神经网络有什么理论支持?

本文原作者袁洋,本文原载于作者的知乎专栏——理论与机器学习。AI 研习社已获得转载授权。
三秒钟理解本文主旨:
问:神经网络有什么理论支持?
答:目前为止(2017 年)没有什么特别靠谱的。
下面是正文。
[本文主要介绍与神经网络相关的理论工作。 个人水平有限,各位大大轻拍。]
2012 年之后,随着深度学习的浪潮卷来,大家逐渐认可了神经网络 / 深度学习这个东西,都知道它在很多应用场景下面表现得很好。但是,它常常被人诟病的一点就是,就算它表现很好,却没有一个很好的理论解释。
相比之下,很多算法虽然实际表现一般,但是在理论解释这一方面就远胜神经网络了。典型的例子么,自然就是我们耳熟能详的线性回归算法啦。所谓的线性回归,简单地说,就是尝试用一条直线来拟合世间万物。虽然听起来不太靠谱,实际上效果也一般,但是这并不妨碍研究人员在过去的几十年间,怀着满腔热情,发了大量的理论论文研究这个基本问题(不好意思,我也发了两篇)。这就像一个 PhD 笑话里面说的那样,Theory is when one knows everything but nothing works. Practice is when everything works but nobody knows why.
真说起来嘛,倒也不是大家觉得线性回归多么有用,我觉得主要还是直线比较好分析,而神经网络比较难,所以理论工作就少一些。这个现象叫做 Streetlight effect,如下图。

不过,随着深度学习不断发展,越来越多的理论工作者也开始尝试研究神经网络了。今天我就介绍一下我对(2017 年为止)各种相关理论工作的粗浅理解(各位大大轻拍)。假如因此能够帮助同学们对目前现状有更好的理解,甚至得到更好的理论结果,那自然是再好不过了。不过,大家不要对本文抱有太大的期望,因为目前已有的理论工作还远远谈不上对神经网络有什么深刻认识,更不用说能够指导实践;它们不过是分析了各种相对简单的情况罢了。
首先我们看一下神经网络的定义。想必大家听说过现在非常流行的 DenseNet, ResNet 之类的卷积网络,不仅结构特别,还加了 BatchNorm 层调整信号大小,有时候还有 Dropout 减弱过拟合。这些东西好固然是好,但是对于理论工作者来说,就有点太复杂了。所以我们今天谈的网络,大多长这个样子:
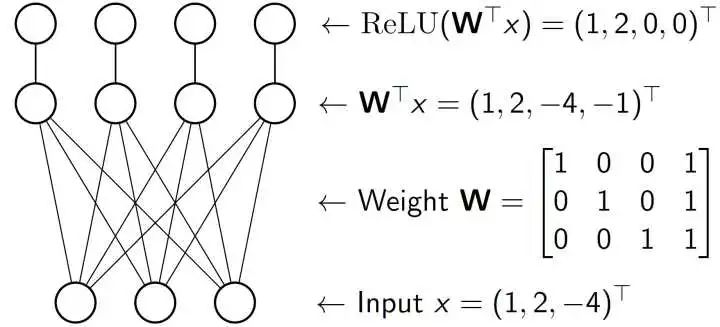
比如我们有一个输入 (1,2,-4),这是一个向量。我们把它输入到一个全连接层。这层有一个参数矩阵是 W= [I ; (1,1,1)]。不过一般来说,参数矩阵是通过 SGD 算法(见之前的博文)学习得到的,所以不会长得这么简单看,千万不要误会了。全连接层的输出呢,就是做矩阵乘法: 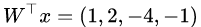
假如只是做矩阵乘法,那么本质只是在做线性变换,哪怕做了很多次其实和做一次的效果是一样的。因此,神经网络在每次线性变换之后都会做一个非线性层。我们今天考虑的是最简单也是应用也最广泛的 ReLU(Rectified Linear Unit),本质就是把输入读进来,然后把输入中的负数变成 0,非负数不变输出。所以 (1,2,-4,-1) 就变成了 (1,2,0,0)。
那么这就是一个合格的简单的一层神经网络了。我们当然可以重复这样的操作搞很多次,比如像下面:
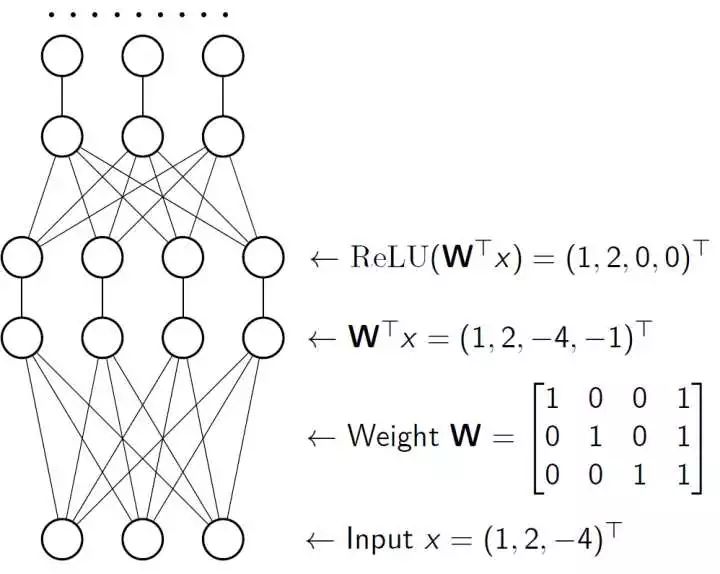
就是把 (1,2,0,0) 当做下一个全连接层的输入输进去,然后再过一个 ReLU 层,再过一个全连接层,再过一个 ReLU 层…… 最后你就得到了一个深度神经网络了。——是的,深度学习,就是这么简单!
