Shreya Gherani:BERT庖丁解牛(Neo Yan翻译)

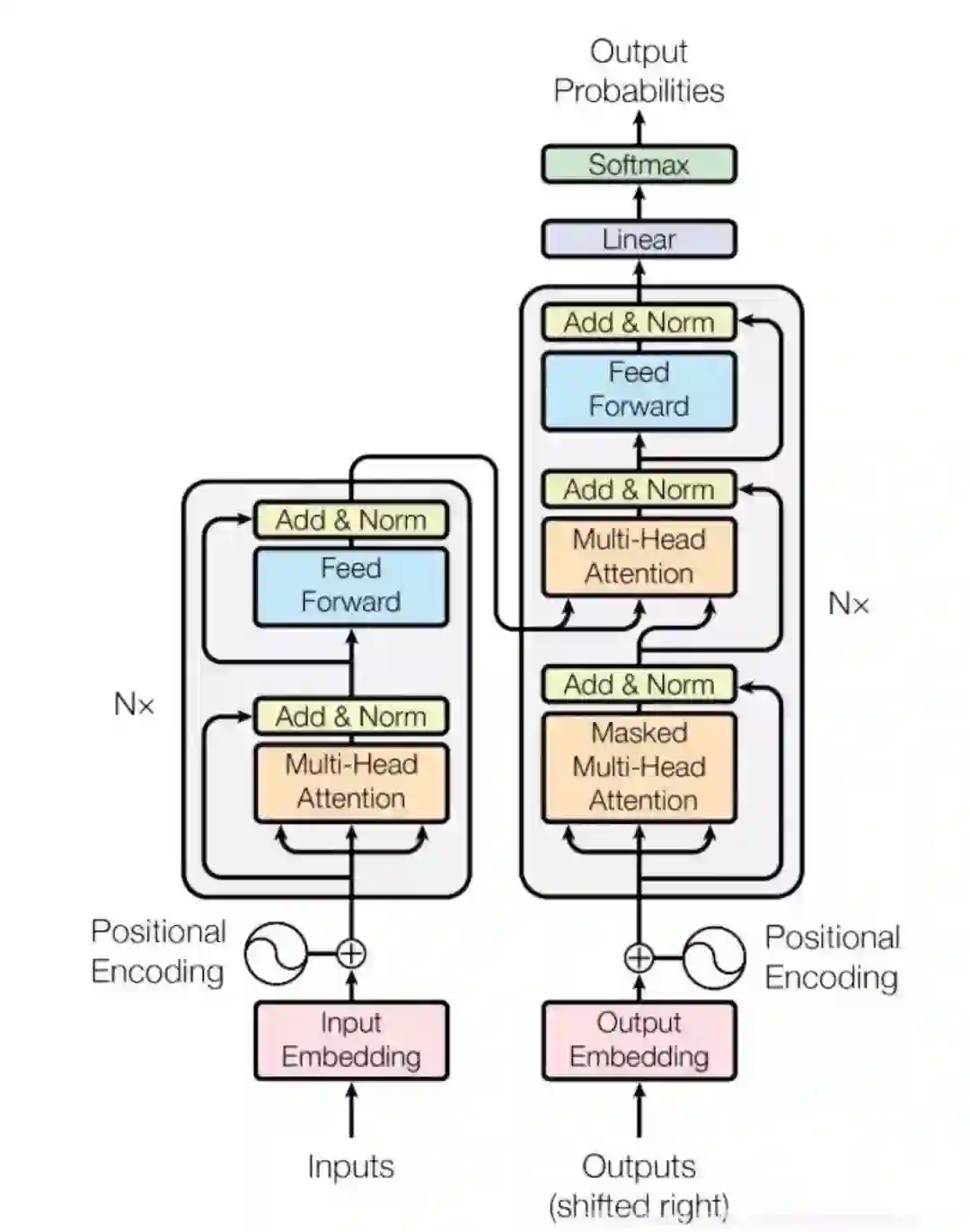
