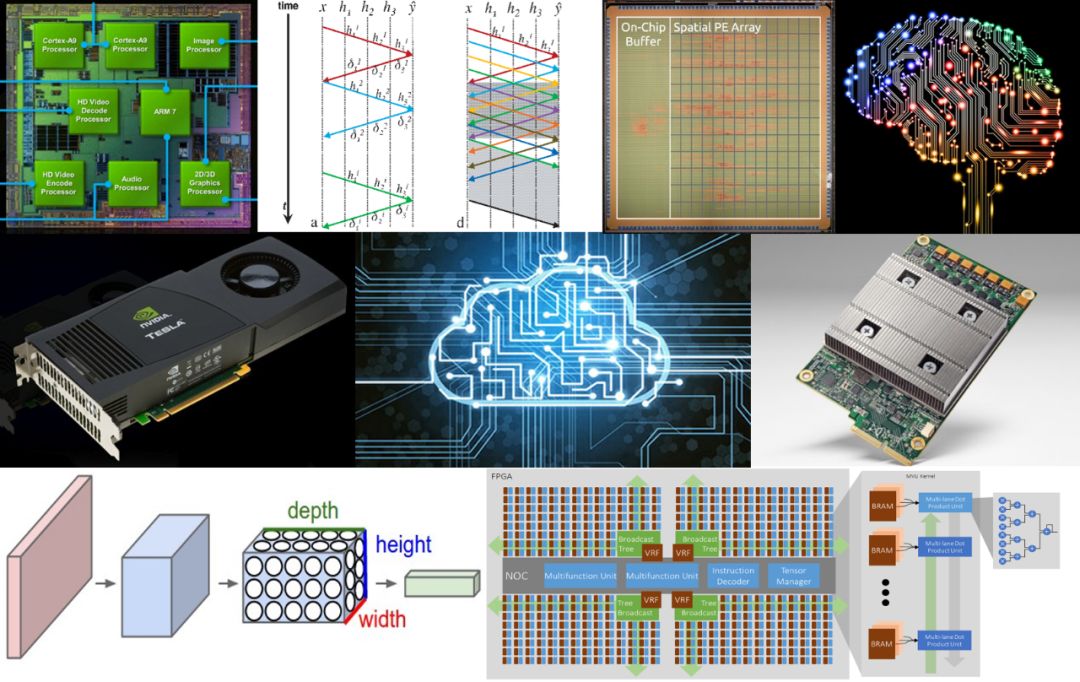
斯坦福2018秋季课程大放送!深入浅出带你玩转机器学习加速(附超全资料+PPT)

新智元推荐
来源:cs217.github.io
编辑:肖琴
【新智元导读】学芯片技术的机会来了!斯坦福大学2018秋季学期推出《机器学习硬件加速器》课程,深入介绍机器学习系统中设计训练和推理加速器的架构技术。课程涵盖经典的ML算法,用于ML模型推理和训练的加速器设计等,超多专业材料和PPT,是本领域不可多得的专业课程。

本课程将深入介绍用于在机器学习系统中设计训练和推理加速器的架构技术。本课程将涵盖经典的ML算法,如线性回归和支持向量机,以及DNN模型,如卷积神经网络和递归神经网络。我们将考虑这些模型的训练和推理,并讨论诸如batch size、精度、稀疏度和压缩等参数对这些模型精度的影响。我们将介绍用于ML模型推理和训练的加速器设计。学生将熟悉使用并行性、局部性和低精度来实现ML中使用的核心计算内核的硬件实现技术。为了设计高效节能的加速器,学生们将建立直觉,在ML模型参数和硬件实现技术之间进行权衡。学生将阅读最近的研究论文并完成一个设计项目。
主讲教师:

Kunle Olukotun
Kunle Olukotun是斯坦福大学电气工程和计算机科学的Cadence设计系统教授,自1991年以来一直在该系任教。Olukotun以领导Stanford Hydra研究项目而著名,该项目开发了首批支持thread-level speculation的芯片多处理器。
Ardavan Pedram
Ardavan Pedram是斯坦福大学电气工程系研究助理,与Kunle Olukotun教师合作的Pervasive Prallelism Laboratory (PPL) 项目的成员。
特邀讲师:

Boris Ginsburg, NVIDIA
Robert Schreiber, Cerebras Systems
Mikhail Smelyanskiy, Facebook
Cliff Young, Google
第1课:简介,摩尔定律和Dennard Scaling定律后硬件加速器的作用
阅读:暗硅(Dark Silicon)有用吗? Hennessy Patterson第7.1-7.2章
https://ieeexplore.ieee.org/document/6241647/
第2课:经典ML算法:回归、SVM
阅读:TABLA:基于统一模板的加速统计机器学习的架构
https://www.cc.gatech.edu/~hadi/doc/paper/2015-tr-tabla.pdf
第3课:线性代数基础和加速线性代数BLAS运算
20世纪的技术:收缩阵列和MIMD,CGRAs
阅读:为什么选择收缩架构?
www.eecs.harvard.edu/~htk/publication/1982-kung-why-systolic-architecture.pdf
高性能GEMM的剖析
https://www.cs.utexas.edu/users/pingali/CS378/2008sp/papers/gotoPaper.pdf
第4课:评估性能、能效、并行性,局部性、内存层次,Roofline模型
阅读:Dark Memory and Accelerator-Rich System Optimization in the Dark Silicon Era
https://arxiv.org/abs/1602.04183
第5课:真实世界的架构:将其付诸实践
加速GEMM:定制,GPU,TPU1架构及其GEMM性能
阅读:Google TPU
https://arxiv.org/pdf/1704.04760.pdf
Codesign Tradeoffs
https://ieeexplore.ieee.org/document/6212466/
NVIDIA Tesla V100
images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
第6课:神经网络:MLP和CNN推理
阅读:IEEE proceeding
Brooks’s book (Selected Chapters)
第7课:加速CNN的推理:实践中的阻塞(Blocking)和并行(Parallelism)
DianNao, Eyeriss, TPU1
阅读:一种阻塞卷积神经网络的系统方法
https://arxiv.org/abs/1606.04209
Eyeriss:用于卷积神经网络的节能数据流的空间架构
https://people.csail.mit.edu/emer/papers/2016.06.isca.eyeriss_architecture.pdf
Google TPU (see lecture 5)
第8课:使用Spatial建模神经网络,分析性能和能量
阅读:Spatial:一种应用程序加速器的语言和编译器
http://arsenalfc.stanford.edu/papers/spatial18.pdf
第9课:训练:SGD,反向传播,统计效率,batch size
阅读:去年的NIPS workshop:Graphcore
https://supercomputersfordl2017.github.io/Presentations/SimonKnowlesGraphCore.pdf
第10课:DNN的弹性:稀疏性和低精度网络
阅读:EIE:压缩深度神经网络的高效推断机(Efficient Inference Engine)
https://arxiv.org/pdf/1602.01528.pdf
Flexpoint of Nervana
https://arxiv.org/pdf/1711.02213.pdf
Boris Ginsburg: 卷积网络的Large Batch训练
https://arxiv.org/abs/1708.03888
LSTM Block Compression by Baidu?
