【泡泡一分钟】重投影再思考:位姿已知的情况下,从单张图片实现形状重建(ICCV2017-7)
每天一分钟,带你读遍机器人顶级会议文章
标题:Rethinking Reprojection: Closing the Loop for Pose-aware Shape Reconstruction from a Single Image
作者:Rui Zhu, Hamed Kiani, Galoogahi, Chaoyang Wang, Simon Lucey
来源:ICCV 2017 ( IEEE International Conference on Computer Vision )
播音员:朱英
编译:杨雨生
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

从单张图片中恢复物体的三维形状和位姿是计算机视觉领域新兴的研究方向。到目前为止,这个问题的解决方法通常是采用深度学习策略,直接从图片得到三维形状和位姿标签。这些方法存在两个问题。第一,他们在最小化三维形状和位姿标签的误差的过程中,当将对象重投影到图片上时,很少考虑到标签本身的误差;第二,这些工作依赖于一个繁重的前提,需要手动标注图片中对象的三维形状和其位姿。本文的主要研究内容是,从单张图片中,根据对象已知的位姿对对象的形状进行重构;只需要利用原始图片上,对象轮廓的二维标注,就可以实现。作者通过不同的对象种类来对算法进行评估,证明了其算法的优越性。:
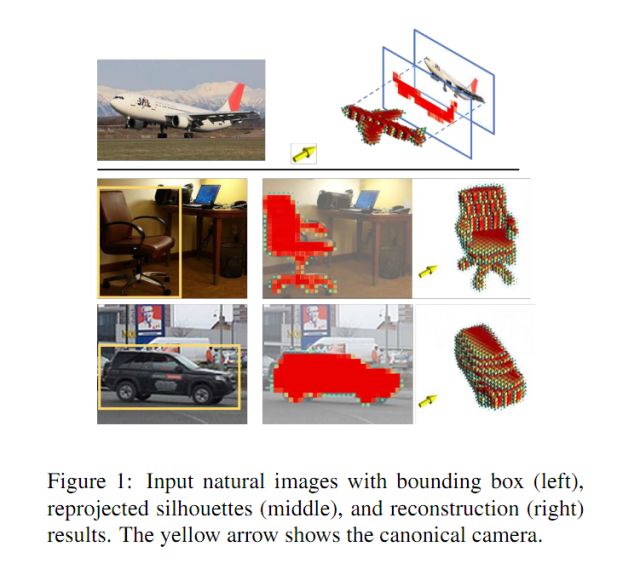
图1是作者论文的主要实现内容,从图中可以看出,神经网络的输入是带有二维轮廓标注的图片,中间图片显示的是得到的三维形状在原始图片上的重投影,最右侧图片显示的是三维重构的结果,以体素化的形式显示。
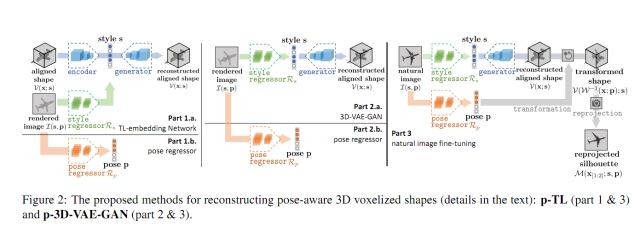
图2是论文算法的主要结构,与之前方法的不同在于。1,在训练时,不仅可以通过有标注轮廓的图片进行训练,还可以利用rendered image-shape pairs进行训练;2,不同于只能输出特定角度下的三维体素化形状,论文的方法可以输出对象在6个自由度下的形状;3,在训练深度神经网络时,损失函数(loss)采用重投影误差会有更好的效果。
Abstract
An emerging problem in computer vision is the reconstruction of 3D shape and pose of an object from a single image. Hitherto, the problem has been addressed through the application of canonical deep learning methods to regress from the image directly to the 3D shape and pose labels. These approaches, however, are problematic from two perspectives. First, they are minimizing the error between 3D shapes and pose labels - with little thought about the nature of this “label error” when reprojecting the shape back onto the image. Second, they rely on the onerous and ill-posed task of hand labeling natural images with respect to 3D shape and pose. In this paper we define the new task of pose-aware shape reconstruction from a single image, and we advocate that cheaper 2D annotations of objects silhouettes in natural images can be utilized. We design architectures of pose-aware shape reconstruction which reproject the predicted shape back on to the image using the predicted pose. Our evaluation on several object categories demonstrates the superiority of our method for predicting pose-aware 3D shapes from natural images.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
百度网盘链接:
链接:https://pan.baidu.com/s/1fY1oMxaFaJHctHvF80jrOw 密码:tqfs
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



