算法训练微操单元。我方单元共享学习策略以鼓励智能体之间的协同行为。我们使用一个神经网络作为函数近似器来评估动作值函数,并提出一种奖赏函数帮助单元平衡其移动和攻击。此外,我们还使用迁移学习方法把模型扩展到更加困难的场景,加速训练进程并提升学习效果。在小规模场景中,我方单元成功学会了战斗并以100%胜率击败了内置AI。在大规模场景中,我们使用课程迁移学习渐进地训练一组单元,并在目标场景中展现出了优于一些基准方法的性能。通过强化学习和课程迁移学习,我方单元能够在星际争霸微操场景中学会合适的策略。
一:介绍
人工智能(AI)在过去十年中有了巨大的进展。作为AI研究的绝佳测试平台,游戏自AI诞生之时就开始推动其技术的发展。在本文中,我们专注于即时战略游戏(RTS)来探索学习多智能体的控制。对于游戏AI的研究来说,星际争霸提供了一个理想的环境来研究不同困难程度下的多智能体控制问题。星际争霸AI旨在解决一系列挑战,如时间空间推理、多智能体协同、对手建模和对抗规划。在战斗场景中,单元必须在高度动态的环境中导航和攻击火力范围内的敌人。作为一种智能学习方法,强化学习 ( RL ) 非常适合序列决策任务。在最近几年,深度学习在处理复杂问题上已经取得了令人瞩目的成果,并且极大提高了传统强化学习算法的泛化能力和可扩展性。深度强化学习(DRL)可以让智能体学会如何通过端到端的方法在高维状态空间中做出决策。本文中,我们试图探索更高效的状态表示以解决巨大状态空间引发的复杂度,同时提出了一种合适的强化学习算法以解决星际争霸微操中的多智能体决策问题。此外,我们还引入了课程迁移学习,将强化学习模型扩展到各种不同场景中,并提升了样本效率。
二:问题定义和背景
A. 问题定义
在星际争霸微操中,我们需要控制一组单元在特定的地形条件下摧毁敌人。多个单元的战斗场景被近似为一个马尔可夫博弈,即马尔可夫决策过程(MDPs)的多智能体延伸。每个单元通过自身的观测和动作与作战环境进行交互。为了实现多智能体的协同,策略在所有单元间共享。每个单元的目标都是最大化其总体期望收益。
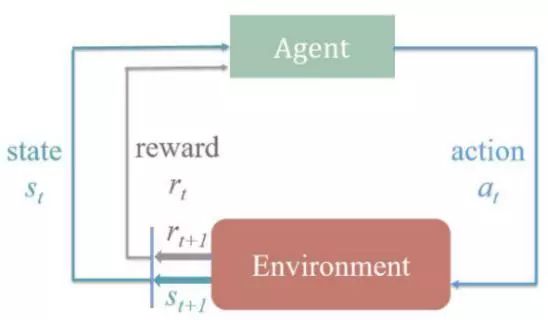
图1:强化学习中智能体与环境的交互过程
B. 强化学习
