调试 NLP 模型的语义等价对抗规则
好久没粗现,诈尸一下 ಠ౪ಠ —— rumor

-
原论文:Semantically Equivalent Adversarial Rules for Debugging NLP Models -
出处:ACL 2018
摘要
用于 NLP 的复杂机器学习模型通常很脆弱,可能对语义上极其相似的输入实例做出不同的预测。
为了自动检测单个实例的这种行为,作者提出了语义等价对抗(SEAs)——语义保留的扰动,这些扰动会引起模型预测的变化。作者将这些对抗概括为语义等价的对抗规则(SEARs)——简单的、通用的替换规则,可以在许多实例上诱导模型。
作者通过检测三个领域的黑盒式 SOTA 模型中的错误来证明 SEAs 和SEARs 的有用性和灵活性,这三个领域分别是机器理解、视觉问题回答和情感分析。
通过用户研究,作者证明了可以为更多的实例生成高质量的局部对抗样本,而且 SEARs 产生的错误是人类专家发现的错误的四倍。SEARs 也是可操作的:重新训练模型、使用数据增强,可以显著减少错误,同时保持准确性。
1 介绍

分类、机器阅读理解、视觉问答的调试过程正在变得越来越困难。解析同一个句子的不同方法,通常导致模型输出不同的预测。虽然留出法的准确率通常很有用,但它并不足够。
测试数据通常是和训练数据、验证数据以相同的方式生成的。但是,当这些看似准确的模型被部署时,它们可能遇到与训练数据截然不同的句子。语言的多变性和注解的成本和噪音,使得这样的问题很难被检测,并被修复。
一个特殊的挑战是模型过于敏感,即模型针对非常类似的输入做出不同的预测。
受启发于图像的对抗样本,作者引入了语义等价的对抗攻击。文本的输入以语义保留的方式被扰动,并对黑盒模型的预测产生影响,例如图 1。作者认为,系统性地制作这样的对抗性样本可以极大地帮助调试 ML 模型,因为它可以让用户发现真实世界中发生的问题,而不是只对故意扰乱、拼写错误或删除单词等恶意攻击过度敏感。
局部性错误与全局性错误
虽然 SEA 描述的是局部的脆弱性(即针对特定的预测),但作者也对影响模型的全局性的错误感兴趣。作者通过简单的替换规则来表示这些问题,这些规则可以诱导多个 SEA,例如在图2中,在 Wh 代词(what,who,whom)(2b)后简单地缩写 "is",使得 70 个(1%)之前正确的模型预测变得不正确。也许更令人惊讶的是,添加一个简单的 "?" 会在 3% 的例子中诱发错误。作者将这种规则称为语义等价对抗规则(SEARs)。
在该文中,作者提出 SEA 和 SEAR,旨在揭示 NLP 模型中的局部和全局过敏性错误。作者首先提出了一种基于转述生成技术生成语义等价对抗样本的方法,该方法是模型无关的(即适用于任何黑盒模型)。接下来,作者将 SEA 泛化为语义等价的规则,并概述了最优规则集的属性:语义等价、高对抗数和非冗余性。
作者将寻找这样一个集合的问题框定为一个子模态优化问题,从而得到一个准确而高效的算法。
将人类纳入到这个循环中,作者通过用户研究证明SEARs可以帮助用户在不同任务(情感分类、视觉问答)的各种最先进的模型上发现重要的错误。作者的实验表明,SEAs 和 SEARs 使人类在检测有影响的 bug 方面有了显著的提高—— SEARs 在更短的时间内发现了比人类生成的规则多 3 到 4 倍的错误。最后,作者表明 SEARs 是可操作的,使人类能够通过使用数据增强程序修复发现的 bug 来结束循环。
2 语义等价对抗样本
考虑一个黑盒模型 f,它接受一个句子 x,并做出一个预测 f(x),我们要对其进行调试。我们通过生成 x 的转述,并从 f 中得到预测,直到改变原始预测,从而识别对抗样本。
给定一个指示函数 SeqEq(x, x'),如果 x 和 x‘ 等价返回 1,不等价返回 0. 我们将语义等价对抗样本(SEA)定义为改变等式(1)中模型预测的语义等价实例。这样的对抗样本在评估 f 的鲁棒性方面非常重要,因为每个对抗样本都是一个不理想的 bug。
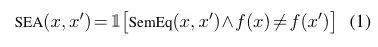
虽然有各种方法基于嵌入对文本之间的语义相似性进行评分,但它们并没有明确惩罚不自然的句子,而且生成句子需要周围的上下文或训练一个单独的模型。作者则转向基于神经机器翻译的转述法。将问句翻译为多种枢纽语言,然后取翻译文本回译为原文的分数作为语义相似性的评分。这种方法同时对语义和 "可信度 "进行打分(因为翻译模型有 "内置 "的语言模型),并且在回译时将每个回译器的路径进行线性组合,可以轻松生成转述。
不幸的是,给定源句 x 和 z,P(x′|x) 与 P(z′|z) 不具有可比性,因为每一个都有不同的归一化常数,并且严重依赖于 x 或 z 附近的分布形状。如果在 x 附近有多个完美的转述,它们都将共享概率质量,而如果在 z 附近有一个比其他的转述好得多的转述,它将比 x 附近的转述有更高的得分,即使转述质量相同。因此,作者将语义得分 S(x, x′) 定义为转述的概率与句子本身的概率之比。
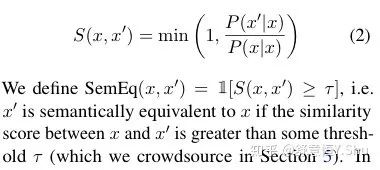
3 语义等价对抗规则
虽然为一个特定的实例找到最好的对抗样本是有用的,但人类可能没有时间或耐心去检查太多 SEA,而且可能无法很好地从它们中归纳出最有影响的 bug 来理解和修复。
在本节中,作者将解决将局部对抗样本泛化为文本语义等价对抗规则(SEARs)的问题,即搜索和替换规则,当应用于句子的语料库时,这些规则可以产生语义上几乎没有变化或没有变化的语义对抗样本。假设人类的时间有限,因此愿意看 B 条规则,作者提出了一种给定参考数据集 X 的方法来选择这样一组规则。