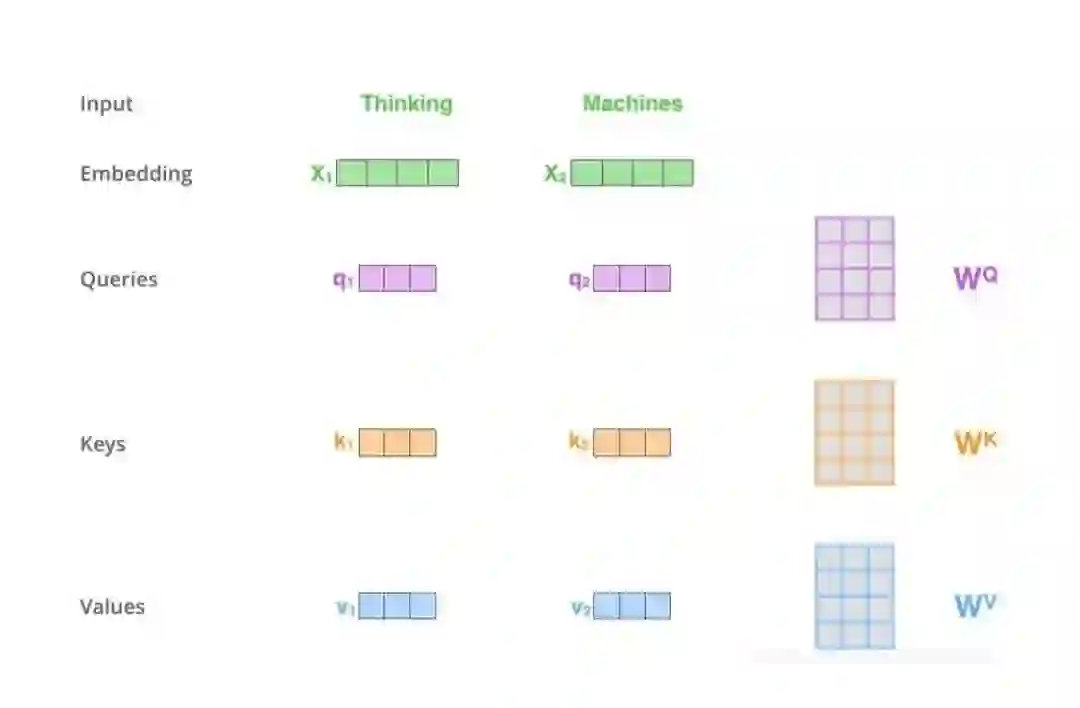
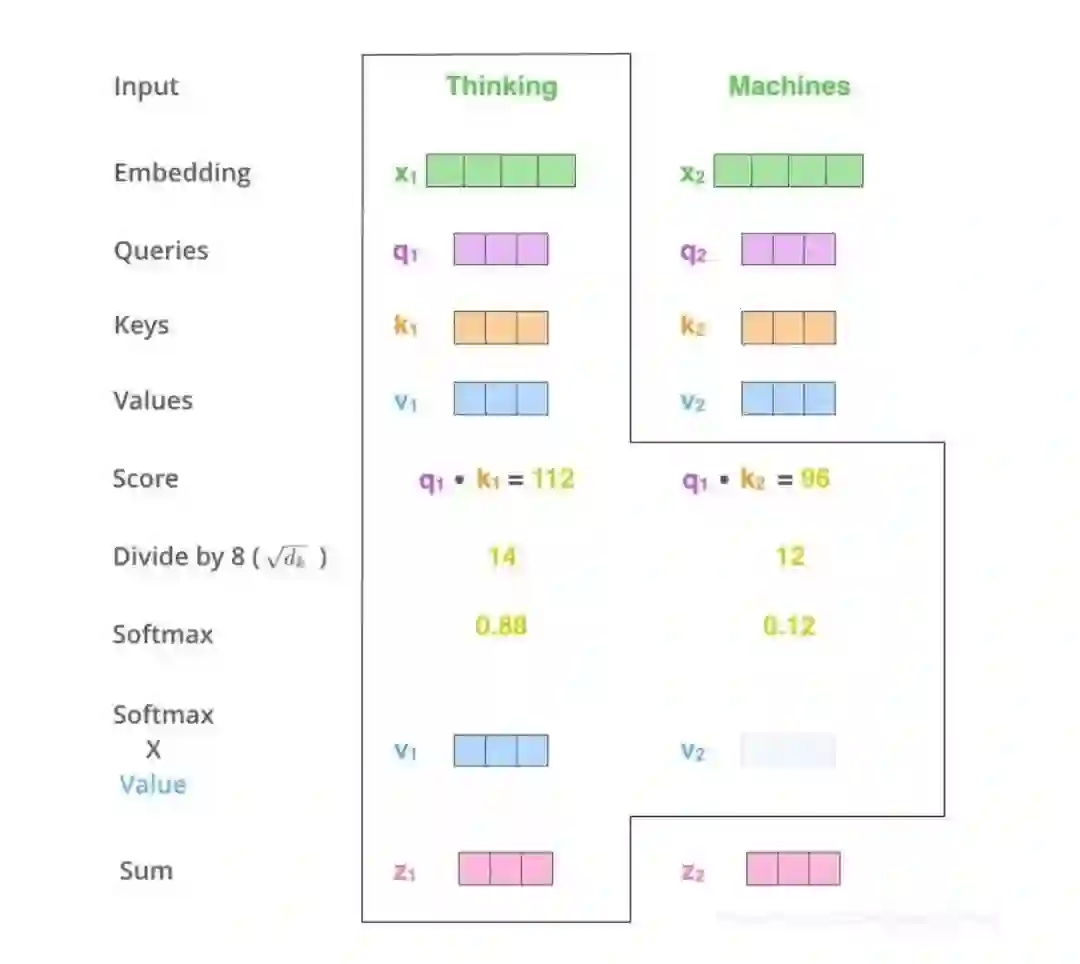
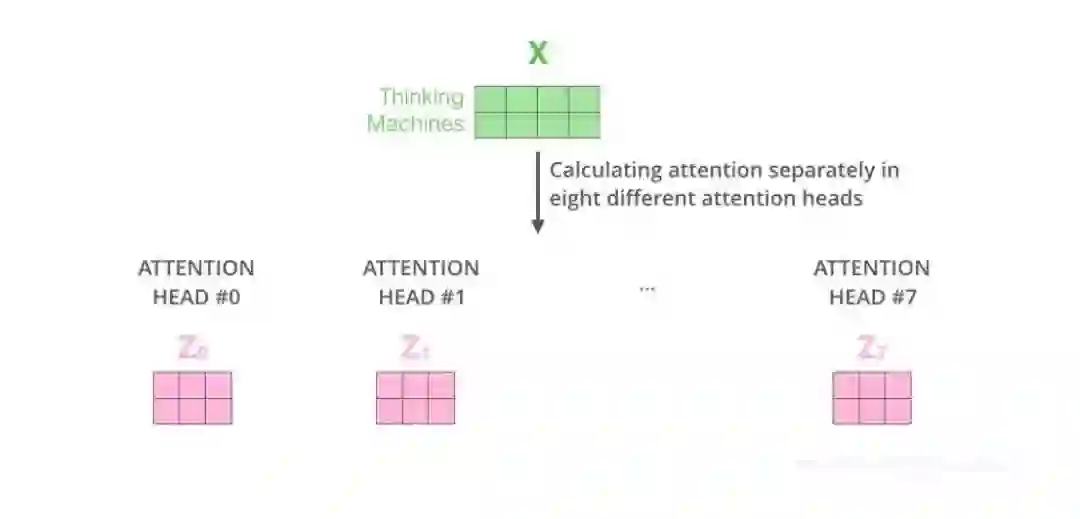