强化学习是一种通过试错机制进行学习的机器学习算法。其中,智能体通过与环境的交互来决定理想的行为。图1为经典的RL算法流程,它展示了一个RL智能体与环境之间的交互过程,这是一个马尔可夫决策过程。基于深度神经网络函数逼近器的强化学习在近几年已经得到了广泛的关注。DRL提供了一个采用端到端的方式训练智能体解决一系列人类水平任务的机会。多智能体强化学习与本文的工作有十分紧密的联系。一个多智能体系统包括在一个环境中交互的大量智能体。在本文中,我们使用一种多智能体强化学习方法,通过多智能体之间共享策略,学习合作行为。智能体共享集中式策略的参数,并且以各自的经验同步更新策略。这种方法可以更有效地训练同类智能体。
C. 课程迁移学习
在星际争霸微操中,由于单元和地形条件的不同,在不同场景中从零开始学习到有效的策略需要花费很多时间。许多研究人员致力于在不同但相关的任务中利用领域知识来提高学习速度和性能。使用最广的方法是迁移学习(TL)。在我们的实验中使用迁移学习的过程是先在源场景中用RL方法训练模型。然后,我们以训练好的模型为出发点来学习目标场景中的微操。作为迁移学习的一种特殊形式,课程学习包括一组通过逐渐增加难度而组织起来的任务。前期的任务是用来指导学习者,使其能更好地完成最终的任务。课程学习与迁移学习的组合,课程迁移学习(CTL)在最近的工作中表现出了良好的性能,可以加速学习过程,并朝着更好的方向收敛。对于微操来说,使用CTL的一个可行方法是先掌握一个简单的场景,然后基于这些知识解决复杂的情景。通过改变单元的数量和类型,我们可以控制微操的难度。这样,我们可以在一系列难度递增的微操场景中使用CTL训练我方单元,如图2所示。
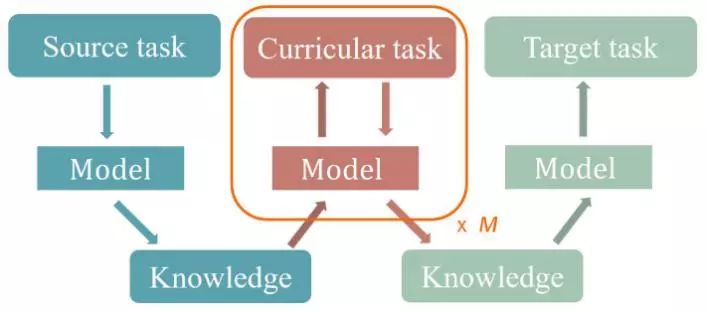
图2:课程迁移学习图解。解决源任务而获得的知识,逐渐应用到多个课程任务上以更新知识。最终,知识被应用于目标任务。
三:微操的学习模型
A. 高维状态表示
星际争霸的状态表示仍然是一个没有统一解决方案的开放问题。我们构造了一个状态表示,它包含不同数据类型和维度的游戏引擎输入,如表1所示。这里提出的状态表示方法是高效的,并且独立于作战单元数目。总的来说,状态表示由三部分组成:当前步的状态信息、上一步的状态信息和上一步动作,如图3所示。我们提出的状态表示方法也具有很好的泛化能力,可以应用于其他需要考虑智能体属性和距离信息的作战游戏中。

