京东 AI Fashion-Challenge 挑战赛冠军方案详解(风格识别+时尚单品搜索)

AI 科技评论按:随着消费升级时代的来临,中国时尚消费市场正渐渐变得更加个性化、精致化和多样化,服饰的时尚风格对消费动机的影响愈渐加深,而随着 AI 技术的发展,AI 也越来越多地被应用于时尚领域。
基于以上原因,京东集团 AI 平台与研究院推出与时尚相关的 AI Fashion-Challenge 挑战赛,该项赛事包括时尚风格识别和时尚单品搜索两个子任务。

对于风格识别赛道,主要面临两大难题,一是基于京东真实数据集的样本差异非常明显,二是时尚还面临主观性和专业性问题,是非常具有难度的多标签分类任务之一。本次竞赛邀请了专业时尚设计界人士,在设计师指导下标注了大量京东的女装商品照片的整体时尚风格,共分为 13 类风格。
另一个赛道是时尚单品搜索,这是时尚领域比较常见的视觉搜索任务,除了前面提到的主观性挑战,图片中的物体具有不规则的特性,角度和形状也具有多样性,这也都为解决本问题带来巨大挑战。
据京东 AI 平台与研究部叶韵博士介绍,本次比赛共有 212 支队伍报名,52 支队伍提交结果,共收到 12 份技术报告,参赛人员来自 6 个不同国家和地区,涵盖 196 所大学和研究所,包含 31 家公司。最终,「西天取京」队以 0.6834 F2 Score 获得时尚风格识别子赛道冠军,「Fashion_First」队以 0.5886 mAP 获得时尚单品搜索子赛道冠军。
「西天取京」队成员如下:
丁煌浩
dinghuanghao@gmail.com
万辉
wanhui0729@gmail. com
「Fashion_First」队成员如下:
陈亮雨,中国科学院自动化研究所实习生
吴旭貌,中国科学院自动化研究所实习生
方治炜,中国科学院自动化研究所博士在读
刘静(带队老师),中国科学院自动化研究所研究员
以下为这两个赛道冠军方案:
风格识别赛道
本次竞赛开发数据包含 5.5 万张经过专业标注的真实京东时尚单品展示图,该数据用作模型训练及调优。 测试数据包括 1 万张经过专业标注的真实的京东时尚单品展示图。任务描述如下:给定一张时尚照片 I,参赛算法需要预测
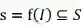
其中 S={运动,休闲,OL/通勤,日系,韩版,欧美,英伦,少女,名媛/淑女,简约,自然,街头/朋克, 民族}
工程方面:
以 Keras 作为基础框架,对其进行了一定的优化和封装,大大的加快了开发进度,具体如下:
采用 Config-Driven-Development 的开发方式,对所有的技术和参数进行封装,只用修改配置文件即可自动进行训练、评估、统计、集成。
扩展了 Keras 的数据加载器 ,使其支持 TTA、K-Fold Cross Validation。
将 Keras 的 Evaluate 方法改为异步,减少了训练的中断。
将 XGBoost 的参数分发到多台 PC 训练然后合并,缩短了训练时长。
模型:
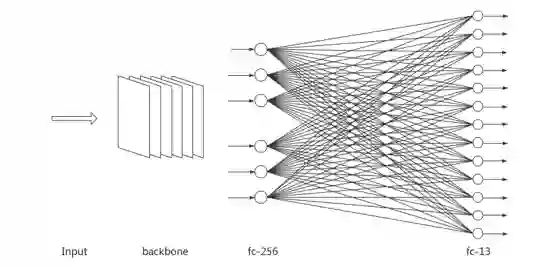
