MIT发出「算力」警告:深度学习正在逼近计算极限
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
明天,极市平台将继续独家直播由山东大学主办的“可视计算”学术专题报告。国内外的知名学术专家,会就各自领域的基础理论、应用前景与前沿技术等方面进行专题报告。请大家锁定直播时间7月17日(星期五)—7月19日(星期日)。详情戳这里,在极市平台后台回复“61”,即可获取直播链接。
【导读】近日,MIT发出警告:深度学习正在接近计算极限,必须转变现有技术「大幅」提高计算效率。
深度学习的流行,本质原因都是人们对算力的追求。
近日,MIT却发出警告:深度学习正在接近计算极限,必须转变现有技术「大幅」提高计算效率。
根据麻省理工学院,安德伍德国际学院和巴西利亚大学的研究人员的说法,他们在最近的一项研究中发现,深度学习的进展「非常依赖」计算的增长。他们断言,不断的进步将需要通过改变现有技术或通过尚未发现的新方法来「戏剧性地」更有效地使用深度学习方法。

「我们的研究表明,深度学习的计算成本并非偶然,而是精心设计的。同样的灵活性使得它在建模各种现象和优于专家模型方面表现出色,也使得它的计算成本大大增加。尽管如此,我们发现深度学习模型的实际计算负担比理论上扩展得更快,这表明需要会有实质性的改进。」
深度学习是机器学习的一个子领域,研究的是受大脑结构和功能启发的算法。这些算法被称为人工神经网络,由排列成层的函数(神经元)组成,这些函数将信号传输给其他神经元。
这些信号是输入数据输入网络的产物,从一层传输到另一层,缓慢地「调整」网络,实际上就是调整每个连接的突触权重。网络最终学会了通过从数据集中提取特征和识别交叉样本的趋势来进行预测。
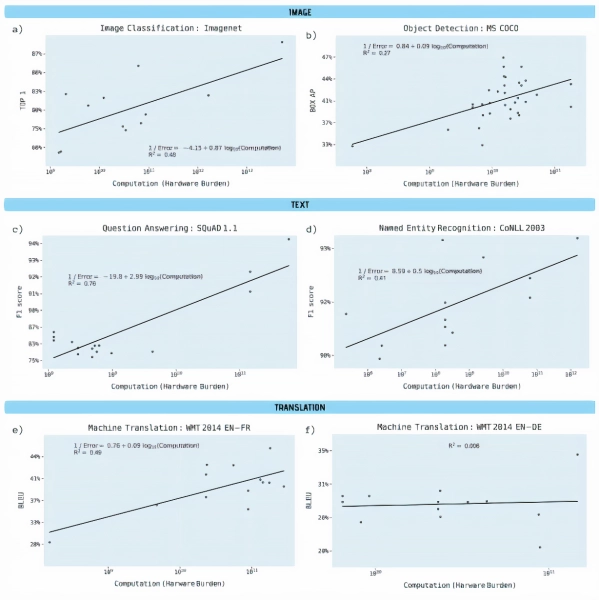
研究人员分析了预印本服务器Arxiv.org上的1058篇论文和其他基准资料,以理解深度学习性能和计算之间的联系,特别关注图像分类、目标检测、问题回答、命名实体识别和机器翻译等领域。他们分别对计算需求进行了两项分析,反映了可用的两类信息:
1、每一网络遍历的计算量,或给定深度学习模型中单次遍历(即权值调整)所需的浮点运算数。
2、硬件负担,或用于训练模型的硬件的计算能力,以处理器数量乘以计算速度和时间计算。(研究人员承认,虽然这是一种不精确的计算方法,但在他们分析的论文中,它的报道比其他基准要广泛得多。)
报告说,除从英语到德语的机器翻译(使用的计算能力几乎没有变化)外,所有基准均具有「统计学上显着性」的斜率和「强大的解释能力」。
对象检测,命名实体识别和机器翻译对于硬件的负担大幅增加,而结果的改善却相对较小,计算能力解释了流行的开源ImageNet基准测试中图像分类精度差异的43%。