当然,我之前提到了,这个模型和现实使用的还有一定的区别。现实中大家使用卷积层而不是全连接层,而且还有别的各种小东西:BatchNorm, Dropout。那些就太复杂啦。目前的理论都是基于我说的这个简化版本的。虽说是简化版本,对于我们人类来说,似乎也已经足够复杂了。
那么,基于这么个模型,今天我就从优化的角度介绍一下已有的理论结果。我们可以从三个方面分析神经网络,分别是表达能力(representation/expressiveness),优化难度(optimization),和归纳推广能力(generalization)
表达能力
表达能力是指,神经网络是否能够用来表达一切函数。举个(不恰当的)例子,中文 / 英文的表达能力很强,我们可以用它们(近似)表达(几乎)一切东西。又或者说,线性回归的表达能力就非常有限,毕竟只有一根直线你能表达个什么东西。。
对于神经网络而言,90 年代初的时候,大家就已经证明了所谓的 universal approximator theorem,就是说对于两层的神经网络+Sigmoid 非线性层(而不是 ReLU),并且网络足够大,那么就可以通过合理设定参数矩阵来近似所有的连续函数或者各种其他函数 [Hornik et al., 1989, Cybenko, 1992,Barron, 1993]。
据说这也就是为什么深度学习过了 20 多年才火起来,因为那些搞神经网络的人声称他们相信了这些理论结果,误以为真的只需要两层就可以表达一切函数了,所以从来没有试过更深的网络,因此被耽搁了很多年。[我个人认为,这纯属借口,无稽之谈,是赤裸裸地朝理论工作者泼脏水!!这就好像我告诉你倒立着走可以在有限时间内走遍世界任意角落,所以你就误以为我们不需要坐飞机了么?]
最近几年,大家也开始研究更深的网络的表达能力 [Eldan and Shamir, 2015, Safran and Shamir, 2016, Lee et al., 2017]。大概是说如果网络更深一些,表达能力会更强一些,需要的网络大小也会更小一些。
总的来说,我个人觉得,表达能力这一块,大家的理解还是比较透彻的。就是说,对于一个足够大的神经网络,总是存在一种参数取值,使得最后得到的神经网络可以近似任何我们想要近似的函数。
优化难度
值得注意的是,总是存在一种参数取值,并不代表我们就能够找到这样的取值。
这就好像我们做数学作业,既然是作业嘛,我们知道肯定是存在答案的,但是好做么?显然并不是。我们往往要花很长时间才能够做出来;做出来还算是好的,有的时候还做不出来,这个时候就需要去抄别人的答案。
数学作业做不出来可能是个小事,如果找不到好的神经网络的取值,那么这个算法就没什么用了。但神奇的是,现实生活中,人们用简单的 SGD 算法,总是能找到一个很好的取值方案。——如果你没有觉得这个事情很神奇,那么你还是应该回过头去想想数学作业的例子。当你绞尽脑汁、茶饭不思、夜不能寐地做数学作业的时候,你发现你的大神同学总是三下五除二就把作业搞定了,而且感觉他也没怎么学习,上课也不认真听讲,你觉得是不是很神奇?