采用多种不同的 Backbone,包括 ResNet、Inception、Xception 等,后接两个 FC 层,分别为 256、13 个神经元(多隐层提升并不大),两层之间使用 BN,使用 Cross-Entropy Loss、Focal Loss 进行模型的训练。这种结构相当于构建了 Multi-task 学习,比起每个标签单独训练模型而言,速度更快,且精度更高。
数据增强:
使用了一些比较通用的方法,包括随机裁剪(横15%,纵10%)、拉伸(10%)、压缩(10%)、水平翻转。裁剪时考虑到人的比例,横向和竖向的裁剪比例不同,这样会有一定的提升。
除此之外,提出一种专门针对服装的变色方案:
使用 MASK-RCNN 分割出人像;
根据人像区域中的颜色比例,推测出服装的颜色;
对服装颜色在全局进行 HSV 变换。
这种方法的好处是变化的平滑以及自然,缺点是一定程度上影响了背景。最终,一共生产出大约 130K 图片,考虑到计算量,并没有全部使用。
测试时,尝试了两种增强,一种是水平翻转,一种是裁剪(左上、左下、右上、右下、中央)。五种裁剪操作加上翻转一共有十种变换,虽然效果更好,但会有很大的性能损耗。最终仅采用了水平翻转,可以将结果提高一个百分点左右。
处理标签不均衡:
此次比赛的数据集存在严重的标签不均衡,数量差异可达 480 倍。主要采用了如下的四种方案来解决:
上采样:对所有稀疏标签相关样本进行上采样。因为这是一个多标签分类问题,虽然密集标签相关样本数量也会被连带进行部分上采样,但是比例会变得更均衡。
下采样:因为小标签本来就很少,如果再对它进行下采样,后果会更加严重,因此下采样时只对那些所有标签都是密集标签的样本进行下采样,不会影响到稀疏标签相关样本。
数据生成:使用前面提到的服装变色技术对稀疏标签相关样本进行变色。
优化损失函数:使用 Focal Loss(使用网格搜索法进行了简单的调参),提升了 1% 左右。如果与加权法相结合,应该会带来更好的效果(参考第二名)。
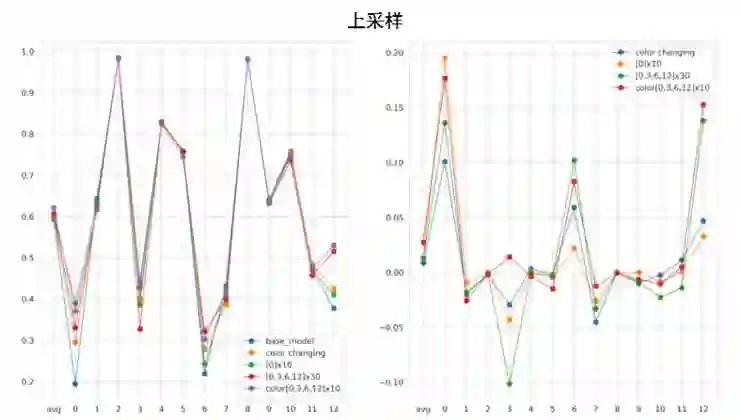
下图左边是上采样之后各个标签的 F2 score,右边是提升值。比赛中对 0,3,6,12 这四个标签进行了上采样,可以看到这四个标签平均提升值大约在 3.5% 左右。
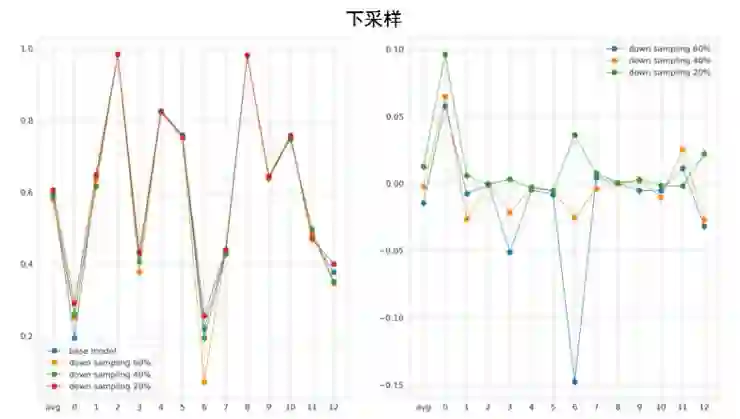
下采样过程中随机对样本进行删除,分别测试了 20%,40% 和 60% 的下采样,可以看到 20% 的时候效果最好。
调参:主要使用 Adam,batch-size 为 32,图像短边为 224(经测试,尺寸越大结果越好,但由于算力限制,仍以 224 为主),使用 Cyclic Learning Rate 和阶段性 Fine Tuning(以较大的学习率训练后几层,然后逐步增加训练的层数并减小学习率,最初始的几层不进行训练),这可以加快速度,并提高准确率。
阈值搜索:
由于每个标签的概率分布不同,因此需要不同的阈值(如某些数量较小的标签,输出值往往低于 0.5,而数量较多的标签输出值大于 0.5)。