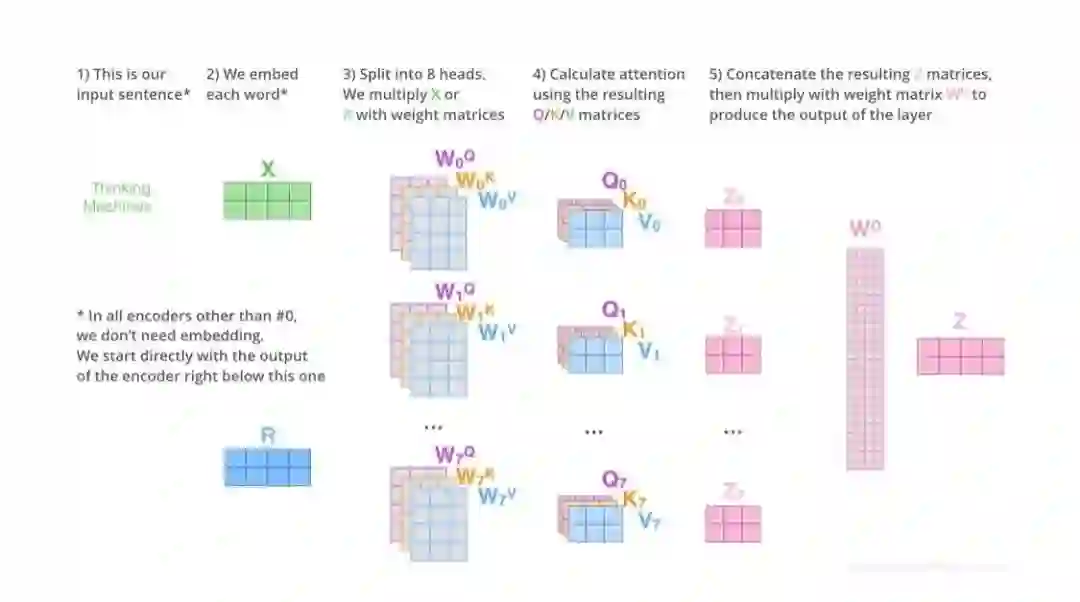
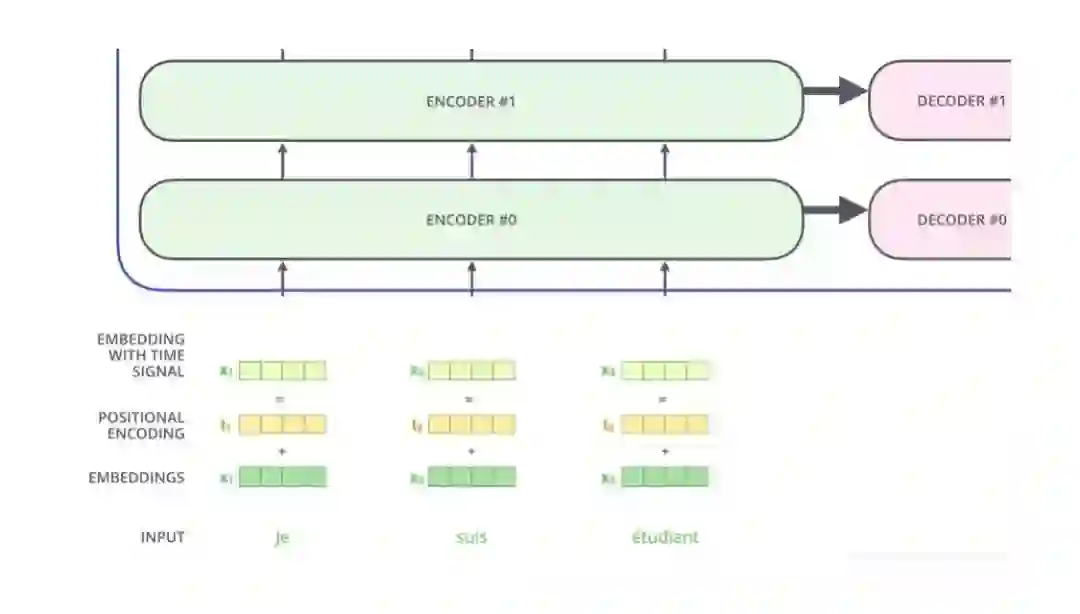