表1:模型中输入数据的类型和维度
B. 动作定义
在星际争霸微操场景中,原始动作空间非常大。在每一个时间步,每个单元可以在地图中的任意方向上移动任意距离。当单位决定攻击时,它可以选择武器射程内的任何敌方单位。为了简化动作空间,我们选择了8个固定距离的移动方向,以及攻击最弱地方单元作为每个单元的可用动作。
C. 网络架构
我们使用一个通过向量θ参数化的神经网络近似状态动作值来提高我们RL模型的泛化能力。网络的输入是来自状态表示的93维张量。我们在隐层中有100个神经元,并利用线性整流函数(ReLU)为网络的非线性激活函数。神经网络的输出层有9个神经元,提供向8个方向移动和攻击的概率。图3给出了在星际争霸微操场景中单元的学习模型,包括状态表示,神经网络架构和输出动作。
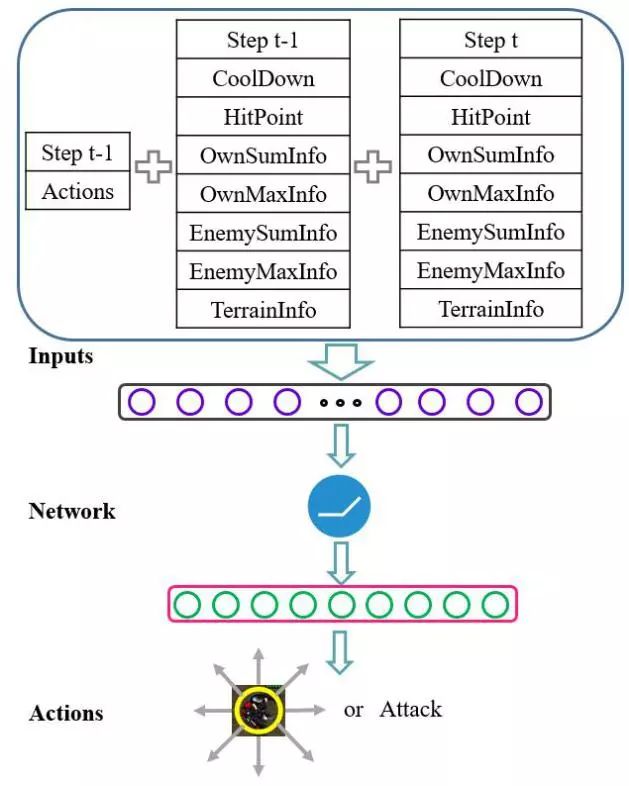
图3:星际争霸微操场景中单元的学习模型,包括状态表示,神经网络架构和输出动作。
四:微操的学习方法
在本文中,我们将星际争霸微操设置为一个多智能体强化学习模型。 我们提出了一个共享参数多智能体梯度下降Sarsa(λ)(PS-MAGDS)的方法来训练模型,并设计一种奖赏函数作为内在激励促进学习过程。 整个PS-MAGDS强化学习流程图如图4所示。
A. 共享参数多智能体梯度下降Sarsa(λ)
我们提出了一种多智能体强化学习算法,通过在我方单元之间共享策略网络的参数,将传统的Sarsa(λ)扩展到多个单元。为加速学习过程并解决延迟奖赏问题,我们在强化学习中使用资格迹。在本文实现的Sarsa(λ)多单元作战中,我们使用神经网络作为函数逼近器,并在我方所有单元之间共享网络参数。为了有效更新策略网络,我们使用梯度下降的方法来训练Sarsa(λ)强化学习模型。强化学习中的一个具有挑战性的问题是探索与利用之间的权衡。在实验中,我们使用ε-greedy方法来选择训练期间的动作。
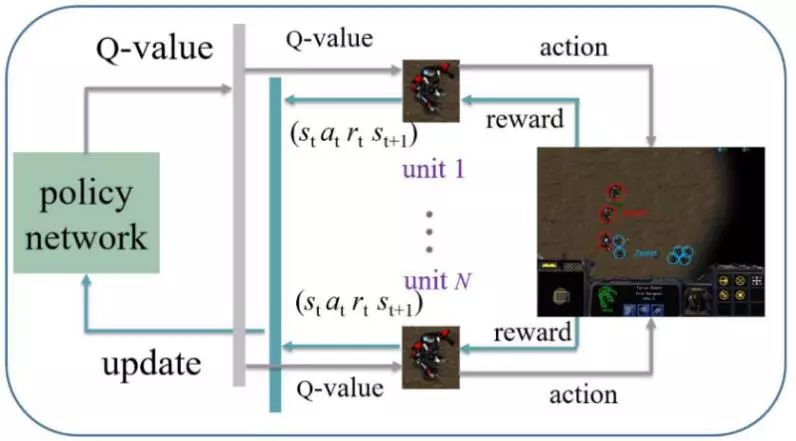
图4:星际争霸微操场景中PS-MAGDS强化学习流程图
B. 奖赏函数
