学界 | 473个模型试验告诉你文本分类中的最好编码方式
选自arXiv
机器之心编译
参与:蒋思源
在不同层面上使用不同编码方式和语言模型在文本分类任务中到底效果怎样?Yann LeCun 和 Xiang Zhang 在四种语言、14 个数据集上测试了 473 个模型,并希望能找到最好的编码方法。机器之心简单介绍了该论文,详细内容请查看原论文。

论文地址:https://arxiv.org/pdf/1708.02657.pdf
本论文实证研究了在文本分类模型中汉语、日语、韩语(CJK)和英语的不同编码方式。该研究讨论了不同层面的编码,包括 UTF-8 bytes、字符级和词汇级。对于所有的编码层面,我们都提供了线性模型、fastText (Joulin et al., 2016) 和卷积网络之间的对比。对于卷积网络,我们使用字符字形(character glyph)图像、one-hot(或 one-of-n)编码和嵌入方法比较了不同的编码机制。总的来说,该实验涉及 473 个模型,并使用了四种语言(汉语、英语、日语和韩语)的 14 个大规模文本分类数据集。该研究所得出来的一些结论:基于 UTF-8 字节层面的 one-hot 编码在卷积网络中始终生成优秀结果;词层面的 N 元线性模型即使不能完美地分词,它也有强大的性能;fastText 使用字符层面的 N 元模型进行编码取得了最好的性能,但当特征太多时容易过拟合。
2. 卷积网络的编码机制
为了进行客观地对比,所有的卷积网络除了最先几层外都共享相同的设计。我们称相同的部分为分类器,前面不同的几层称为编码器。
2.1 字符字形(Character Glyph)
字形(Glyph)指的是以书写为目的的可读字符。CJK 就是由各种拓扑字形组成的语言,它的笔画和部首代表不同的语义,因此字符字形是一种可行的编码解决方案。
2.2 One-hot 编码
在最简单的 One-hot 编码中,每一个实体必须使用维数等于所有可能实体数的向量表达,并且除了该实体在词汇表中的索引为 1 以外,其它元素都为 0。
2.3 嵌入
我们使用术语「嵌入」表达关联每一个实体的固定长度向量。这些向量一般经过随机初始化,并且通过无监督学习或在当前任务联合学习。嵌入模型的优势在于不必要构建 One-hot 向量,因此嵌入模型的内存占用要显著地比 OnehotNet 少。最后,嵌入方法基本上可以应用于任意编码层面。
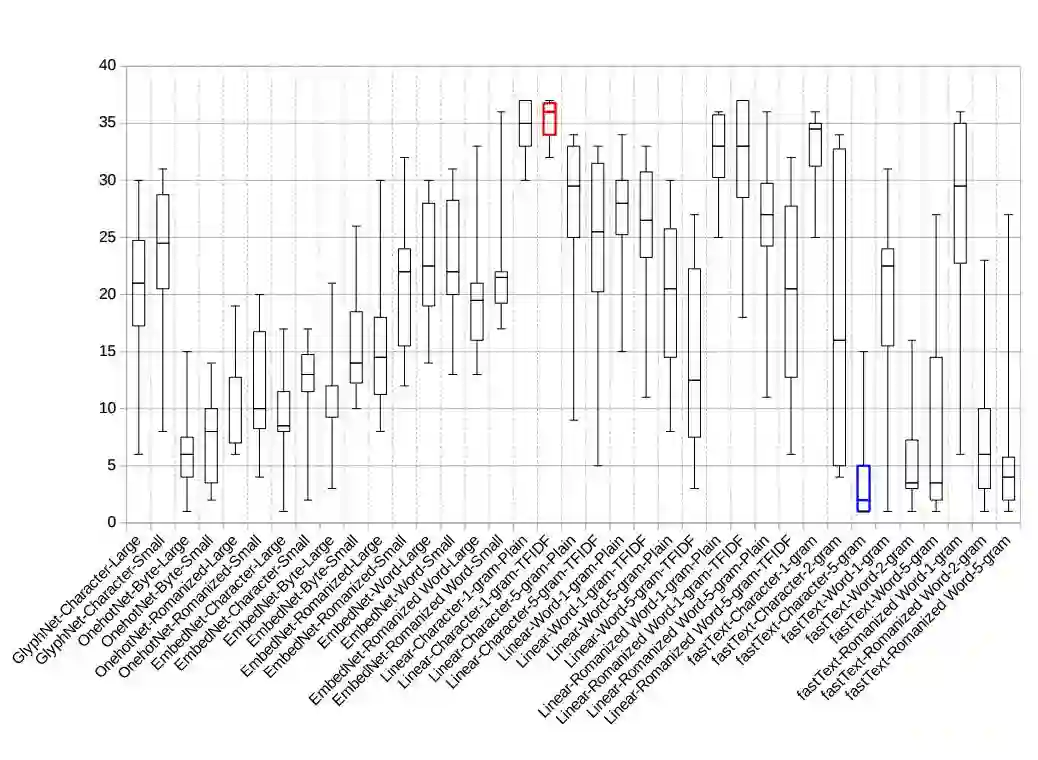