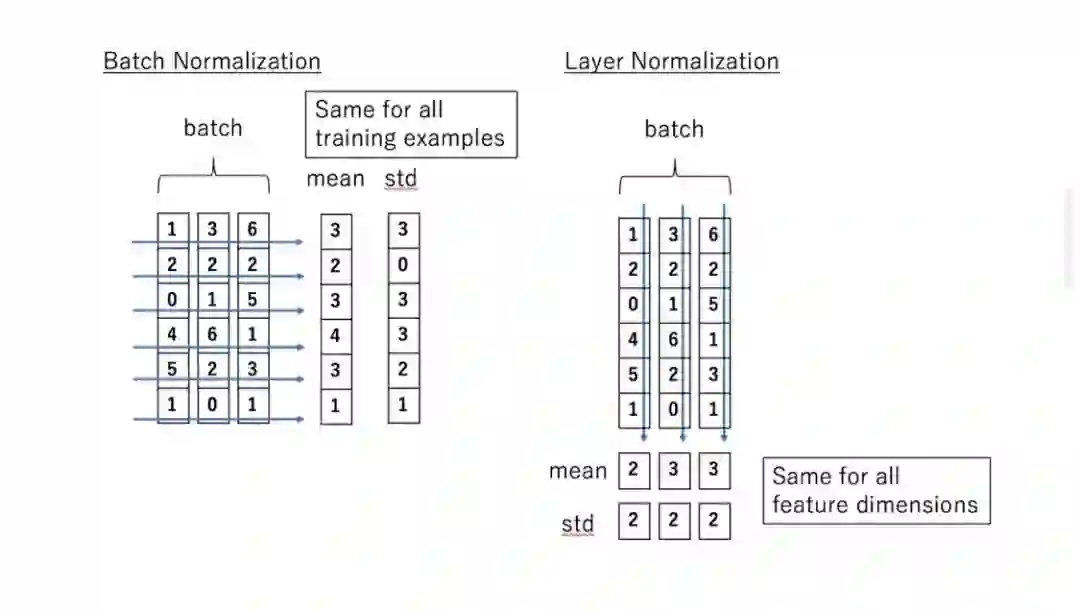
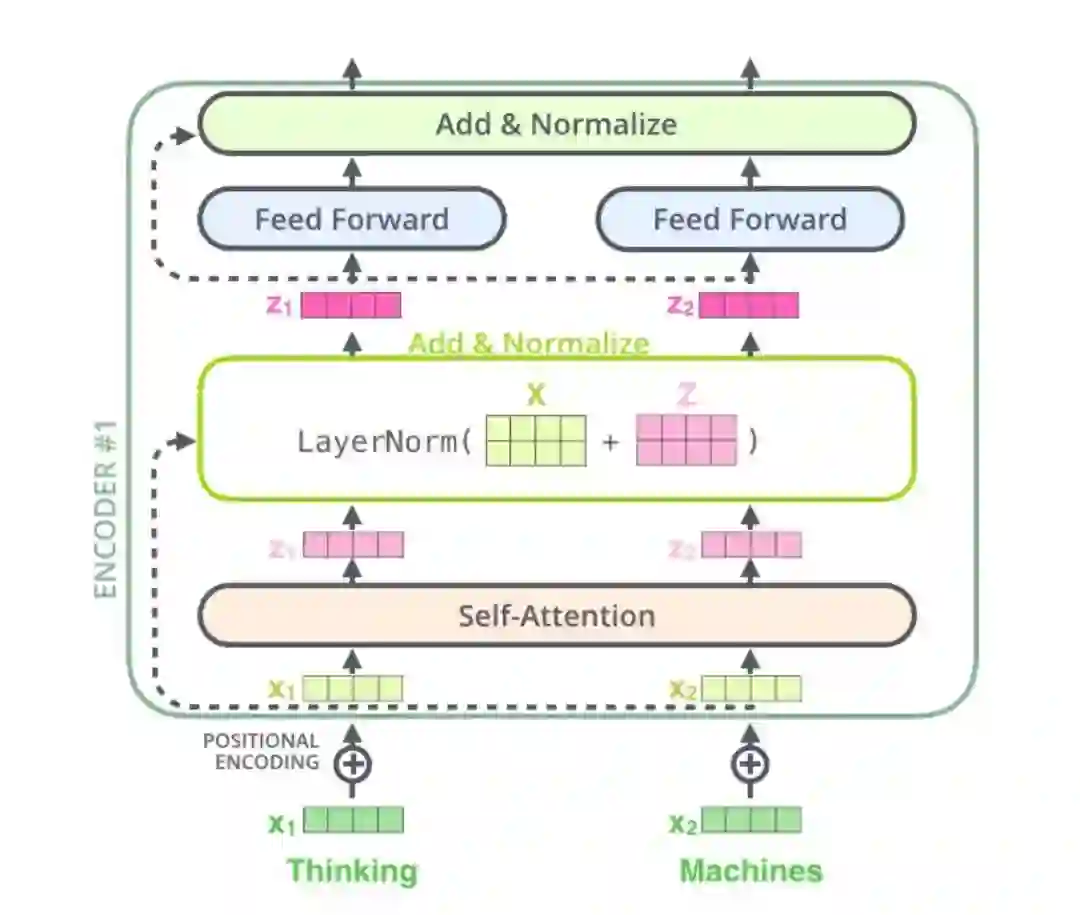