我们尝试了三种方案:第一是固定阈值,人为根据概率分布去筛选阈值。第二,用 L-BFGS 去搜索,第三,只用了贪心搜索。最后得出来的结果是,固定阈值效果较差,L-BFGS 和贪心搜索差异不大,但贪心搜索更快,也更稳定。
为了验证 CV 集上贪心搜索的泛化能力,我们在后来官方公布的测试集上也进行了搜索,并进行了对比,发现 CV 上的阈值和 TEST 上的阈值之间的差异小于 0.1,而且是类似正态分布。不管是密集标签还是稀疏标签,都是这样的分布,可见贪心搜索算法在本任务中有较好的泛化能力。
模型集成:
模型集成的关键主要是在于模型的「好而不同」,即模型效果首先要效果好,还要具有多样化。我们使用如下方法来实现:
第一,使用了多种优秀的 backbone网络,包括ResNet、Inception、Xception、DenseNet 等;
第二,针对每个模型,在训练过程中对参数、数据集进行微扰;
第三,我们计算了所有模型的模型相关度,筛选掉相关性大于 90% 的模型。
第四,基于每个标签独立挑选最优秀的模型。由于训练过程中,不同标签到达最优的 epoch 不同,因此我们以标签为单位根据 F2-Score 对所有模型的所有 epoch 进行统一排序,并挑选 Top-N 模型。
集成方法是使用 Stacking + Bagging 进行集成。训练阶段,首先使用 5-fold validation 训练大量 CNN 模型,并将所有 fold 的预测拼接在一起构成新的数据集输入到XGBoost 中,同样使用 5-fold validation 训练 XGBoost。预测阶段,将图片输入 5-fold 的 CNN 网络,然后再分别输入到 5-fold 的 XGBoost,最后通过投票的方式得到最终输出。
详细信息参见:
http://u6.gg/eHUwa
时尚单品搜索
任务:给定一个大规模时尚单品的电商展示图集合 S,其中每个时尚商品都属于{上衣, 鞋子,箱包}中的某一类。对于任意一张时尚单品的用户实拍图 q,都存在一个与之相匹配的电商展示图集合
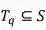
本赛中,设定任意的用户实拍图 q 都至少存在一张商品同款图在S中。参赛算法需把 S 中的电商展示图依照与 q 的相似度降序排列,提交前10的最相似图片。
本次比赛的难点主要有两方面:第一,商品匹配的细节化,这意味着两个商品图片是否匹配,其关键点往往取决于某几个局部细节的异同。第二,商品成像角度的多样性。任意一件商品都可能从任意一个角度被呈现出来,这会导致匹配的商品图像视觉特征差异很大。
近几年,随着深度学习的发展,图像检索的研究也随之被大大推进。卷积神经网络在解决光照、尺度、纹理等问题上面展现出很强的优越性。但是对于本赛事中的商品检索任务所面临的上述两个问题,却仍然是一个极大的挑战。在本次比赛中,Fashion_First 团队提出一种多粒度局部对齐神经网络,有效解决上述两个问题,使得商品检索的精度有了很大的提高。
此次冠军方案主要有以下两个亮点:
