从变分编码、信息瓶颈到正态分布:论遗忘的重要性

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
这是一篇“散文”,我们来谈一下有着千丝万缕联系的三个东西:变分自编码器、信息瓶颈、正态分布。
众所周知,变分自编码器是一个很经典的生成模型,但实际上它有着超越生成模型的含义;而对于信息瓶颈,大家也许相对陌生一些,然而事实上信息瓶颈在去年也热闹了一阵子;至于正态分布,那就不用说了,它几乎跟所有机器学习领域都有或多或少的联系。
那么,当它们三个碰撞在一块时,又有什么样的故事可说呢?它们跟“遗忘”又有什么关系呢?
变分自编码器
笔者曾经写过若干篇介绍 VAE 的文章。下面简单回顾一下。
理论形式回顾
简单来说,VAE 的优化目标是:
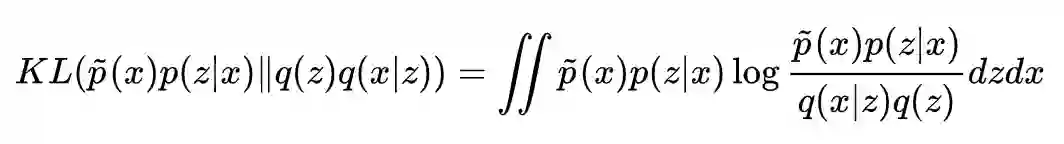
其中 q(z) 是标准正态分布,p(z|x),q(x|z) 是条件正态分布,分别对应编码器、解码器。具体细节可以参考再谈变分自编码器VAE:从贝叶斯观点出发。
这个目标最终可以简化为:
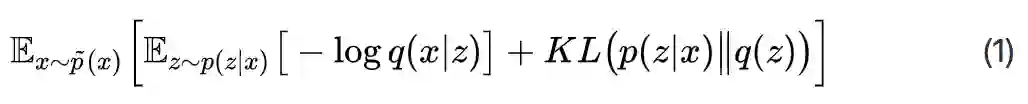
显然,它可以分开来看: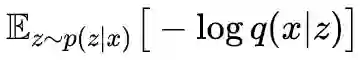
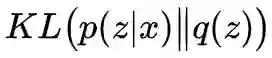
与自编码器的比较
所以,相比普通的自编码器,VAE 的改动就是:
1. 引入了均值和方差的概念,加入了重参数操作;
2. 加入了 KL 散度为额外的损失函数。
信息瓶颈
自认为本人介绍 VAE 的信息已经够多了,因此不再赘述,马上转到信息瓶颈(Information Bottleneck,IB)的介绍。
揭开DL的黑箱?
去年九月份有一场关于深度学习与信息瓶颈的演讲,声称能解开深度学习(DL)的黑箱,然后大牛 Hinton 听后评价“这太有趣了,我需要再看上 10000 遍...”(参考揭开深度学习黑箱:希伯来大学计算机科学教授提出「信息瓶颈」),然后信息瓶颈就热闹起来了。
不久之后,有一篇文章来怼这个结果,表明信息瓶颈的结论不是普适的(参考戳穿泡沫:对「信息瓶颈」理论的批判性分析),所以就更热闹了。