为解决微操中稀疏延迟的奖赏问题,我们设计了一个奖赏函数。所有智能体都会在每个时间步获得由他们的攻击行动所造成的主要奖励,等于敌方单位受到的伤害减去我们单位的生命值损失。除了基本的攻击奖赏之外,我们还考虑一些额外奖赏作为加速训练过程的内在激励。当一个单元被摧毁时,我们引入额外的负面奖励,并在我们的实验中将其设置为-10。此外,为了鼓励我方单元作为一个团队并采取合作行动,我们对单元的移动行为引入了一个小的奖赏。如果在移动方向上没有我方单位或敌方单位,我们给这个移动动作一个小的负值奖赏,设置为-0.5。
C. 帧跳跃
由于星际争霸微操的实时属性,在每个游戏帧进行动作选择是不切实际的。一种可行的方法是使用跳帧技术,该技术每隔固定数量的帧执行训练步骤。我们在实验中将跳帧数目设置为10,即单元每10帧执行一次动作。
五:实验设置
A. 星际争霸微操情景
我们考虑多个单位的星际争霸微操情景,如图5所示,其中包括Goliaths vs. Zealots,Goliaths vs. Zerglings和Marines vs. Zerglings。
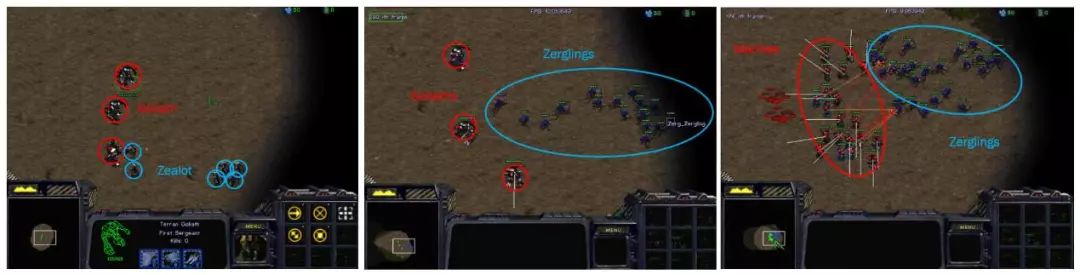
图5:我们实验中的星际争霸微操场景。
六:结果和讨论
A. 小规模的微操
在小规模微操场景中,我们将训练Goliaths对抗不同数量和类型的敌人。在第二个场景中,我们将基于训练好的第一种模型,使用迁移学习方法训练Goliaths。
Goliaths vs. Zealots:这个场景中,我们从零开始训练Goliaths并分析结果。
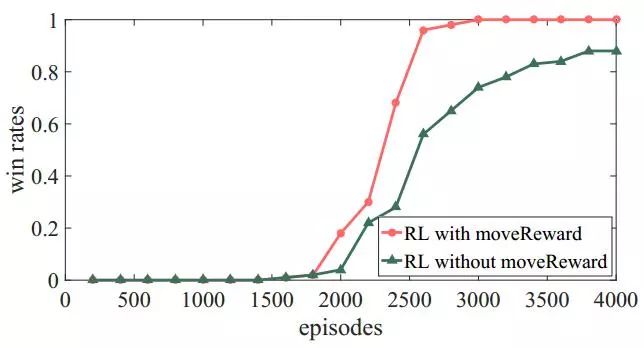
胜率:从图中可以看出Goliaths在1400局训练之前无法赢下任何一场战斗。随着训练的推进,作战单元开始赢下一些战斗,在2000局以后,胜率开始大幅上升。经过3000局的训练,我们最终达到了100%的胜率。
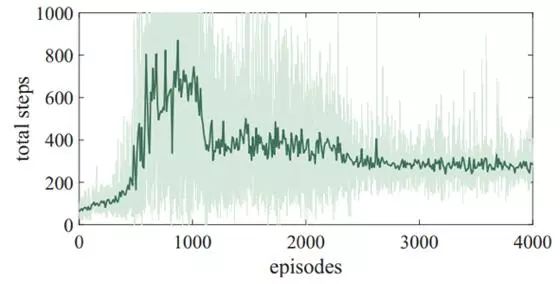
存活步数:平均存活步数的曲线分为四个阶段。开始存活步数很少。之后,Goliaths学会了逃跑,存活步数升高。然后存活步数开始下降,因为Goliaths学会了攻击而不是一昧地逃跑。最后,Goliaths学到了一个合适的策略以平衡移动和攻击。
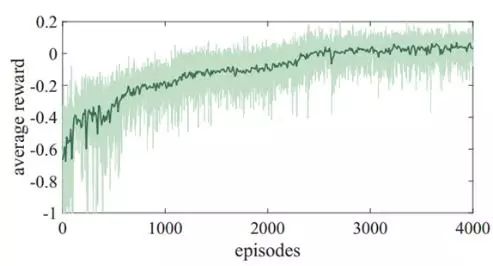
平均奖励:从图中可以清楚的看到平均奖励在开局阶段呈现出很明显地增长,随着训练的进行稳步增长,在接近3000次以后保持平滑。