第一,构建了一个同时兼顾多粒度与局部对齐匹配的神经网络,在保证模型对全局信息的抓取能力的情况下,大大增强了对不同局部信息的表达能力。
第二,团队创造性地提出环形池化方法,在几乎不增加模型参数和计算量的情况下,使模型拥有旋转不变性特征的学习能力。
网络框架:
Fashion_First 采用的网络是 ResNet101,在训练模型之前,对检索库的图片进行了预分类,最后的效果将近 99%,符合使用需求。不同于现在大多数人使用基于度量 Loss 的网络,我们依旧把这一个任务看成一个分类问题,既简单又高效。
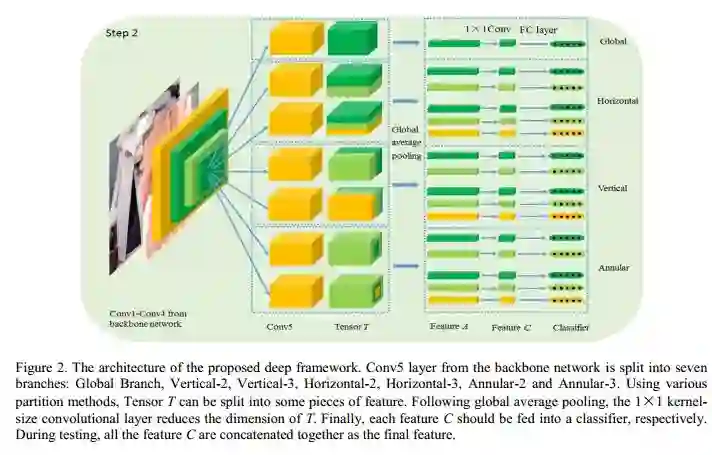
网络有四个分支:全局分支,横向分支,纵向分支以及环形分支。
全局分支负责学习全局特征,以保持模型对整体信息的抓取能力。横向分支主要学习具有水平方向的平移不变性的特征,为了能够在不同尺度上学习这一特征,模型对特征图在水平方向上进行不同粒度的切分:一个均分为两等分,一个均分为三等分。最终水平方向会产生 5 个局部特征,每个局部特征都会经过平均池化和最大值池化以及一个 1x1 卷积后用于商品分类器的训练。类似地,纵向分支的目的是学习具有垂直方向平移不变性的特征。
与上面不同的是环形分支,其任务是学习具有旋转不变性的特征。与 STN 和可变卷积不同,Fashion_First 团队提出环形池化方法,不需要额外参数,即可保持旋转不变性。其具体做法是对原始特征图从中心开始,按照不同半径,提取环形特征子图(实际操作采用方环形而非圆环形的方式提取)进行均值池化和最大值池化,然后相加起来。这种方式在理论上可以轻松保持 360 度的旋转不变性,并且在试验中也取得了很好的效果。
上述四个分支构成多粒度的局部对齐神经网络,训练过程简单高效,检索结果性能优异,取得了本次赛事单品搜索任务的第一名。
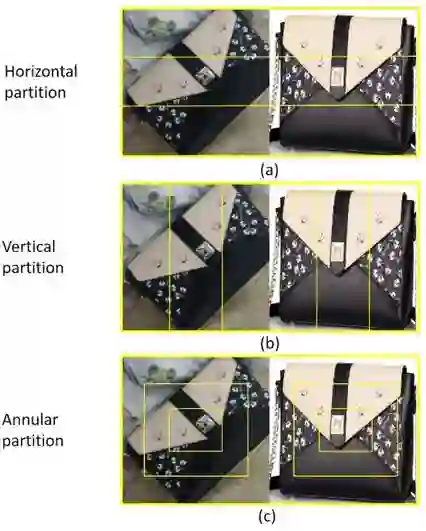
实现细节:
此次比赛在参数的设定上,整体的 Loss 值使用各个分支的交叉熵 Loss 的和,输入图片的尺寸为 384×384。在训练过程中,batch size 最初设置为 64,Adam 优化器的初始学习率设置为 0.06,在 20 个 epoch 的时候衰减到 0.012,大概在 55-60 epoch,可以得到收敛。
以下是实验结果,可以看到水平、垂直和环形三种方式的对比,环形相较另外两种方式能得到很大的提升,另外不同的主干网络得到的结果也有着较大的差异。
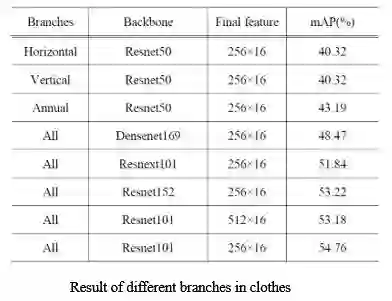
比赛的最后阶段主要进行的是模型融合,相似网络结构的模型融合的提升效果一般。主要融合的模型有四个 Resnet101, Resnet152, Resnext101 和 Densenet169,最后得到的 mAP 为 0.55886,与单模型相比有着 2 个点的提升。
详细信息可以参见:
https://fashion-challenge.github.io/fashion_first.pdf
比赛更多信息:
https://fashion-challenge.github.io/#index