第11课:低精度训练
阅读:HALP:High-Accuracy Low-Precision Training
https://arxiv.org/abs/1803.03383
Ternary or binary networks
See Boris Ginsburg's work (lecture 10)
第12课:分布式和并行系统训练:Hogwild!,异步和硬件效率
阅读:Deep Gradient compression
https://arxiv.org/abs/1712.01887
Hogwild!:一种并行化随机梯度下降的Lock-Free 方法
https://people.eecs.berkeley.edu/~brecht/papers/hogwildTR.pdf
大规模分布式深度网络
https://static.googleusercontent.com/media/research.google.com/en//archive/large_deep_networks_nips2012.pdf
第13课:FPGA和CGRAs:Catapult,Brainwave, Plasticine
Catapult
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/Cloud-Scale-Acceleration-Architecture.pdf
Brainwave
https://www.microsoft.com/en-us/research/uploads/prod/2018/03/mi0218_Chung-2018Mar25.pdf
Plasticine
dawn.cs.stanford.edu/pubs/plasticine-isca2017.pdf
第14课:ML基准:DAWNbench,MLPerf
DawnBench
https://cs.stanford.edu/~matei/papers/2017/nips_sysml_dawnbench.pdf
MLPerf
https://mlperf.org/
第15课:Project presentations
更多阅读材料:https://cs217.github.io/readings
课程PPT:https://cs217.github.io/lecture_slides
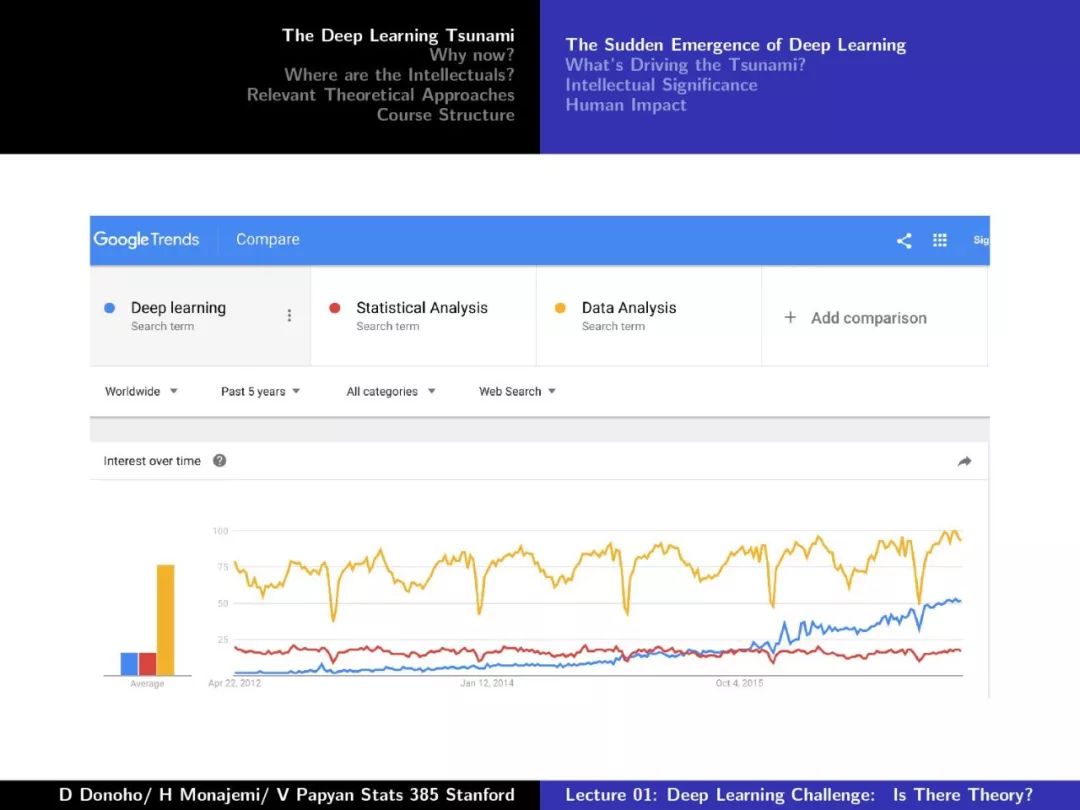