Goliaths vs Zerglings:在这个场景中,我们将第一个场景中训练好的模型来初始化策略网络。
胜率:从零开始训练时,学习过程非常缓慢。没有使用迁移学习进行训练,我方单元的获胜概率低于60%。基于第一个场景的模型进行训练时,学习过程要快得多。即使在训练初期,我方单元也赢得了几场比赛,最终胜率达到了100%。
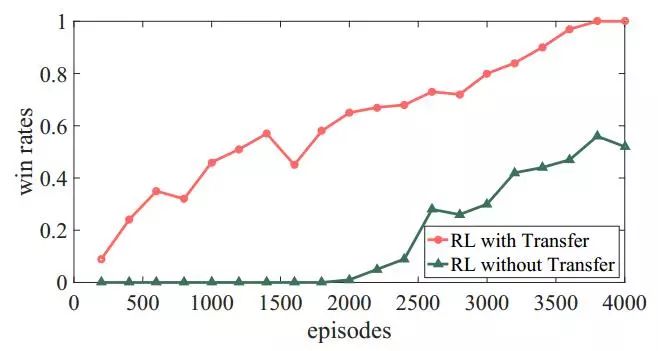
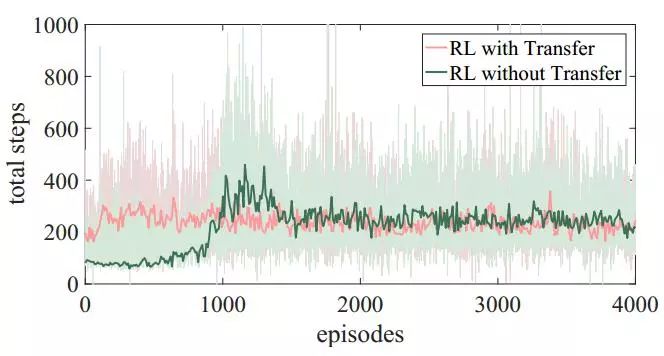
存活步数:没有使用迁移学习时,曲线走势和第一个场景类似。在使用迁移学习的情况下,平均存活步数在整个训练过程中稳定在200到400之间。
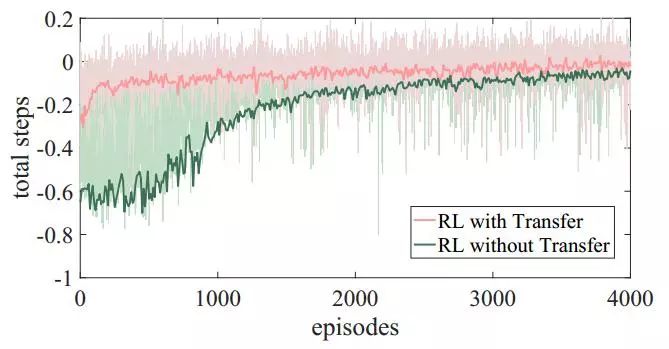
平均奖励:从零开始训练时,我方单元在训练初期很难赢得比赛。使用迁移学习的平均回报要高很多,并且在整个训练过程中都表现得更好。
B. 大规模的微操
在大规模的微操场景中,我们使用课程迁移学习来训练我方的Marines与Zerglings对抗,并将结果与一些基准方法进行比较。
1) Marines vs. Zerglings:我们设计了一个包涵三个阶段的课程来训练作战单元。在训练之后,我们在两个目标场景中测试模型的性能,我们使用一些基准方法作为比较,其中包括基于规则的方法和深度强化学习方法。
在表四中,我们展示了PS-MAGDS方法和基准方法的胜率。

表4:PS-MAGDS方法和基准方法的胜率比较
我们也在课程场景和没有见过的场景中测试我们训练好的模型,并在表5中展示了结果。我们可以看到PS-MAGDS在这些课程场景中有出色的表现。在没有见过的场景中,我们增加单元的数量后,PS-MAGDS依然有令人满意的结果。
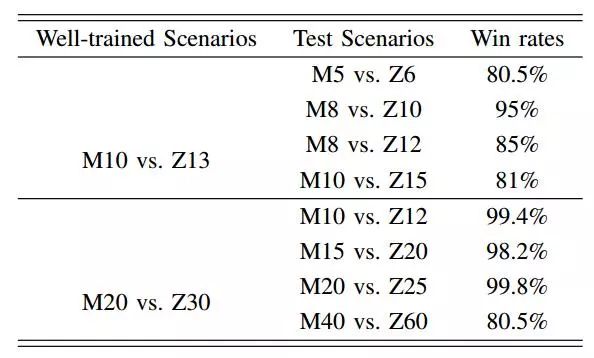
表5:在课程场景和没有见过的场景中PS-MAGDS方法的胜率比较
C. 策略分析
通过强化学习和课程迁移学习,我方单元能够在这些场景中掌握一些有用的策略。
1) 分散敌方火力:在小规模的微操中,我方的Goliaths单元必须与拥有更多数量和总体血量的敌人进行对抗。合适的策略是分散敌方火力,一个一个地摧毁他们。

图12:3 Goliaths vs. 6 Zealots 游戏画面