找神经网络的取值方案,或者说 “学习” 数据的这个过程,就叫做优化。从理论的角度来看,一般来说,假如数据或者问题没有特殊的假设,优化这件事情就是非常困难的,一般就是 NP-hard 什么的,也就是所谓的很难很难的事情啦 [Sı́ma, 2002, Livni et al., 2014, Shamir, 2016]。那既然现实生活中这个问题其实并没有那么难,这就说明,现实的问题是满足一些较为特殊的条件,大大降低了优化的难度。
那么,现实中的问题到底是满足了什么样的条件,以及优化的难度是如何被降低了?在什么情况下我们能够很容易找到合适的取值,什么情况下可能会比较难?SGD 为什么能干得这么好?大家对这些问题的理解还比较欠缺。
目前来说,人们会从几个不同的方向简化问题,做一些理论分析:
(个人能力有限,落下了某些重要论文还请各位大大轻拍)
能不能假如一些较强的假设得到一些理论结果?这个想法是早期工作中比较常见的,人们会使用一些较强的假设,例如参数是复数,或者需要学习的函数是多项式,或者目标参数服从独立同分布等等,和实际差距较大。[Andoni et al., 2014, Arora et al., 2014]
能不能用特殊的算法来做优化?直接分析 SGD 在神经网络上的表现相对比较困难,因此人们会尝试分析别的特殊算法的表现。例如 Tensor decomposition, half space intersection, kernel methods 等等 [Janzamin et al., 2015, Zhang et al., 2015, Sedghi and Anandkumar, 2015, Goel et al., 2016]。这些算法虽然往往能够在多项式时间内学习出两层的神经网络,但是在现实生活中表现一般,没有人真的在用。值得一提的是,[Goel and Klivans, 2017] 的 kernel methods 在某些假设下可以在多项式时间内学习很多层的神经网络,是这个方向的佼佼者。
能不能暂时忽略非线性层(即 ReLU 层),只考虑线性变换?这个方向叫做 deep linear network,即深度线性网络。人们可以证明这样的网络有很好的性质,但是这样的网络表达能力有所欠缺,只能够表达线性函数,而且优化起来可能不如线性函数收敛速度快。[Saxe et al., 2013, Kawaguchi, 2016, Hardt and Ma, 2016]
就算考虑非线性层,能不能加入一些假设,将其弱化?这个方向叫做 independent activation assumption,就是假设网络的输入和网络的输出的独立的,以及 / 或者 ReLU 的输出的每个维度都是独立的。这些假设在现实中并不成立,主要还是为了理论分析方便。[Choromanska et al., 2015, Kawaguchi, 2016, Brutzkus and Globerson, 2017]
能不能不加别的假设,只考虑较浅的(两层)网络?嗯,不知不觉终于要介绍我们的论文了。这个方向的问题就是网络层数比较少,和现实不符,而且往往只存在一个 global minimum。[Zhong et al., 2017] 使用的算法是 Tensor decomposition 找到一个离 Global minimum 很近的点,然后用 Gradient descent 来逼近 Global minimum。[Tian 2017] 证明了普通的两层神经网络的优化对 SGD 而言可能是比较困难的。我们的论文则是考虑了带了 Residual link 的两层神经网络,证明了只要用 SGD 最后能够收敛到 Global minimum [Li and Yuan, 2017] (之后有机会会详细介绍)。
我知道的优化工作大概就是这样了。大家可以看到,目前来看,为了得到理论结果,需要做各种各样的假设。想要单纯证明 SGD 在深度神经网络(大于2层)上的收敛性,似乎还有很远的路要走。
归纳推广能力
除了现实生活中优化难度比较小,神经网络还有一个非常受机器学习工作者推崇的优点就是它有很强的归纳推广能力。用机器学习的语言来说,假如我们优化神经网络使用的数据集是训练集,得到的网络在训练集上面表现非常好(因为优化简单),然后测试的时候使用神经网络从来没有见过的测试集进行测试,结果网络表现仍然非常好!这个就叫做归纳推广能力强。
假如你觉得这个比较难理解,可以考虑数学考试的例子。我想,你一定见过有些同学,平时做数学作业兢兢业业一丝不苟,与老师沟通,与同学讨论,翻书查资料,经常能够拿满分。这种同学,我们就说他训练得不错,死用功,作业题都会做。那么,这样的同学数学考试一定能够考高分么?根据我个人的经验,答案是不一定。因为考试题目在平时作业里面不一定都出现过,这样的死用功的同学遇到没见过的题目就懵了,可能就挂了。
可神经网络呢?他不仅平时轻轻松松写作业,到了考试仍然非常生猛,哪怕题目没见过,只要和平时作业一个类型,他都顺手拈来,是不是很神奇?学霸有没有?