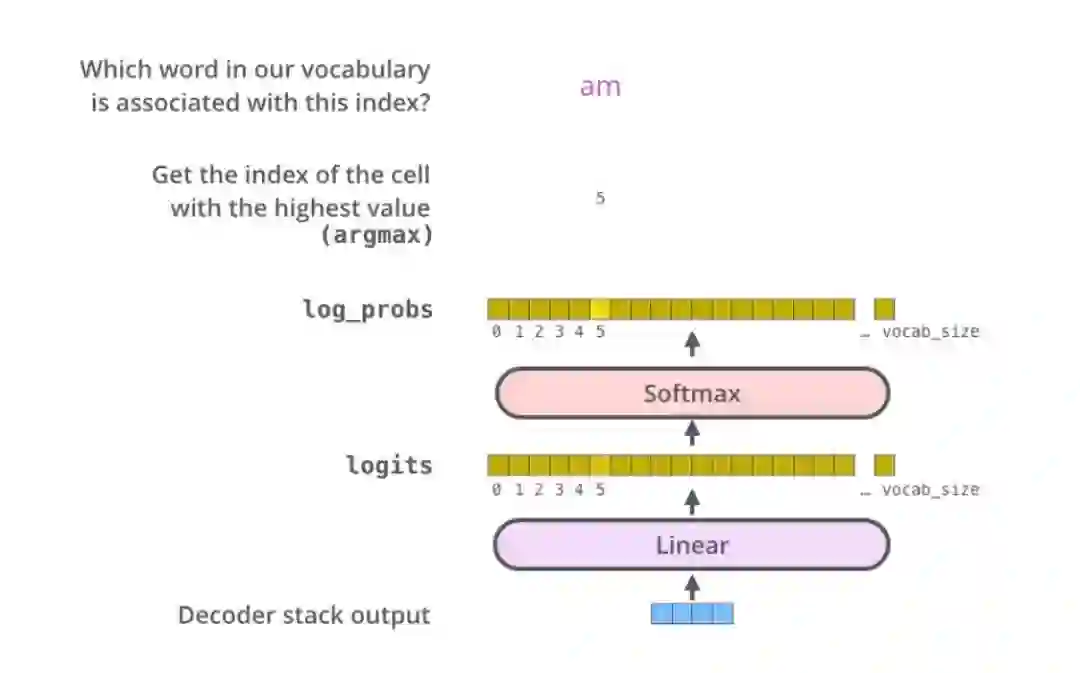
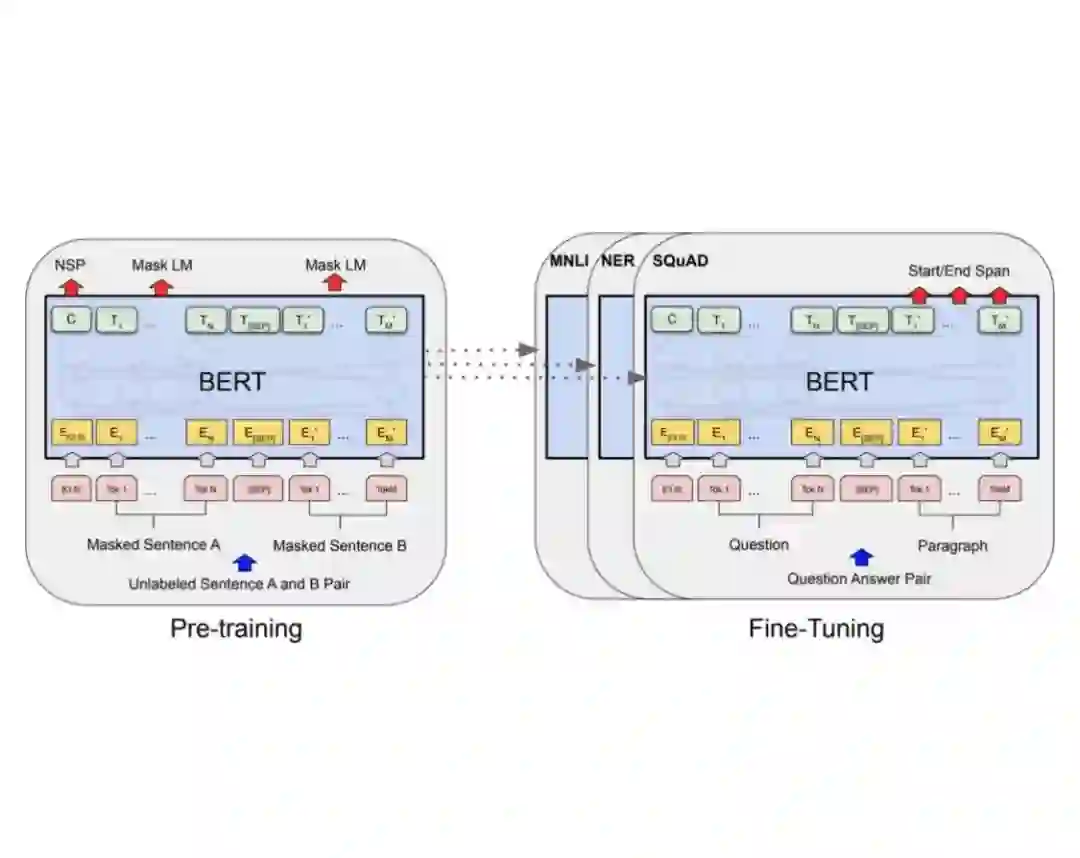
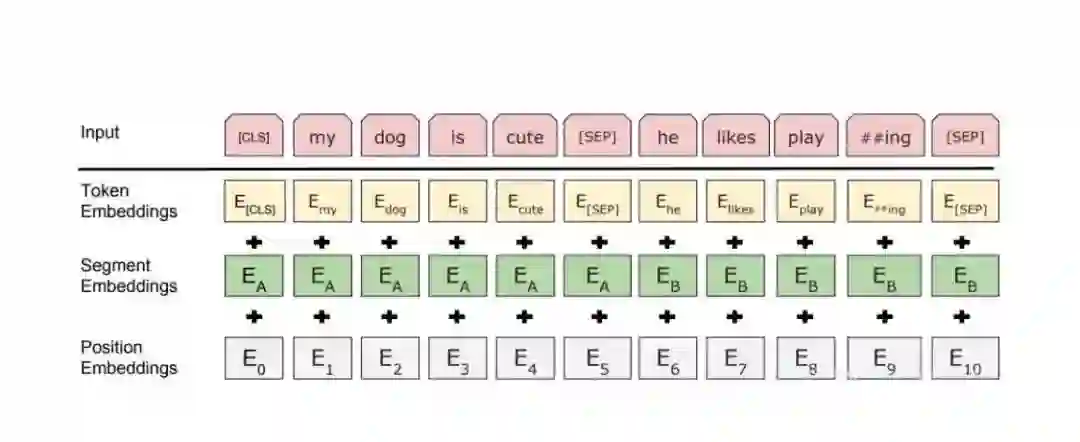