不管信息瓶颈能否揭开深度学习的秘密,作为实用派,我们主要看信息瓶颈能够真的能提取出一些有价值的东西出来用。
所谓信息瓶颈,是一个比较朴素的思想,它说我们面对一个任务,应用试图用最少的信息来完成。这其实跟我们之前讨论的“最小熵系列”是类似的,因为信息对应着学习成本,我们用最少的信息来完成一个任务,就意味着用最低的成本来完成这个任务,这意味着得到泛化性能更好的模型。
信息瓶颈的原理
为什么更低的成本/更少的信息就能得到更好的泛化能力?这不难理解,比如在公司中,我们如果要为每个客户都定制一个解决方案,派专人去跟进,那么成本是很大的;如果我们能找出一套普适的方案来,以后只需要在这个方案基础上进行微调,那么成本就会低很多。
“普适的方案”是因为我们找到了客户需求的共性和规律,所以很显然,一个成本最低的方案意味着我们能找到一些普适的规律和特性,这就意味着泛化性能。
在深度学习中,我们要如何体现这一点呢?答案就是“变分信息瓶颈”(VIB),源于文章 Deep Variational Information Bottleneck [1]。

▲ 信息瓶颈示意图
假设我们面对分类任务,标注数据对是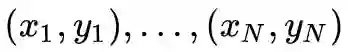
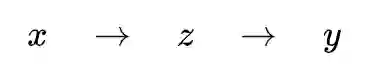
然后我们试想在 z 处加一个“瓶颈” β,它像一个沙漏,进入的信息量可能有很多,但是出口就只有 β 那么大,所以这个瓶颈的作用是:不允许流过 z 的信息量多于 β。跟沙漏不同的是,沙漏的沙过了瓶颈就完事了,而信息过了信息瓶颈后,还需要完成它要完成的任务(分类、回归等),所以模型迫不得已,只好想办法让最重要的信息通过瓶颈。这就是信息瓶颈的原理。
变分信息瓶颈
定量上是怎么操作呢?我们用“互信息”作为指标,来度量通过的信息量:
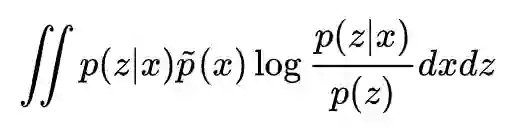
这里的 p(z) 不是任意指定的分布,而是真实的隐变量的分布,理论上,知道 p(z|x) 后,我们就可以将 p(z) 算出来,因为它形式上等于:
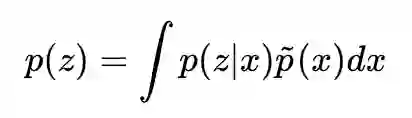