类似的策略也出现在第二个场景中。我方的Goliaths将Zergling分散成几个组,并与它们保持一定的距离。当单元的武器处于有效冷却状态时,它们停止移动然后攻击敌人,如图13所示。

图13:3 Goliaths vs. 20 Zerglings 游戏画面
2) 保持队形:在大规模的微操场景中,每一方都有大量的单位。一个合适的策略是让我们的Marines保持在一个团队中,以同样的方向前进,并攻击相同的目标,如图14所示。从这些游戏画面可知,我方的Marines已经学会了集体的前进和撤退.
3) 边跑边打:除了上面讨论的全局战略之外,我们的单元在训练期间也学到了一些局部的策略。其中,边跑边打是星际争霸微操中使用最广泛的一种战术。我方单元在所有场景中都快速地学到了这一策略,包括图12和图13中单个单元的边跑边打和图14中一个队伍的边跑边打。

图14:20 Marines vs. 30 Zerglings 游戏画面
七:总结和未来的工作
本文关注星际争霸微操场景中的多智能体控制问题。我们提出了多个贡献,包括一种高效的状态表示,共享参数多智能体梯度下降Sarsa(λ)算法,有效的回报函数以及将我们的模型扩展到不同场景的课程迁移学习方法。在小规模和大规模场景中,我们都论证了该方法的有效性,以及在两个目标场景中超出一些基准方法的优异性能。值得注意的是,我们提出的方法能够在不同场景中学会合适的策略并且击败内置的AI。此外,我们的工作仍然有一些可以改进的地方。虽然我方单元能够成功掌握一些有效的协同策略,将来工作中我们会探索并使用更加智能的多智能体协同方法。为了解决星际争霸微操中的延时回报问题,我们在本文中使用了简单直接但高效的奖赏塑形方法。然而,仍然有一些其他方法用于解决稀疏和延时回报问题,例如分层强化学习。当前,我们只能成功训练同一类型的远战单元,然而使用强化学习方法训练近战单元依然没有很好地解决。我们将改进我们的工作以适用于更多类型的单元和更复杂的场景。最后,我们会考虑在星际争霸AI中使用我们的微操模型来进行全局比赛的对抗。

📚往期文章推荐

🔗人大直博生乔婧思:13篇SCI,离不开超越十分的坚持与专注

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。