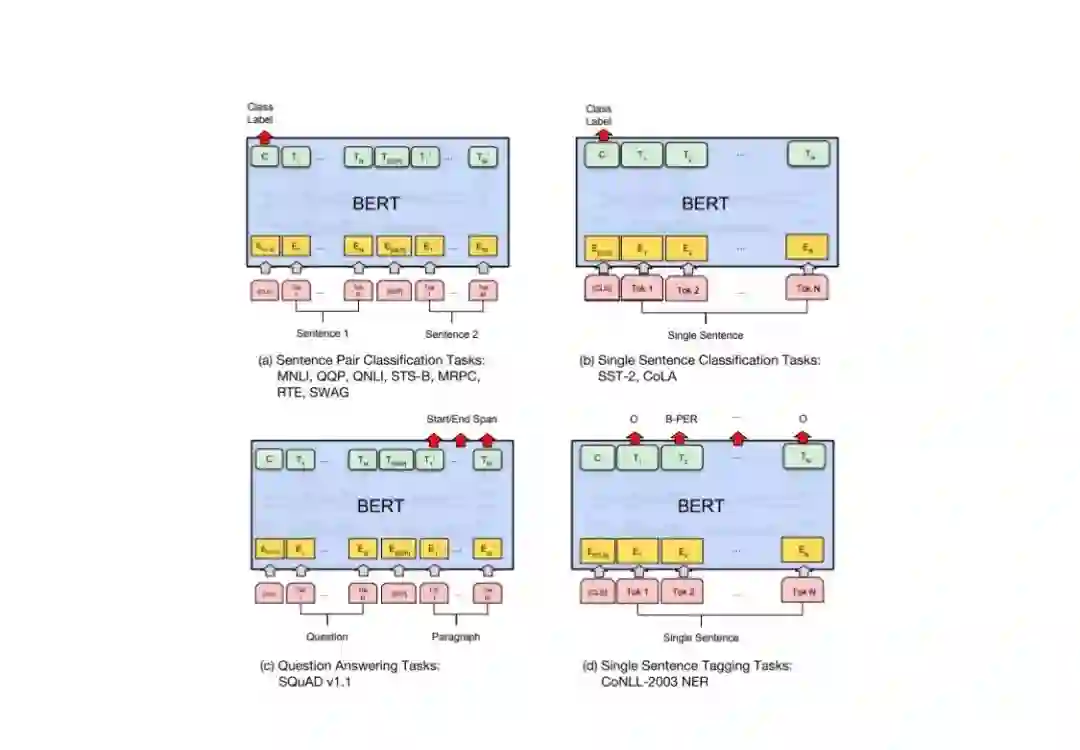
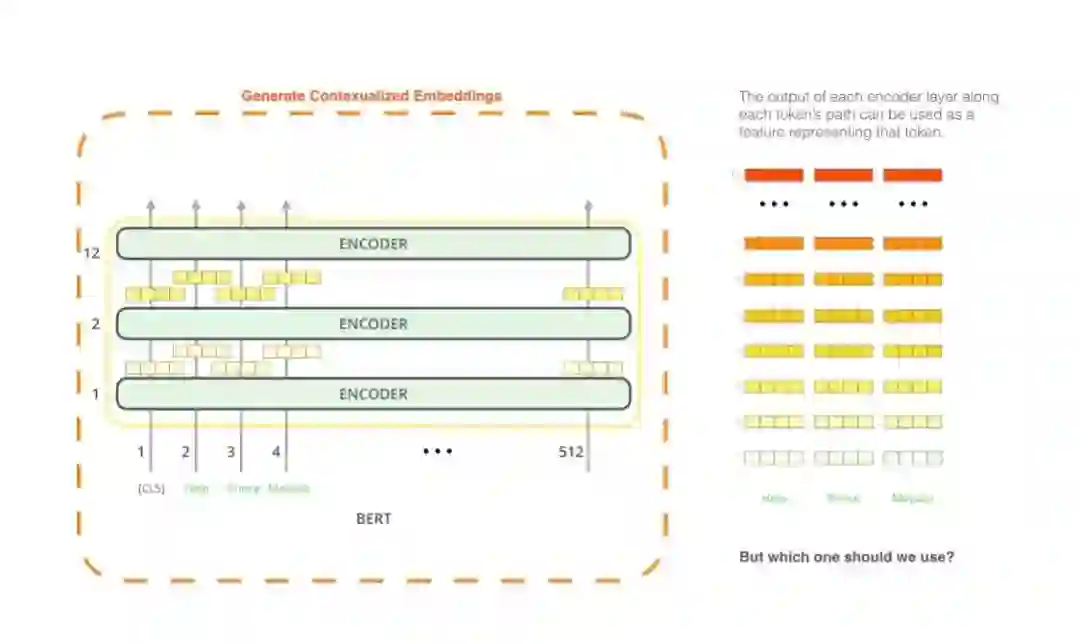