关于为什么神经网络有比较强的归纳推广能力,目前大家还不是非常清楚。目前的理论分析比较少,而且结果也不能完全解释这个现象 [Hardt et al. 2016, Mou et al. 2017]。我觉得这是很重要的方向,也是目前的研究热点。
不过在实践过程中,很多人有这么个猜想,就是所谓的 Flat minima 假说。据说,在使用 SGD 算法优化神经网络的时候,SGD 最后总是会停留在参数空间中的一个比较平整的区域(目前没有证明),而且如果最后选的参数是在这么个区域,那么它的归纳推广能力就比较强(目前没有证明)[Shirish Keskar et al., 2016, Hochreiter and Schmidhuber, 1995, Chaudhari et al., 2016, Zhang et al., 2016]。
参考文献:
Hornik, K., Stinchcombe, M. B., and White, H. (1989). Multilayer feedforward networks are universal approximators.
Cybenko, G. (1992). Approximation by superpositions of a sigmoidal function. MCSS, 5(4):455.
Barron, A. R. (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Trans. Information Theory, 39(3):930–945.
Eldan, R. and Shamir, O. (2015). The Power of Depth for Feedforward Neural Networks.
Safran, I. and Shamir, O. (2016). Depth-Width Tradeoffs in Approximating Natural Functions with Neural Networks
Lee, H., Ge, R., Risteski, A., Ma, T., and Arora, S. (2017). On the ability of neural nets to express distributions.
Sı́ma, J. (2002). Training a single sigmoidal neuron is hard. Neural Computation, 14(11):2709–2728.
Livni, R., Shalev-Shwartz, S., and Shamir, O. (2014). On the computational efficiency of training neural networks.
Shamir, O. (2016). Distribution-specific hardness of learning neural networks.
Janzamin, M., Sedghi, H., and Anandkumar, A. (2015). Beating the perils of non-convexity: Guaranteed training of neural networks using tensor methods.
Zhang, Y., Lee, J. D., Wainwright, M. J., and Jordan, M. I. (2015). Learning halfspaces and neural networks with random initialization.
Sedghi, H. and Anandkumar, A. (2015). Provable methods for training neural networks with sparse connectivity.
Goel, S., Kanade, V., Klivans, A. R., and Thaler, J. (2016). Reliably learning the relu in polynomial time.
Goel, S. and Klivans, A. (2017). Eigenvalue decay implies polynomial-time learnability for neural networks. In NIPS 2017.
Andoni, A., Panigrahy, R., Valiant, G., and Zhang, L. (2014). Learning polynomials with neural networks. In ICML, pages 1908–1916.
Arora, S., Bhaskara, A., Ge, R., and Ma, T. (2014). Provable bounds for learning some deep representations. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014, pages 584–592.
Saxe, A. M., McClelland, J. L., and Ganguli, S. (2013). Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.
Kawaguchi, K. (2016). Deep learning without poor local minima. In NIPS, pages 586–594.
Hardt, M. and Ma, T. (2016). Identity matters in deep learning.
Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B., and LeCun, Y. (2015). The loss surfaces of multilayer networks. In AISTATS.
Brutzkus, A. and Globerson, A. (2017). Globally optimal gradient descent for a convnet with gaussian inputs. In ICML 2017.
Li, Y. and Yuan, Y. (2017). Convergence analysis of two-layer neural networks with relu activation. In NIPS 2017.
Zhong, K., Song, Z., Jain, P., Bartlett, P. L., and Dhillon, I. S. (2017). Recovery guarantees for one-hidden-layer neural networks. In ICML 2017.
Hardt, M and Recht, B and Singer, Y. (2015). Train faster, generalize better: Stability of stochastic gradient descent. In ICML 2016.
Wenlong Mou, Liwei Wang, Xiyu Zhai, Kai Zheng (2017). Generalization Bounds of SGLD for Non-convex Learning: Two Theoretical Viewpoints.
Shirish Keskar, N., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P. T. P. (2016). On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima.
Hochreiter, S. and Schmidhuber, J. (1995). Simplifying neural nets by discovering flat minima. In Advances in Neural Information Processing Systems 7, pages 529–536. MIT Press.
Chaudhari, P., Choromanska, A., Soatto, S., LeCun, Y., Baldassi, C., Borgs, C., Chayes, J., Sagun, L., and Zecchina, R. (2016). Entropy-SGD: Biasing Gradient Descent Into Wide Valleys. ArXiv e-prints.
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. (2016).Understanding deep learning requires rethinking generalization. ArXiv e-prints.
Yuandong Tian. (2017). An Analytical Formula of Population Gradient for two-layered ReLU network and its Applications in Convergence and Critical Point Analysis. ICML 2017.


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
深度解析 LSTM 神经网络的设计原理
▼▼▼