一个语义等价的替代规则的形式是 r = (a→c),其中每一个包含 a 的实例都会用结果 c 代替,如我们之前在图 2a 中说明的那样。对句子 x 应用规则 r 后的输出表示为函数调用 r(x),例如,如果 r = (movie→film),r("Great movie!")="Great film!"。


提出规则集合:为了将语义等价对抗样本 x' 泛化到候选规则,我们必须表示 x 到 x' 的变化。作者以图 4 作为 running example。
一种找到候选规则的方法是精确匹配:选择最小的连续序列,将 x 变成x′,例如样例中的 (What→Which)。这样的变化可能并不总是语义不变的,所以作者还提出了进一步的规则,包括直接的上下文(相对于序列的上一个和/或下一个词),例如(What color→Which color)。
然而,添加这样的上下文可能会使规则变得非常具体,从而限制了它们的价值。为了允许泛化,作者还用它们的原始文本与粗粒度和细粒度的词性标签的乘积来表示所提出的规则的前因,并允许这些标签在与前因匹配的情况下发生在后果中。在 running example 中,作者会提出(What color→Which color)、(What NOUN→Which NOUN)、(WP color→Which color)等规则。
作者为每一个 x ∈ X 生成 SEA 并提出规则,这就得到了一组候选规则(图4中的第二个方框,为算法1中的循环)。
选择规则集合:给定一组候选规则,我们想要选择一个 R,使得 |R| ≤ B,并且满足以下属性:
-
语义等价性:集合中规则的应用应产生语义上等效的实例。即考虑具有很高的概率诱发语义等价实例的规则。这就是算法 1 中的 “过滤” 步骤。例如,考虑图 4 中的规则(What→Which),该规则产生一些语义等价的实例,但也产生许多不自然的实例(例如“What is he doing?”→ “Which is he doing?”,因此被该标准过滤掉了。 -
高对抗计数:集合中规则应在验证数据中引入尽可能多的 SEA。此外,每个诱导的 SEA 应该具有尽可能高的语义相似性得分。 -
无冗余:集合中的不同规则可能会引发相同的 SEA,或者可能会为相同实例引发不同的 SEA。理想情况下,集合中的规则应涵盖验证中的尽可能多的实例,而不是专注于一小部分脆弱的预测。此外,规则不应对用户重复。
局限与未来工作
-
语义评分错误:转述仍然是研究的活跃领域,作者的语义评分函数有时在评估语义等价规则时是不正确的。存在此类错误导致我们仍然需要人工参与以接受或拒绝 SEAR。 -
其他转述局限:基于神经机器翻译的转译模型倾向于保持句子结构,因此不会产生某些对抗样本,最近这些转译的工作尝试使用 GAN。更重要的是,现有模型对于长文本不准确,从而将 SEA 和 SEAR 限制为句子。 -
更好的漏洞修复:作者的数据增强使人类用户根据模型是否保留语义来接受/拒绝规则。开发更有效的方式来利用专家的时间来封闭环路,并促进人类与 SEAR 之间的互动,这是未来工作的令人兴奋的领域。
结论
作者介绍了 SEA 和 SEAR:对抗性示例和规则,这些示例和规则保留了语义,同时可以导致模型出错。
作者提供了在各种任务的最新模型中发现的此类错误的示例,并通过用户研究证明,非专家和专家都可以通过使用该方法更好地检测 NLP 模型中的局部和全局错误。
作者还通过提出一种简单的数据增强解决方案来闭合环路,该解决方案可以在保持准确性的同时大大降低模型过高的灵敏度。作者证明了SEA和SEAR是调试NLP模型的宝贵工具,同时指出了它们当前的局限性和未来工作的途径。

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