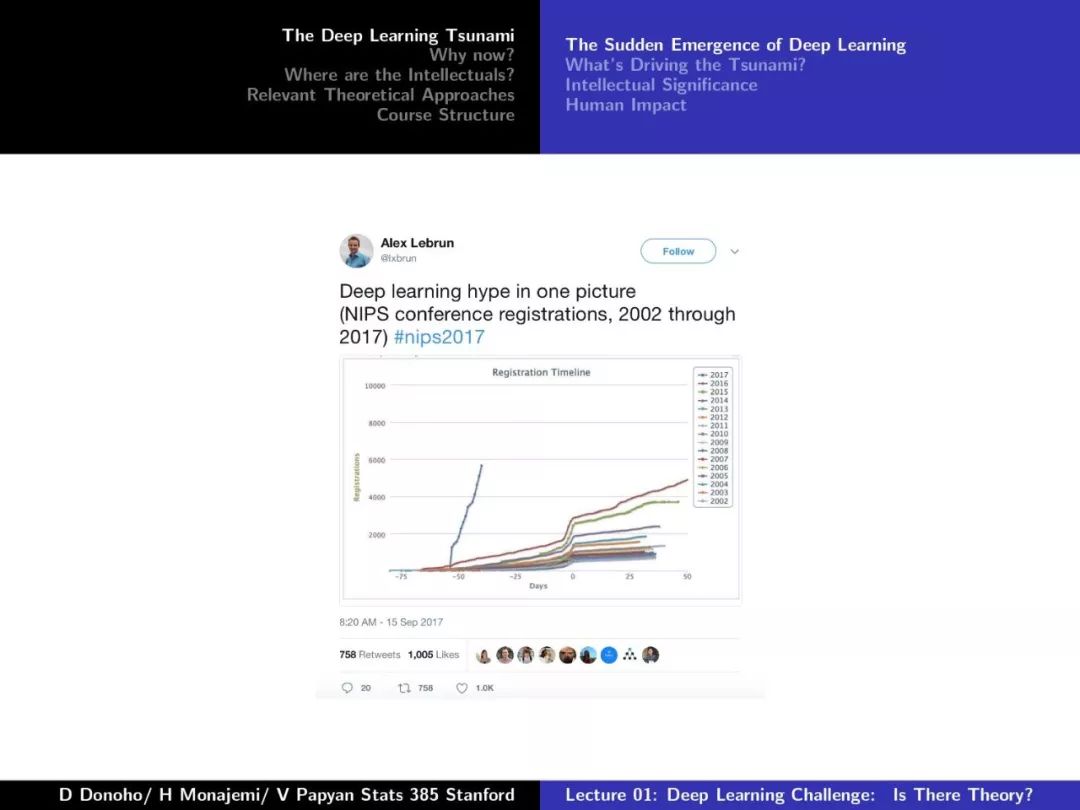
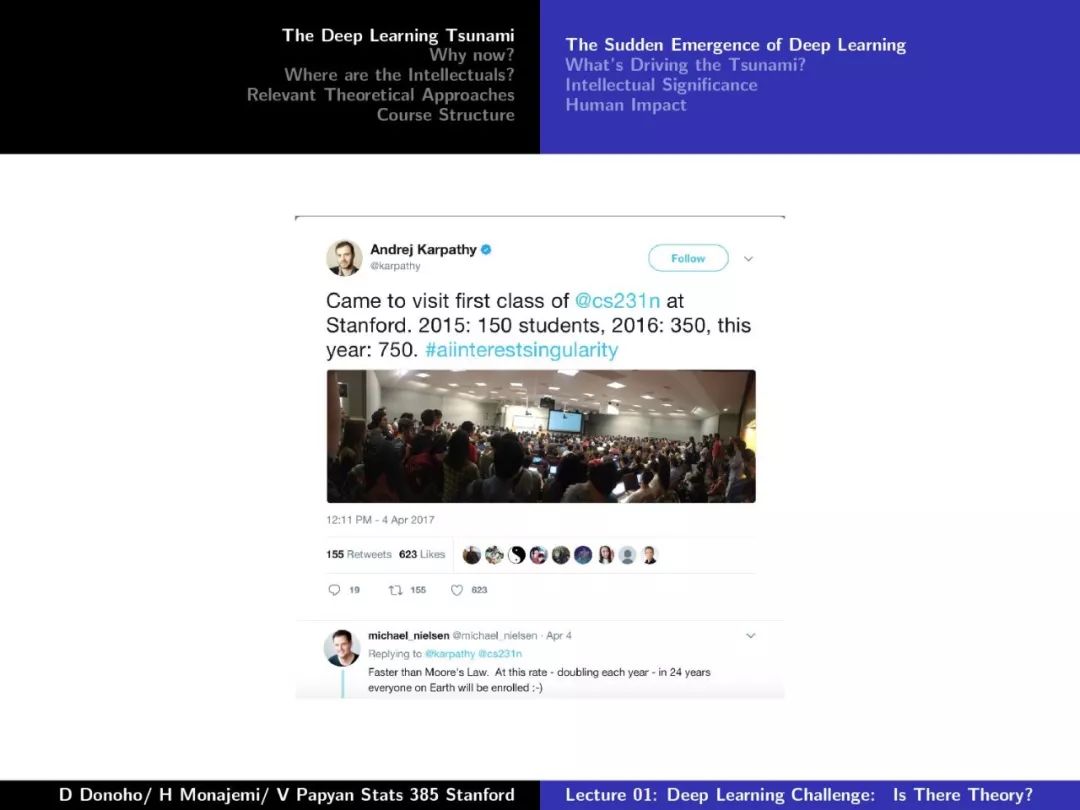
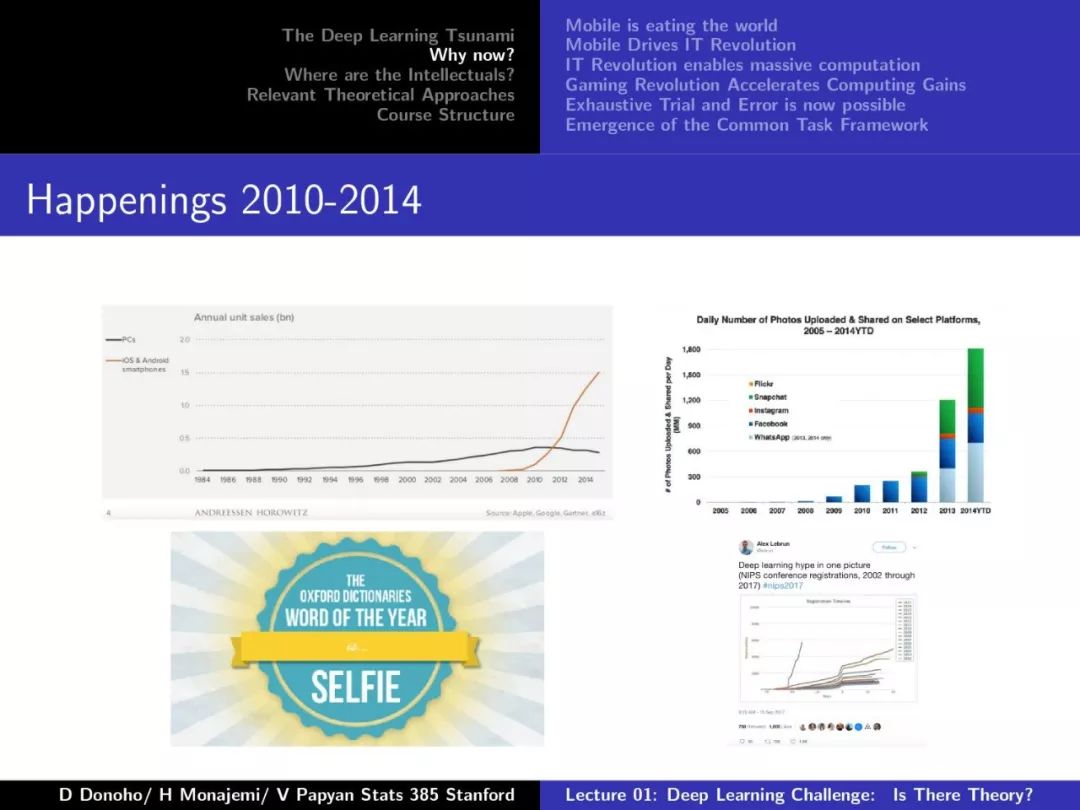
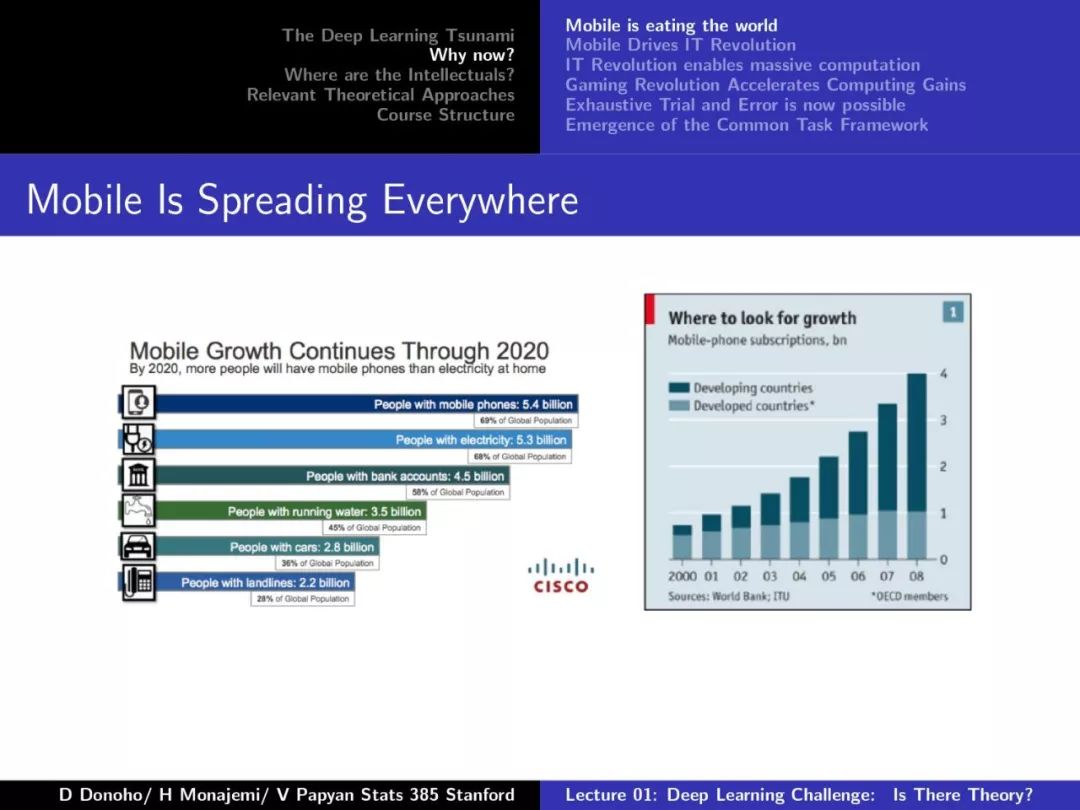
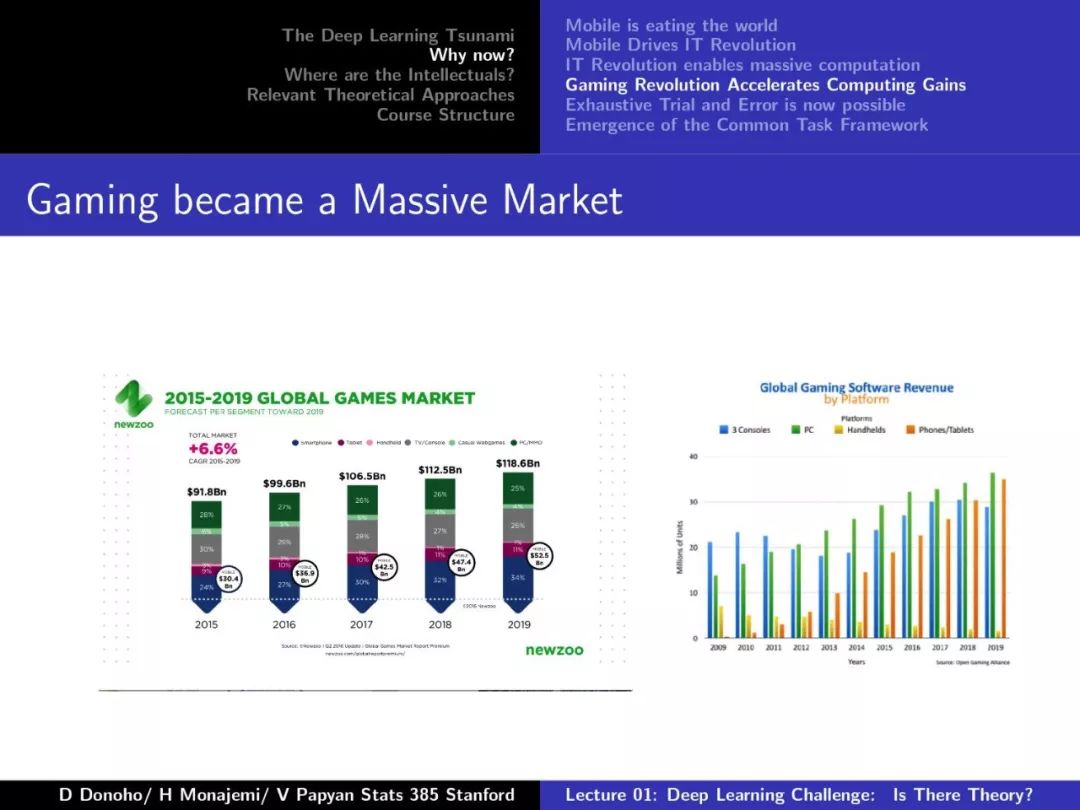
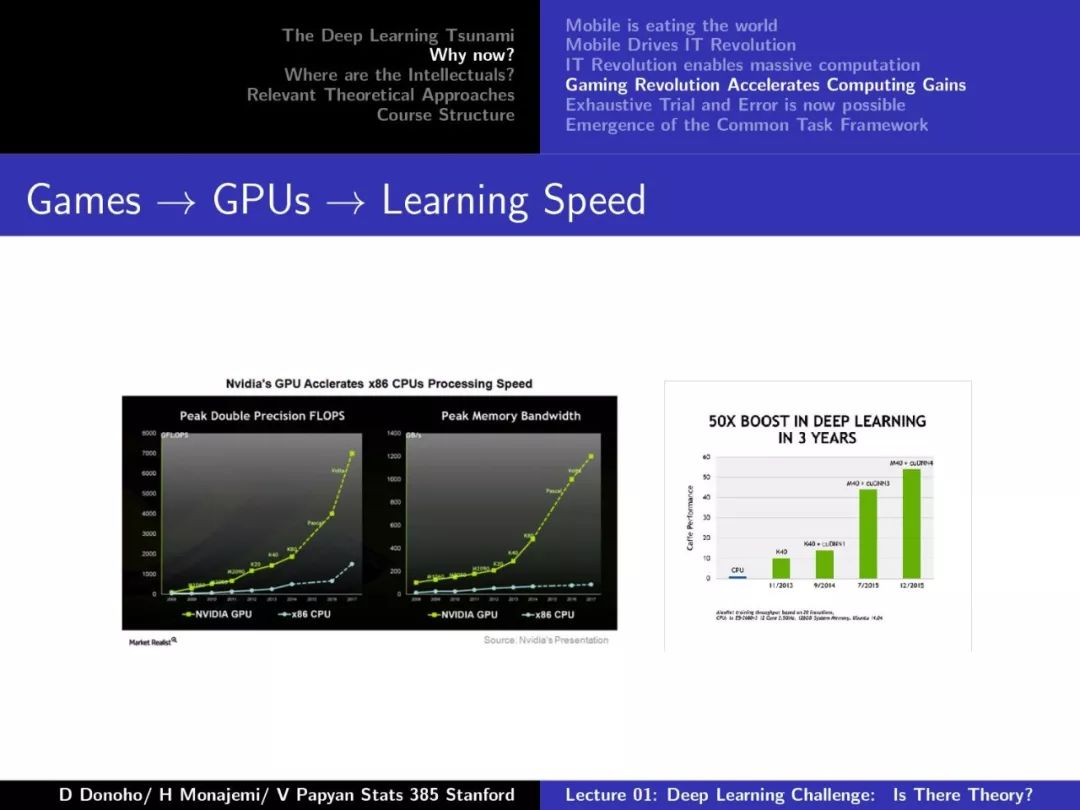
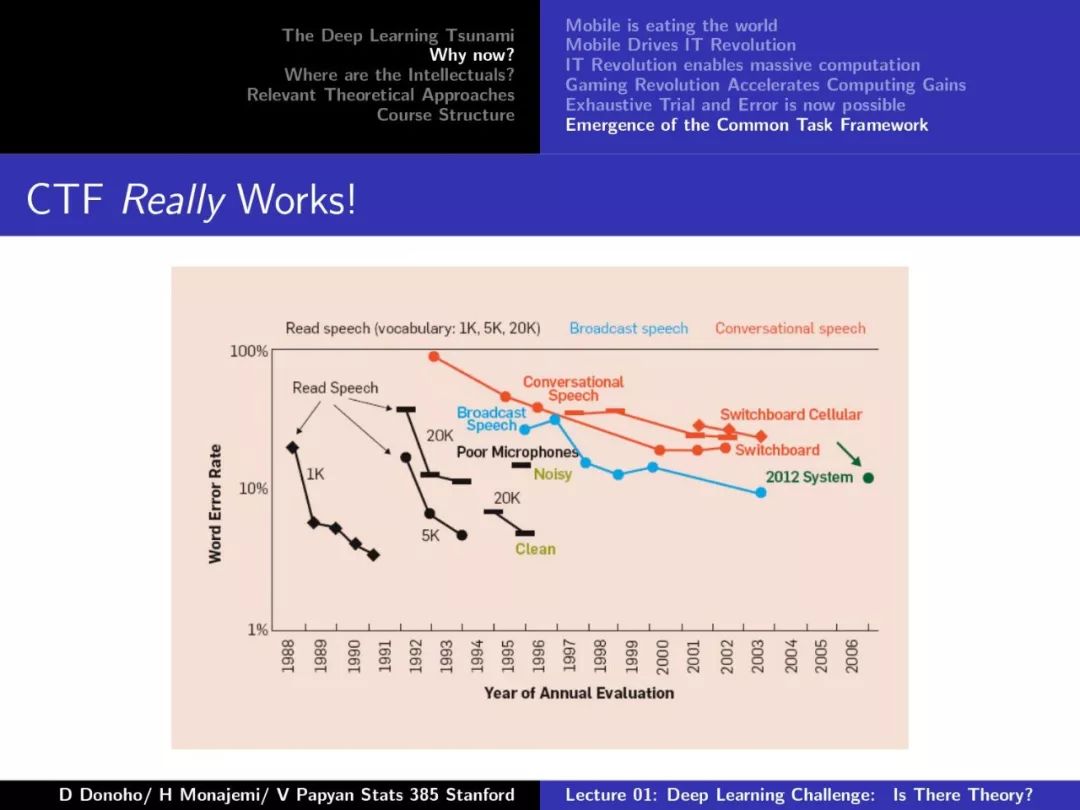