研究人员估计,三年的算法改进相当于计算能力提高了10倍。他们写道:「总体而言,我们的结果清楚地表明,在深度学习的许多领域中,训练模型的进步取决于所使用的计算能力的大幅提高。」
「另一种可能性是,要改善算法本身可能需要互补地提高计算能力。」
在研究过程中,研究人员还对预测进行了推断,以了解达到各种理论基准所需的计算能力以及相关的经济和环境成本。即使是最乐观的计算,要降低ImageNet上的图像分类错误率,也需要进行100000次以上的计算。
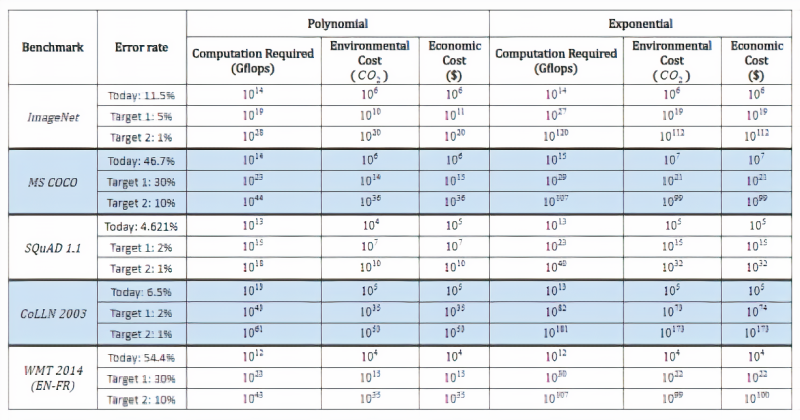
他们的观点是,一份同步报告估计,华盛顿大学(University of Washington)的格罗弗(Grover)假新闻检测模型的培训成本为2.5万美元,耗时约两周。据报道,OpenAI花费了1200万美元来训练它的GPT-3语言模型,谷歌花费了大约6912美元来训练BERT,一个双向转换模型重新定义了11个自然语言处理任务的最新状态。
在去年6月的另一份报告中,马萨诸塞大学阿姆赫斯特分校(University of Massachusetts at Amherst)的研究人员得出结论称,训练和搜索某一模型所需的能量大约排放了62.6万磅二氧化碳。这相当于美国汽车平均寿命的五倍。
研究人员写道:「我们不认为这些目标所隐含的计算要求……硬件、环境和货币成本会令人望而却步。以经济的方式实现这一目标,将需要更高效的硬件、更高效的算法或其他改进,从而产生如此巨大的净影响。」
研究人员指出,在算法级别进行深度学习改进已有历史先例。他们指出了诸如Google的张量处理单元,现场可编程门阵列(FPGA)和专用集成电路(ASIC)之类的硬件加速器的出现,以及通过网络压缩和加速技术来降低计算复杂性的尝试。
他们还引用了神经体系结构搜索和元学习,以此使用优化来查找在一类问题上保持良好性能的体系结构,以此作为计算上有效的改进方法的途径。

算力确实在提高。一项OpenAI研究表明,自2012年以来,每16个月将AI模型训练到ImageNet图像分类中相同性能所需的计算量就减少了2倍。Google的Transformer架构超越了以前的状态seq2seq也是由Google开发的模型,在seq2seq推出三年后,计算量减少了61倍。
DeepMind的AlphaZero这个系统从零开始教自己如何掌握国际象棋,将棋和围棋的游戏,而在一年后,与该系统的前身AlphaGoZero的改进版本相匹配,其计算量就减少了八倍。
用于深度学习模型的计算能力的爆炸式增长已经结束了「人工智能冬天」,并为各种任务的计算机性能树立了新的基准。
但是,深度学习对计算能力的巨大需求限制了它可以以目前的形式提高性能的程度,特别是在硬件性能的提高放缓的时代。这些计算限制的可能影响迫使……机器学习转向比深度学习更高效的技术。
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




