Batch Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
本文参考文献
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
被引次数:1658
目前主流的训练深度神经网络的算法是梯度下降算法,简而言之该过程就是通过将网络输出值与真实值之间的误差信号逐层传递至神经网络的每个节点,进而更新节点与节点之间的参数。
尽管在大数据时代,采取深度神经网络进行数据建模会变得非常优越,深度神经网络的调参过程一直是受人诟病的地方。论文中通常不会直接给出一组性能较好的参数是怎么得到的,而是直接给出模型的结果。这就使得深度神经网络的调参过程在没有经验的人看来是一个black box。
随着梯度下降算法的不断改进,已经有越来越多的算法尝试减少调参的工作量,比如减小学习率、选取合适的权重初始化函数、应用Dropout等等,而我们今天要介绍的Batch Normalization也是一个加速神经网络训练过程的算法,帮助减少调参的弯路。这个算法在2015年由Google提出,一提出便被广泛接纳采用,可以发现,现如今基本上所有的深度神经网络模型中都会加入Batch Normalization技巧。短短两年,这篇文章就已经被引用了1658次,实属2015年深度学习领域的顶级优质文章。
1. 为什么要提出Batch Normalization
首先论文中给出了一个名词covariate shift,文中指出,在深度神经网络里面,正是covariate shift导致了神经网络训练起来比较缓慢,而ReLU的发明也是为了减少covariate shift,较少covariate shift就可以提高神经网络的训练速度。
covariate shift简单来说就是当你训练好了一个函数,输入的分布变了,这个函数就无法处理了。举个例子,现在想建立一个可以用来预测癌症的分类器模型,首先我们从医院里患有癌症的老年人中抽取血液,但是仅有这些样本肯定不行,因为我们缺少健康的样本,于是我们去学校里找了一些年轻的学生志愿献血得到了健康样本的模型,这样我们就可以利用逻辑回归进行分类了是不是?训练好的模型真的就可以直接投放市场应用到病人身上了吗?
显然不是的,很大概率上这个模型会表现不好,原因就在于我们病人的样本和学生的样本分布根本不同,也就是说训练集样本的分布跟测试集样本的分布不同,即样本之间存在了covariate shift。
虽然我们本意是要学习P(癌症|血液)的概率分布,但是我们无法真正学习到这个分布,而在很大程度上我们学习的是P(癌症|血液,学生),也就是说我们这个模型是依赖于输入样本的分布的。
那么在深度神经网络中,所谓的internal covariate shift该如何理解呢?
如果神经网络的层数很浅的话,其实这个问题不大,因为采取随机的mini-batch训练方法,mini-batch之间的样本分布差别不会太大。但是对于深度神经网络而言(比如微软提出152层的residual network),由于其参数是逐层启发性的结构,因此,internal covariate shift的问题就不应该忽视了。在深度神经网络中,由于第一层参数的改变,导致了传递给第二层的输入的分布也会发生改变,也就是说在更新参数的过程中,无形中发生了internal covariate shift。因此,这样网络就很难较好的范化,训练起来也就非常缓慢了。
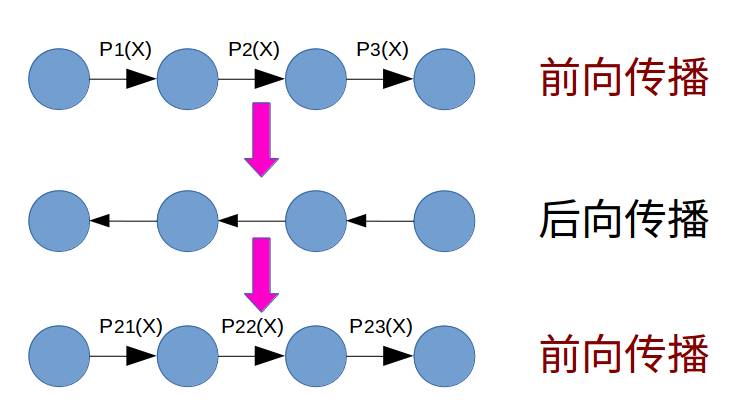
2. 什么是Batch Normalization
为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对每一层的输入做一个Batch Normalization 变换,该变换的操作如下图所示。

直观上理解,就是首先对每层的输入进行常规的归一化,然后再在此基础上添加一个仿射变换,容许输入变换到原来的规模。这里需要说明两点:
第一,这里的常规归一化实际上就是改变了一个mini-batch中样本的分本,由原来的某个分布转化成均值为0方差为1的标准分布;
第二,仅转化了分布还不行,因为转化过后可能改变了输入的取值范围,因此需要赋予一定的放缩和平移能力,即将归一化后的输入通过一个仿射变换的子网络。这里仿射变换中的gamma和beta都是可以学习的参数,不难发现如果gamma取输入的标准差,beta取输入的均值,Batch Normalization变换就回到了恒等变换。
第三,这里的所有操作都是可微分的,也就使得了梯度后向传播算法在这里变得可行;
跳过文中的梯度的推导公式,我们直接来看整个Batch Normalization算法,如下图所示,首先是训练Batch Normalized网络,然后再将其应用于推理阶段。

关于上图,有必要说明一个困惑的地方。细心的读者一定会发现上图中的第10步中Var[x]不是直接等于方差的期望,而是在前面添加了分数m/(m-1),这是为什么呢?
原因就在于我们的初衷是希望网络的输出只依赖于输入,而不是依赖于mini-batch的划分,之所以划分成mini-batch来进行训练,是因为这样做考虑到了实际情况,如果采取完整的batch训练,那是不现实的。
基于此,算法1中的方差只是一个mini-batch样本方差,但是在算法2中的推理阶段,我们要使用的应该是样本全局的方差,而不是拿一个部分来预测,而实际上我们也不知道整个数据集的期望值是多少,所以就拿mini-batch的均值来代替期望值,这样简单粗暴的做法就会使得我们估计的样本过于集中,也就是说我们估计的方差要比真实方差小一点,因此mini-batch中的方差实际上是低估了整个数据集的方差,我们要得到无偏估计,所以这里要乘以m/(m-1)稍稍放大一下方差的值,至于为什么不放大到其他值,为什么分母不是m-2或m-3,可以查阅更严格的数学证明。
原理部分就介绍到这里了,论文中给出了结合了Batch Normalization的CNN网络用于图像分类的效果,感兴趣的读者可以去阅读一下,至于Batch Normalization在RNN中的应用效果以及相应改进,我们后期会继续推送。
接下来动手在TensorFlow中实现Batch Normalization,由于TensorFlow中提供了非常方便的Batch Normalization的API,因此这里我只简单演示一下Batch Normalization变换的写法:
import tensorflow as tf
def bn_transform(x):
batch_mean, batch_var = tf.nn.moments(x,[0])
z_hat = (x - batch_mean) / tf.sqrt(batch_var + epsilon)
gamma = tf.Variable(tf.ones([100]))
beta = tf.Variable(tf.zeros([100]))
bn = gamma * z_hat + beta
y = tf.nn.sigmoid(bn)
return y在TensorFlow中,我们可以直接在层与层之间调用tf.layers.batch_normalization函数,该函数参数调用如下:
batch_normalization(
inputs,
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(),
beta_regularizer=None,
gamma_regularizer=None,
training=False,
trainable=True,
name=None,
reuse=None)在训练阶段我们只用设定training=True即可,在推理阶段,我们设置training=False即可,感兴趣的读者可以看看这个函数的内部实现源码。
题图:Pawel Kuczynski
你可能会感兴趣的文章有:
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创