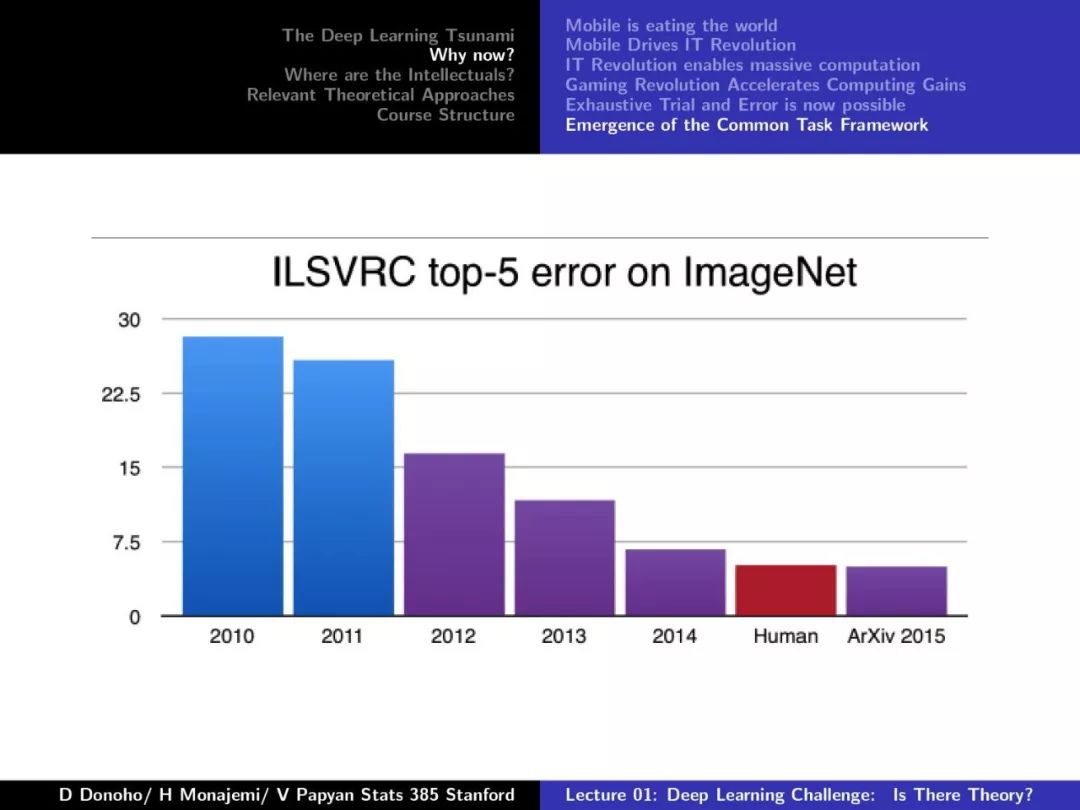
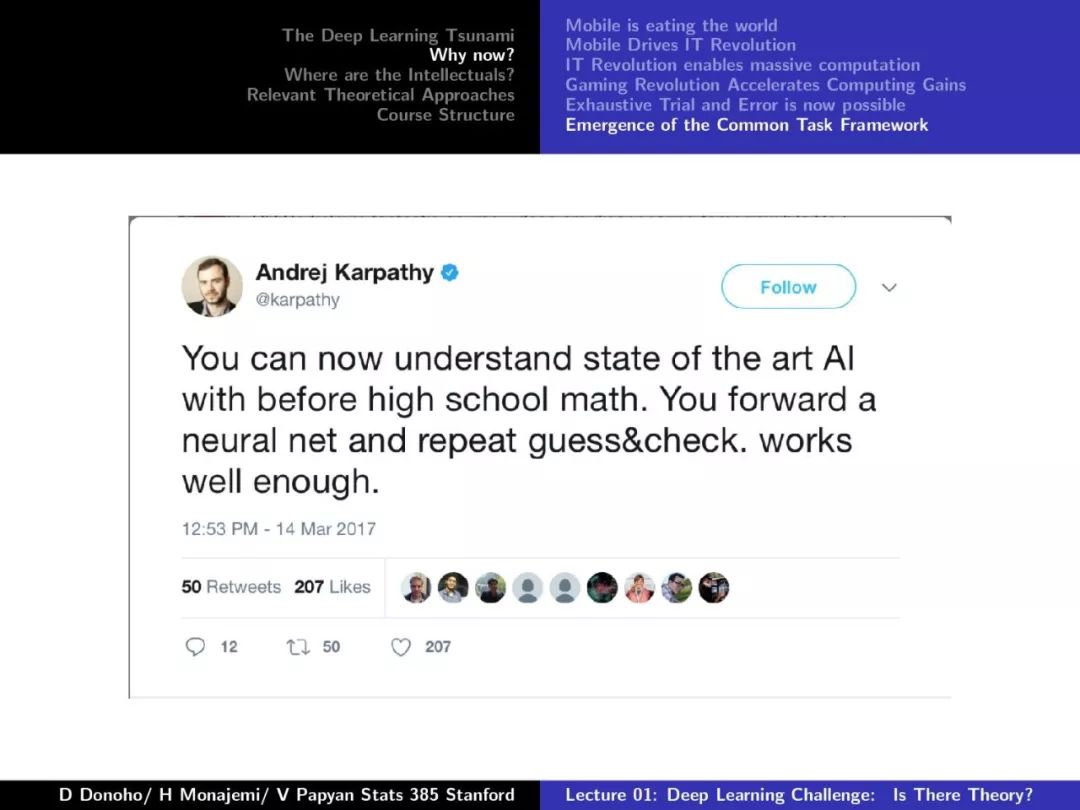
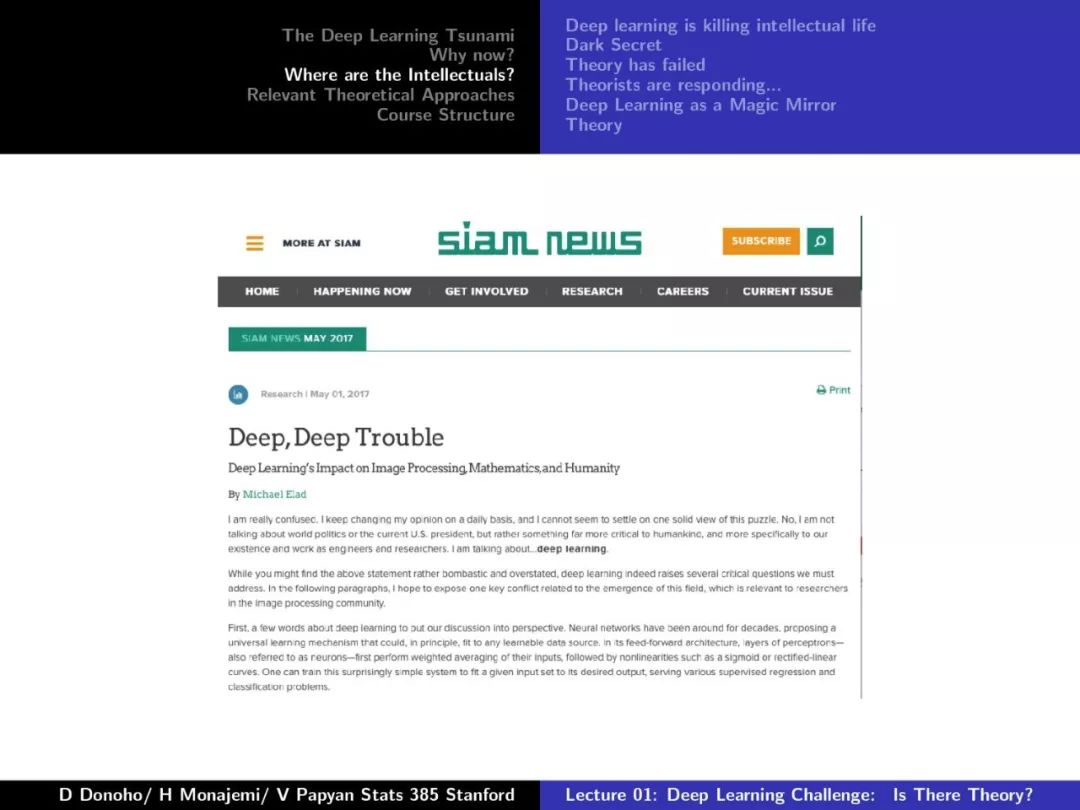
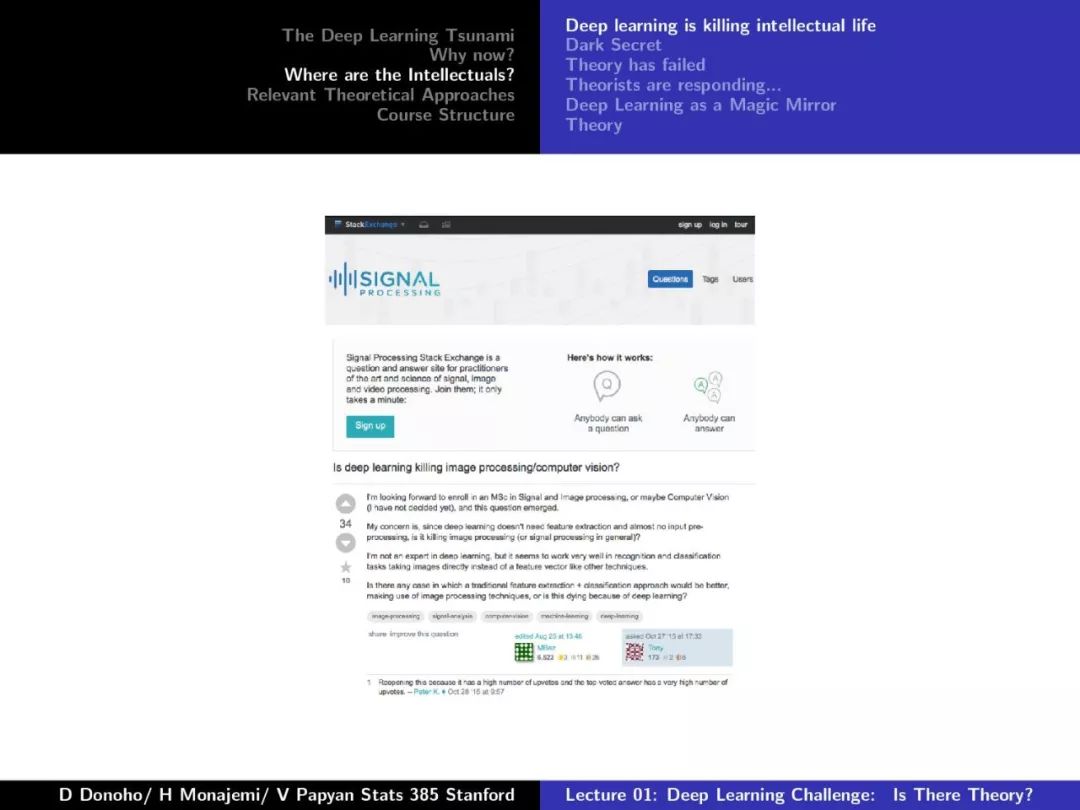
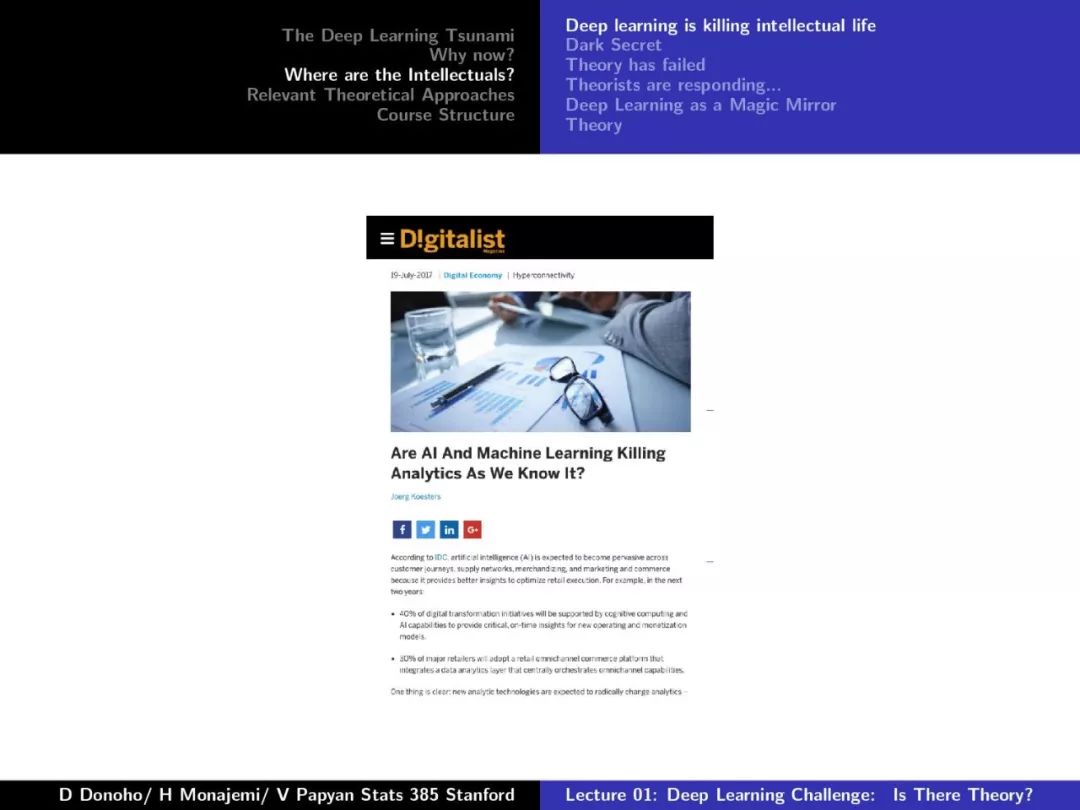
第一课对深度学习的发展、摩尔定律、Dennard Scaling、相关理论方法等做了较为详尽的介绍,非常干货,下面附上第一课的PPT。