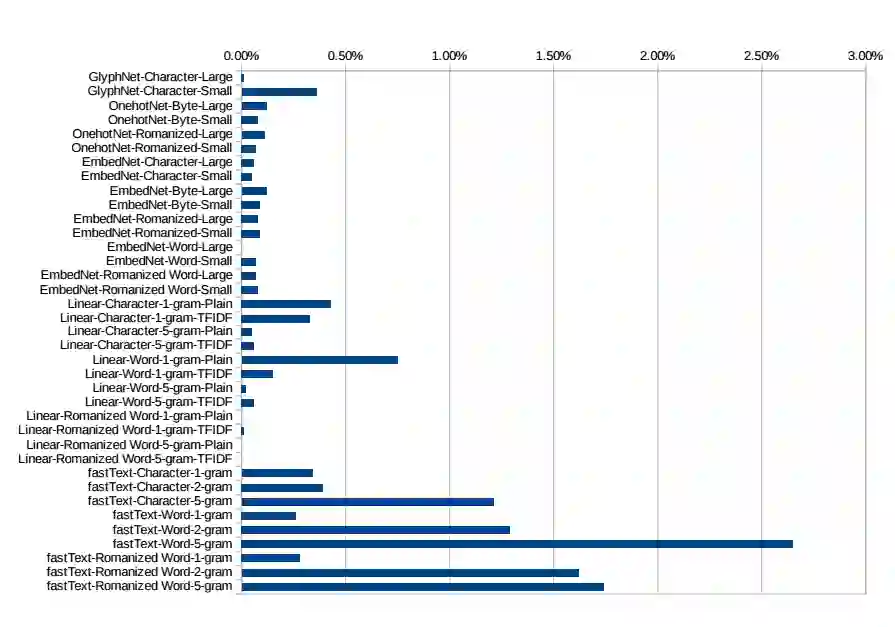
图 3:Joint binary 数据集的泛化差距(Generalization gap)
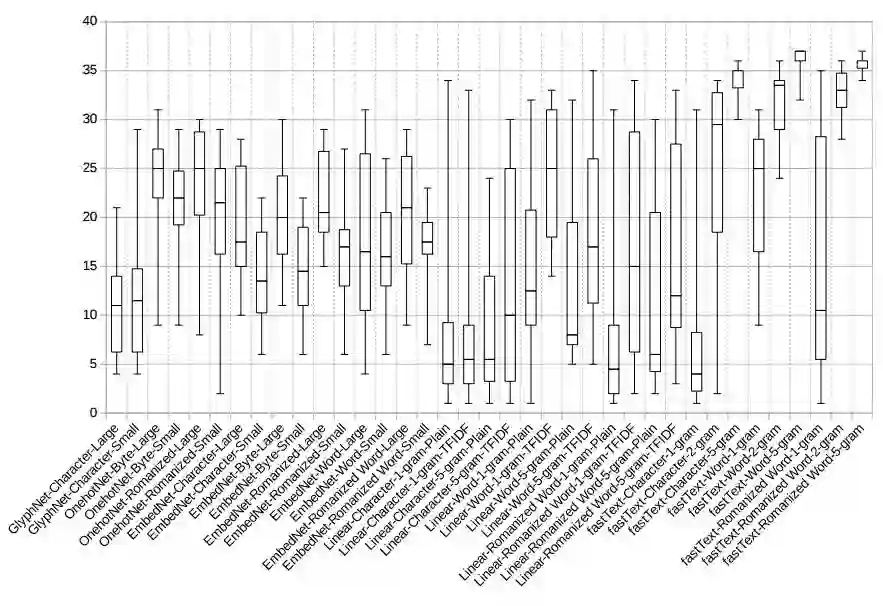
图 4:不同模型泛化差距的箱线图
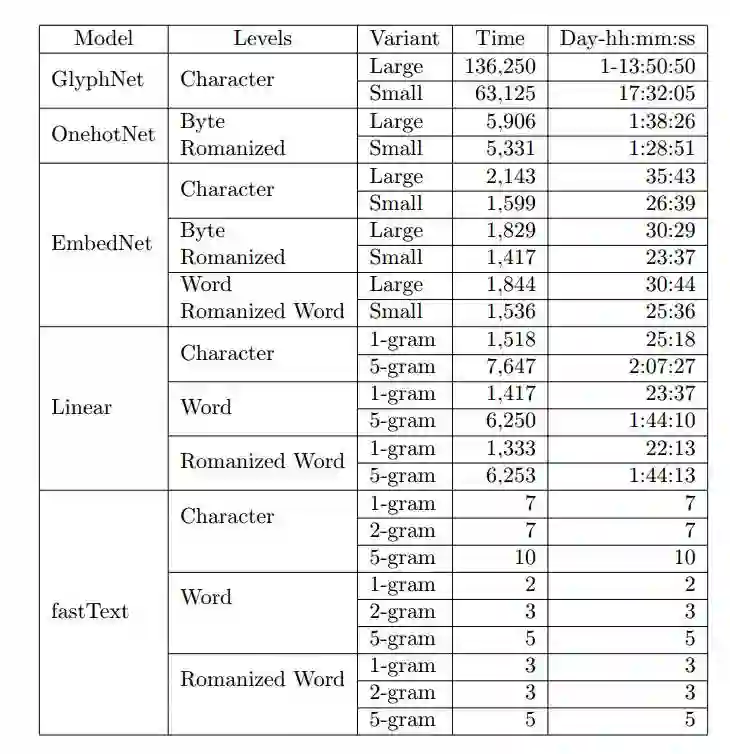
表 12:在 Joint binary 数据集上遍历一百万样本的估计训练时间,第四列时间估计以秒为单位。这些估计只供参考,训练时间还相当依赖于真实的计算环境。
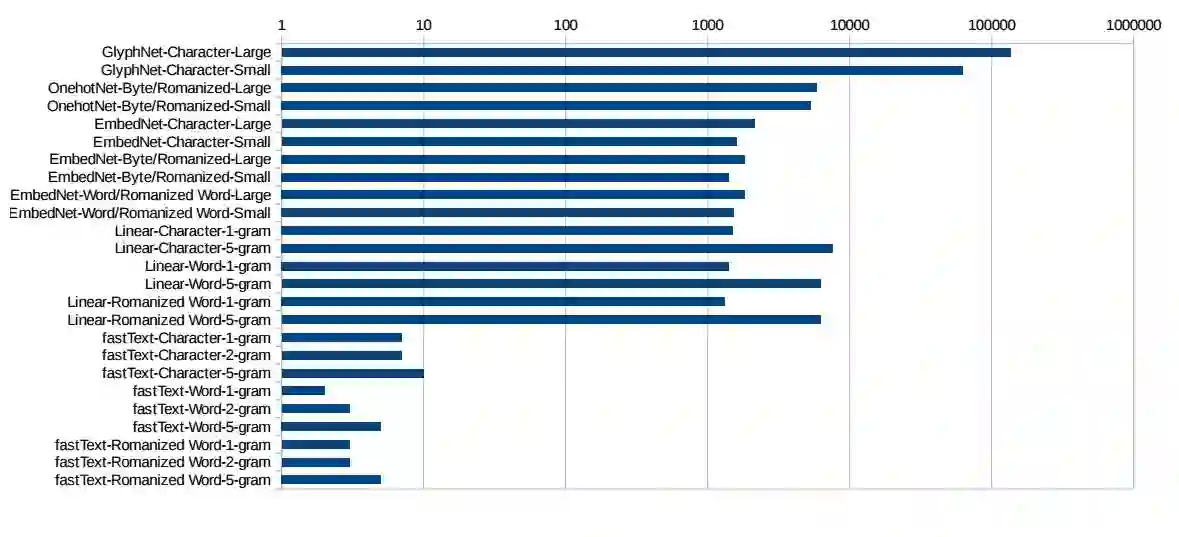
图 5:不同模型遍历 1 百万样本所需要的时间,时间轴为对数尺度。
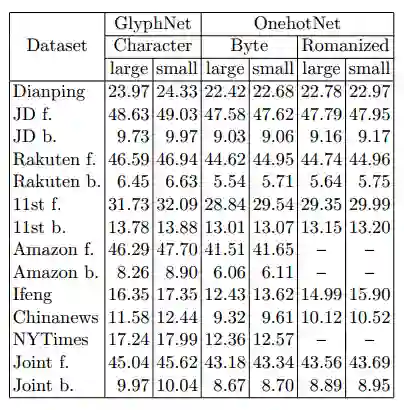
表 13:GlyphNet 和 OnehotNet 的训练误差
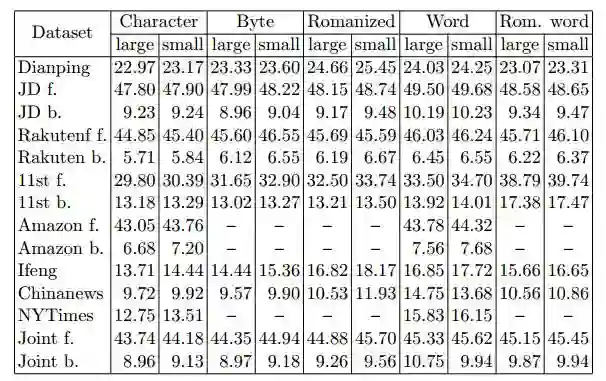
表 14:EmbedNet 的训练误差

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