当然,这个积分往往不好算,后面我们再另想办法。
然后,我们还有个任务的 loss,比如分类任务通常是交叉熵:
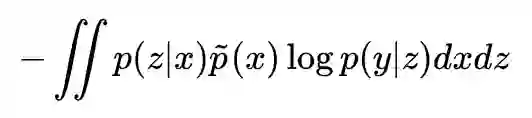
写成这样的形式,表明我们有个编码器先将 x 编码为 z,然后再对 z 分类。
怎么“不允许流过 z 的信息量多于 β”呢?我们可以直接把它当作惩罚项加入,使得最终的 loss 为:
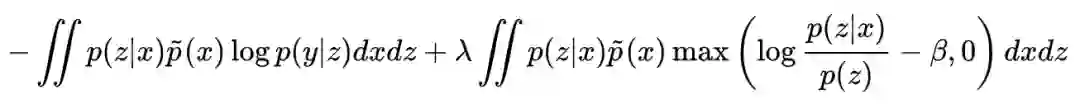
也就是说,互信息大于 β 之后,就会出现一个正的惩罚项。当然,很多时候我们不知道 β 设为多少才好,所以一个更干脆的做法是去掉 β,得到:
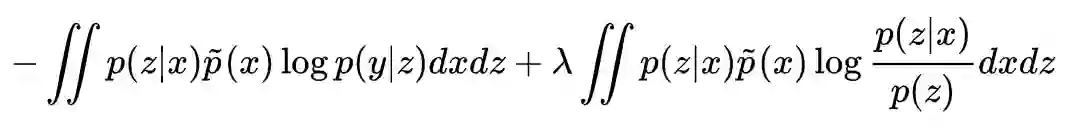
这就单纯地希望信息量越小越好,而不设置一个特定的阈值。
现在,公式已经有了,可是我们说过 p(z) 是算不出的,我们只好估计它的一个上界:假设 q(z) 是形式已知的分布,我们有:
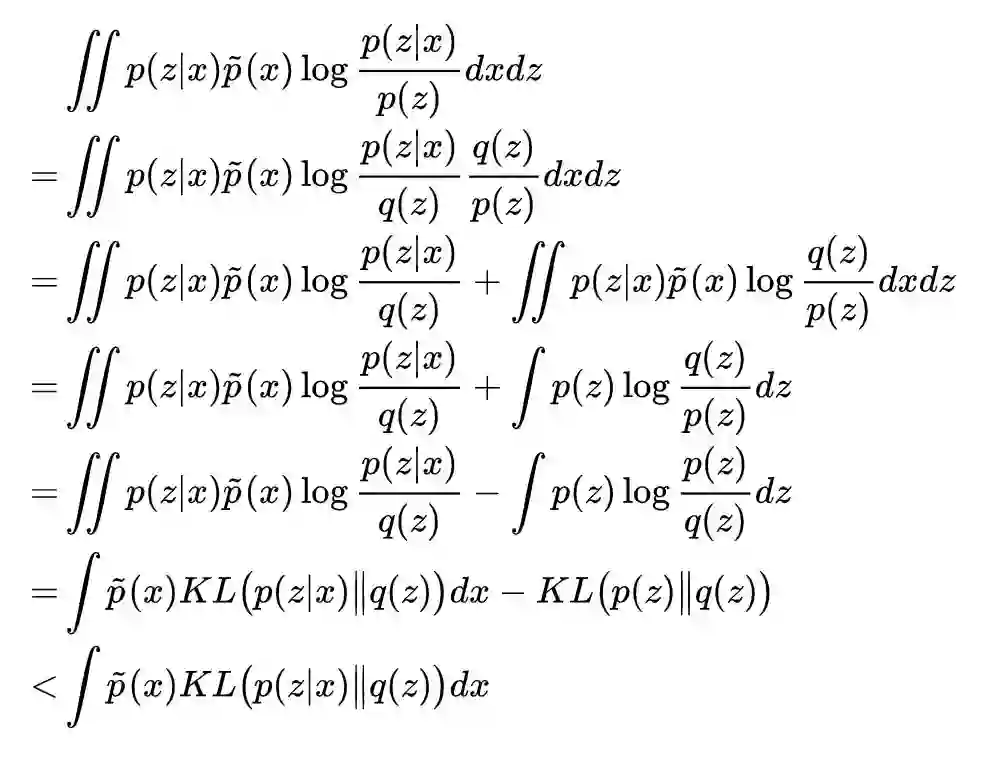
这就表明,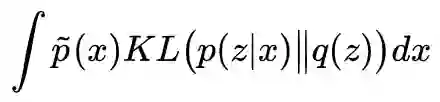
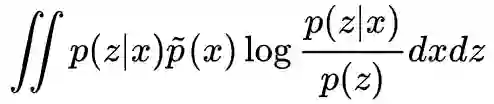
既然后者没法直接算出来,那么只好来优化前者了。所以,最终可用的 loss 是:
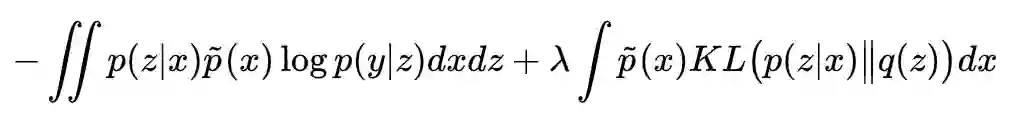
或者等价地写成:
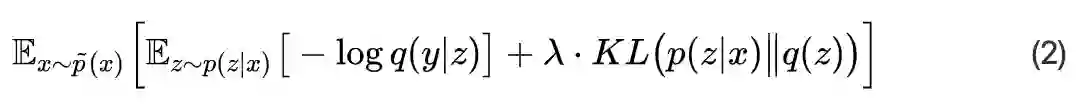
这就是“变分信息瓶颈”。
结果观察与实现
可以看到,如果 q(z) 取标准正态分布(事实上我们一直都是这样取,所以这个“如果”是满足的),(2) 跟 VAE 的损失函数 (1) 几乎是一样的。只不过 (2) 讨论的是有监督的任务,而 (1) 是无监督学习,但我们可以将 VAE 看成是标签为自身 x 的有监督学习任务,那么它就是 (2) 的一个特例了。
所以,相比原始的监督学习任务,变分信息瓶颈的改动就是:
1. 引入了均值和方差的概念,加入了重参数操作;
2. 加入了 KL 散度为额外的损失函数。
跟 VAE 如出一辙!
