基于随机森林的分类与回归


作者:吴健 中国科学院大学 R语言、统计学爱好者,尤其擅长R语言和Arcgis在生态领域的应用分享
个人公众号:统计与编程语言
一、随机森林基本概念
随机森林(Random forest) 是一种组成式的有监督学习方法。在随机森林中,我们同时生成多个预测模型,并将模型的结果汇总以提升预测模型的准确率。
随机森林算法(预测和回归)主要包括一下三个方面:
1.从原始数据随机有放回的抽取N个样本单元,生成决策或者回归树。
2.在每一个节点随机抽取m<M个变量,将其作为分割节点的候选变量。每一个节点处变量数应该一致。
3.最终对每一颗决策或者回归树的结果进行整合,生成预测值。
二、随机森林的优势
1.在没有验证数据集的时候,可以计算袋外预测误差(生成树时没有用到的样本点所对应的类别可由生成的树估计,与其真实类别比较即可得到袋外预测)。
2.随机森林可以计算变量的重要性。
3.计算不同数据点之间的距离,从而进行非监督分类。
三、随机森林R语言实例
如果数据集的响应变量为类别型,则随机森林根据预测变量预测一个分类结果;如果数据集的响应变量为连续型,则随机森林根据预测变量进行回归。
1.利用随机森林预测一个分类结果
加载程序包
library(randomForest)
library(MASS)加载数据
data(fgl)
str(fgl)为保证结果大家运算结果一致 设定随机种子
set.seed(17)
构建随机森林模型 mtry参数表征默认在每个节点抽取的变量数
fgl.rf<- randomForest(type ~ .,data=fgl, mtry=2, importance=TRUE,
do.trace=100)
fgl.rf
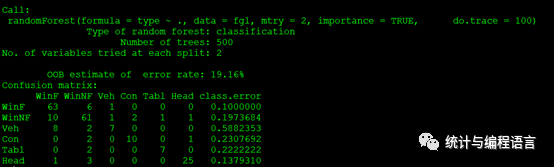
混淆矩阵结果可以看出随机森林对各类别的分类效果。
采用十折交叉验证对比随机森林与支持向量机的误差。十折交叉验证:用来测试精度。是常用的精度测试方法。将数据集分成十分,轮流将其中9份做训练1份做测试,10次的结果的均值作为对算法精度的估计,一般还需要进行多次10倍交叉验证求均值,例如10次10倍交叉验证,更精确一点。
library(ipred)
set.seed(131)
error.RF<- numeric(10)
for(iin 1:10) error.RF[i] <-
errorest(type ~ ., data = fgl,
model = randomForest, mtry = 2)$error
summary(error.RF)
library(e1071)
set.seed(563)
error.SVM<- numeric(10)
for(i in 1:10) error.SVM[i] <-
errorest(type ~ ., data = fgl,
model = svm, cost = 10, gamma = 1.5)$error
summary(error.SVM)


从结果中可以看出随机森林的误差要小于支持向量机模型
查看变量重要性
imp<- as.data.frame(fgl.rf$importance)
head(imp)
attach(imp)
par(mfrow= c(2, 2))
for(i in 1:4){
data <-imp[order(imp[,i],decreasing=T),]
plot(data[,i],type = “h”, main =paste(“Measure”, i), ylab=””, xaxt=”n”)
text(data[,i],rownames(data),cex=0.6,pos=4,col=”red”)
}
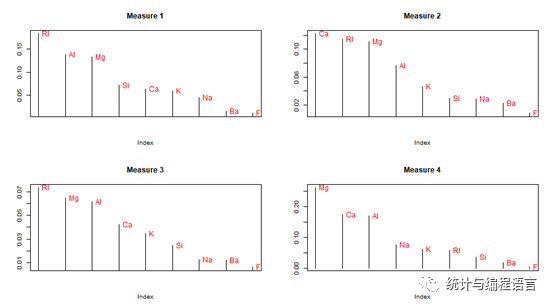
由上图可以看出不同变量在预测不同类别时的重要性
2.基于随机森林回归分析
首先,我们先注意一下随机森林回归和随机森林分类的差别:(1)默认mtry是p/3而不是p1/2,其中p表示预测变量数(2)默认节点大小为5而不是1(3)只有一个测量变量的重要性。
data(Boston)
set.seed(1341)
BH.rf<- randomForest(medv ~ ., Boston)
BH.rf

由上图可以看出随机森林回归模型结果的方差解释量
对比随机森林预测结果、多元回归预测结果和实际值的差异
forest.pred<- predict(BH.rf, Boston)
fit<- lm(medv ~ ., Boston)
lm.pred<-predict(fit,Boston)
data<- data.frame(Boston$medv, forest.pred1, lm.pred1)
head(data)
library(car)
png(filename= “lm.png”, width = 900, height = 500)
scatterplotMatrix(data)
dev.off()
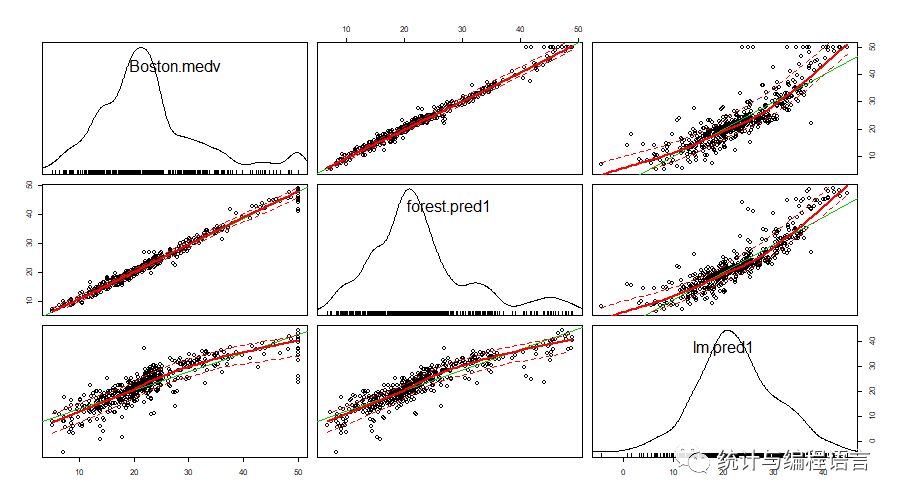
由上图可以看出随机森林结果要优于多元回归模型。
3.随机森林中需要注意的地方:
3.1合理确定决策树的数量。
3.2合理确定每个节点随机抽取的变量数
3.3决策树数量越多,结果越稳定。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享