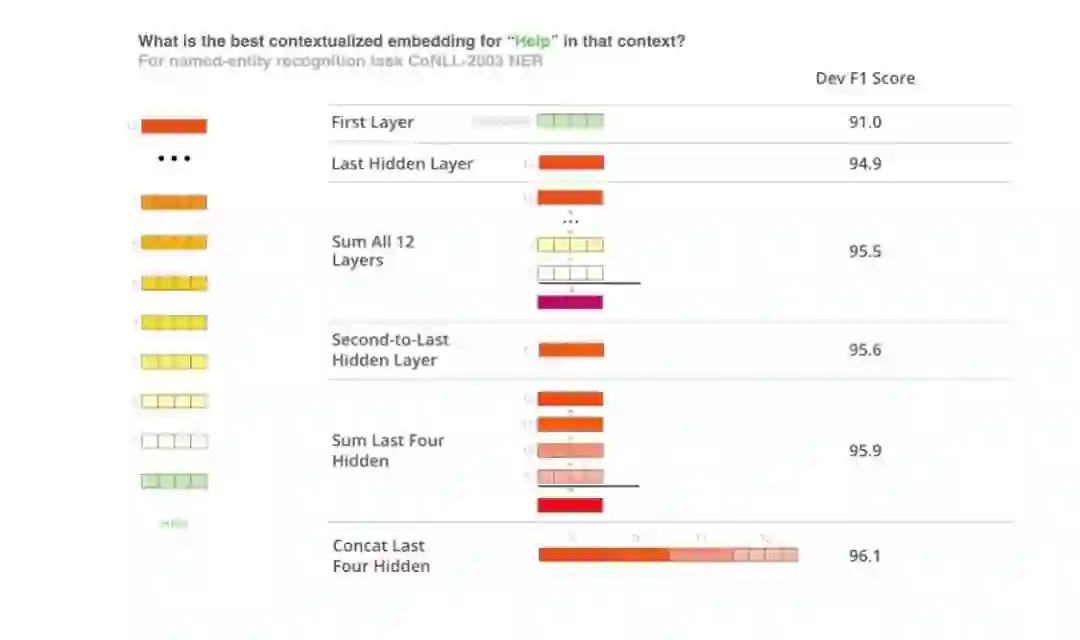
登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日
Arxiv
15+阅读 · 2018年10月11日



相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日