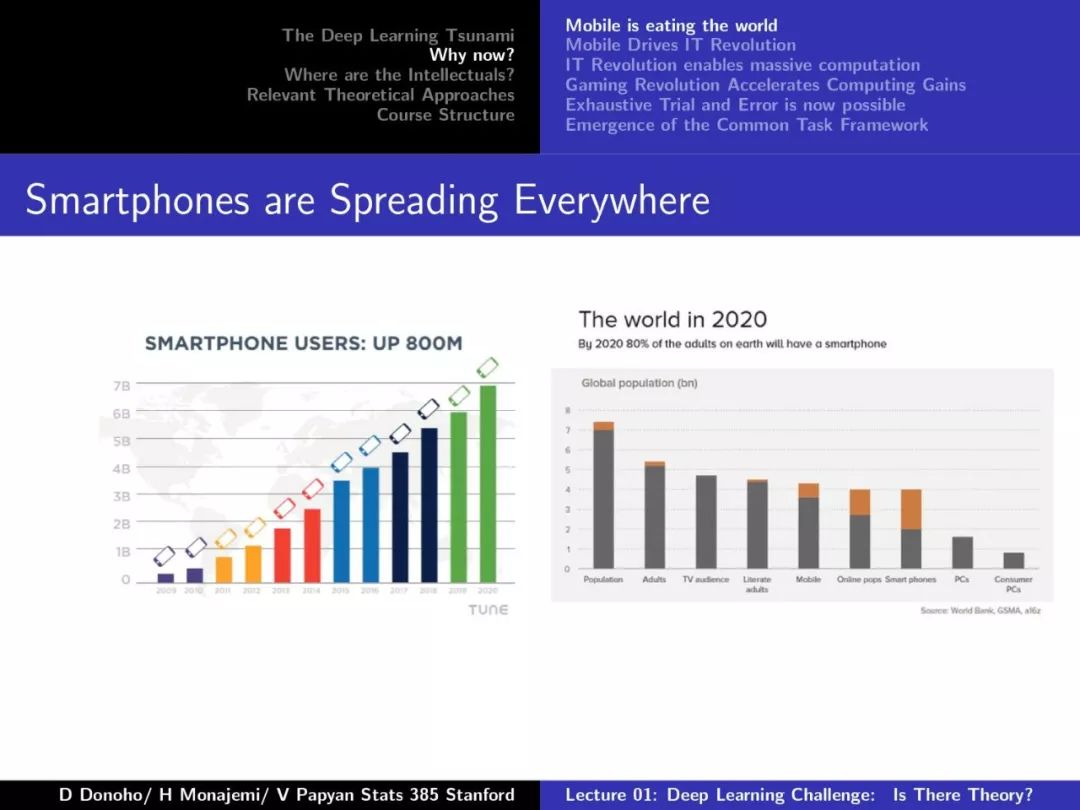
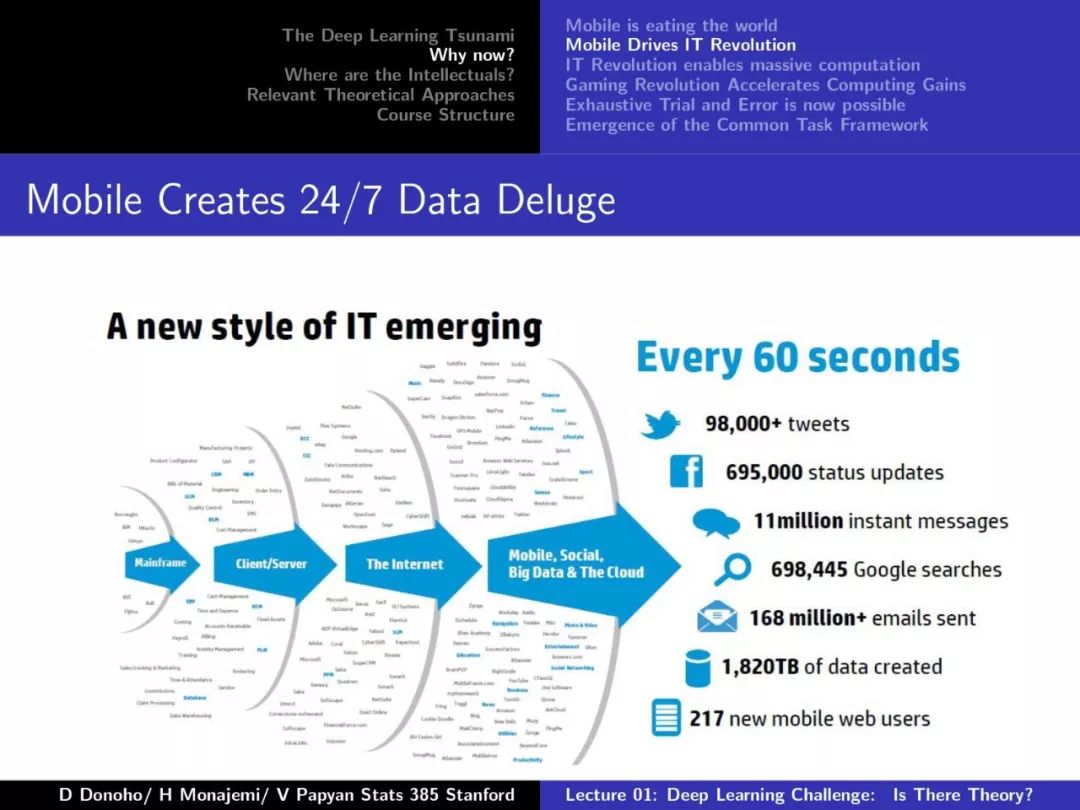

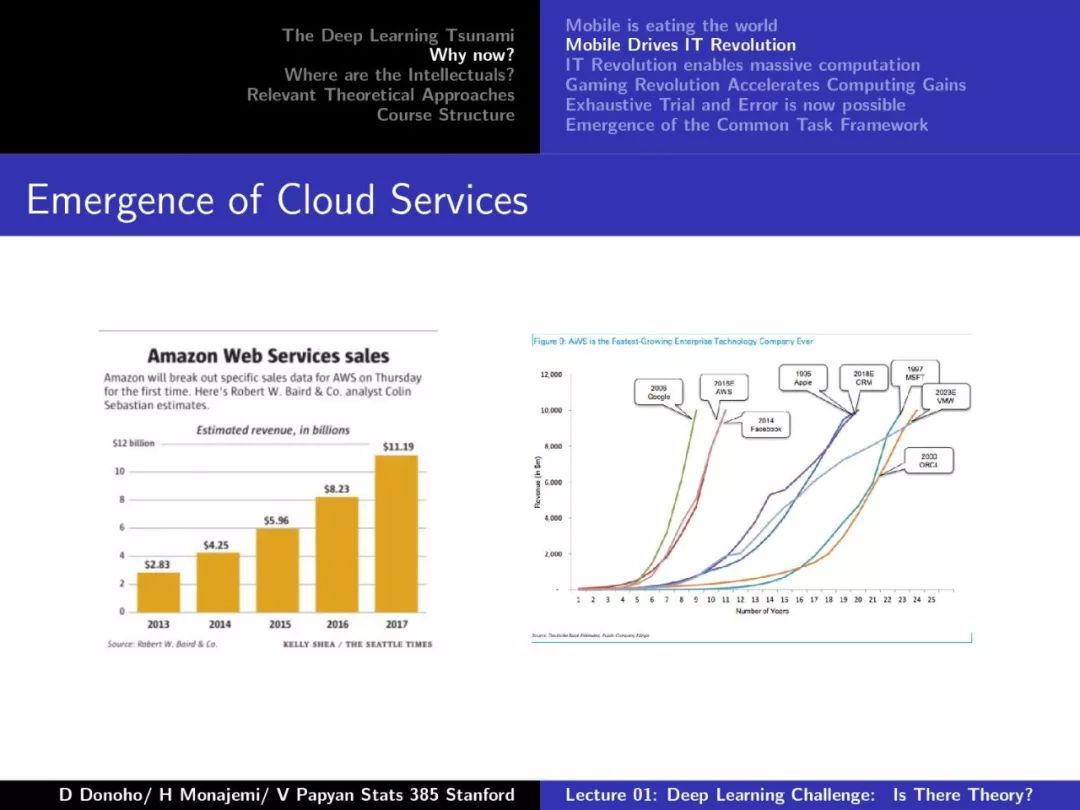

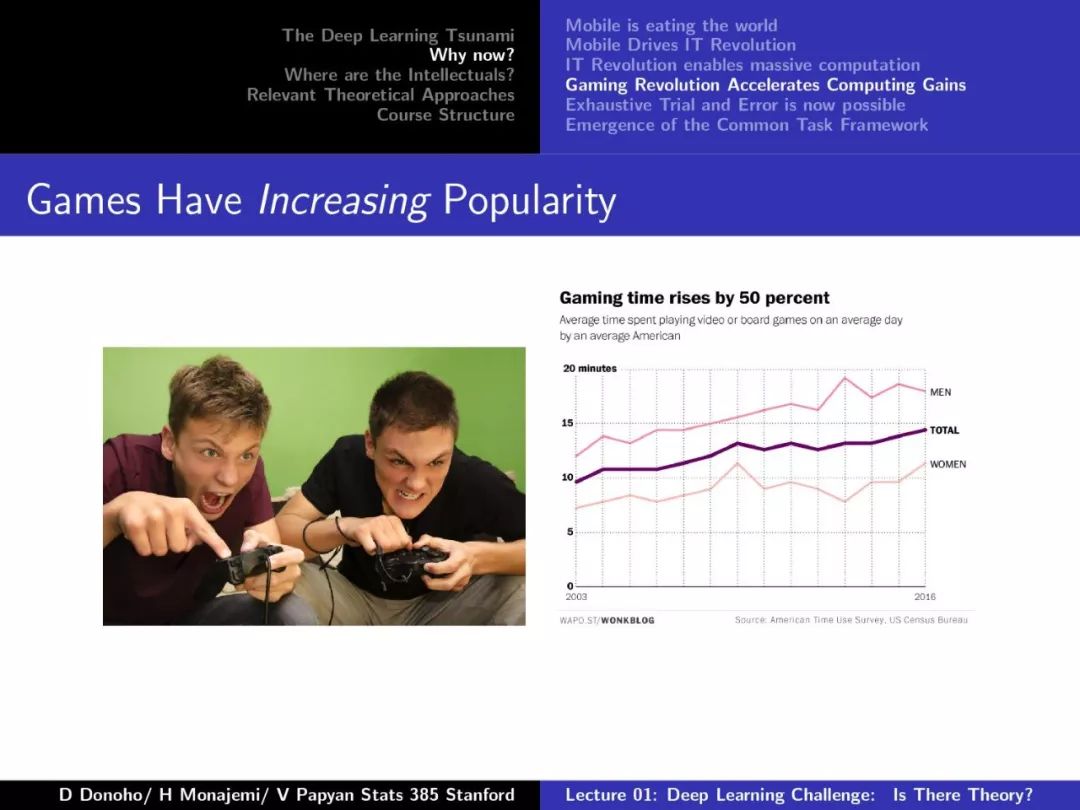



























【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