在 Keras 中实现变分信息瓶颈的方式非常简单,我定义了一个层,方便大家调用:
from keras.layers import Layer
import keras.backend as K
class VIB(Layer):
"""变分信息瓶颈层
"""
def __init__(self, lamb, **kwargs):
self.lamb = lamb
super(VIB, self).__init__(**kwargs)
def call(self, inputs):
z_mean, z_log_var = inputs
u = K.random_normal(shape=K.shape(z_mean))
kl_loss = - 0.5 * K.sum(K.mean(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), 0))
self.add_loss(self.lamb * kl_loss)
u = K.in_train_phase(u, 0.)
return z_mean + K.exp(z_log_var / 2) * u
def compute_output_shape(self, input_shape):
return input_shape[0]
用法很简单,在原来的任务上稍做改动即可,请参考:
https://github.com/bojone/vib/blob/master/cnn_imdb_vib.py
效果:相比没有加 VIB 的模型,加了 VIB 的模型收敛更快,而且容易跑到 89%+ 的验证正确率。而不加 VIB 的模型,通常只能跑到 88%+ 的正确率,并且收敛速度更慢些。
变分判别瓶颈
原论文 Deep Variational Information Bottleneck 表明,VIB 是一种颇为有效的正则手段,在多个任务上都提高了原模型性能。
然而信息瓶颈的故事还没有完,就在前不久,一篇名为 Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow [2] 的论文被评为 ICLR 2019 的高分论文(同期出现的还有那著名的 BigGAN),论文作者已经不满足仅仅将变分信息瓶颈用于普通的监督任务了,论文发展出“变分判别瓶颈”,并且一举将它用到了 GAN、强化学习等多种任务上,并都取得了一定的提升!信息瓶颈的威力可见一斑。
不同于 (2) 式,在 Variational Discriminator Bottleneck 一文中,信息瓶颈的更新机制做了修改,使它具有一定的自适应能力,但根本思想没有变化,都是通过限制互信息来对模型起到正则作用。不过这已经不是本文的重点了,有兴趣的读者请阅读原论文。
正态分布
通过对比,我们已经发现,VAE 和 VIB 都只是在原来的任务上引入了重参数,并且加入了 KL 散度项。直观来看,正则项的作用都是希望隐变量的分布更接近标准正态分布。那么,正态分布究竟有什么好处呢?
规整和解耦
其实要说正态分布的来源、故事、用途等等,可以写上一整本书了,很多关于正态分布的性质,在其他地方已经出现过,这里仅仅介绍一下跟本文比较相关的部分。
其实,KL 散度的作用,要让隐变量的分布对齐(多元的)标准正态分布,而不是任意正态分布。标准正态分布相对规整,均有零均值、标准方差等好处,但更重要的是标准正态分布拥有一个非常有价值的特点:它的每个分量是解耦的,用概率的话说,就是相互独立的,满足 p(x,y)=p(x)p(y)。
我们知道如果特征相互独立的话,建模就会容易得多(朴素贝叶斯分类器就是完全精确的模型),而且相互独立的特征可解释行也好很多,因此我们总希望特征相互独立。
早在 1992 年 LSTM 之父 Schmidhuber 就提出了 PM 模型(Predictability Minimization),致力于构建一个特征解耦的自编码器,相关故事可以参考从PM到GAN - LSTM之父Schmidhuber横跨22年的怨念。没错,就是在我还没有来到地球的那些年,大牛们就已经着手研究特征解耦了,可见特征解耦的价值有多大。
在 VAE 中(包括后来的对抗自编码器),直接通过 KL 散度让隐变量的分布对齐一个解耦的先验分布,这样带来的好处便是隐变量本身也接近解耦的,从而拥有前面说的解耦的各种好处。因此,现在我们可以回答一个很可能会被问到的问题:
问:从特征编码的角度看,变分自编码器相比普通的自编码器有什么好处?
答:变分自编码器通过 KL 散度让隐变量分布靠近标准正态分布,从而能解耦隐变量特征,简化后面的建立在该特征之上的模型。当然,你也可以联系前面说的变分信息瓶颈来回答一波,比如增强泛化性能等。
线性插值与卷积
此外,正态分布还有一个重要的性质,这个性质通常被用来演示生成模型的效果,它就是如下的线性插值:

▲ 引用自Glow模型的插值效果图
这种线性插值的过程是:首先采样两个随机向量 z1,z2∼N(0,1),显然好的生成器能将 z1,z2 都生成一个真实的图片 g(z1),g(z2),然后我们考虑 g(zα),其中:
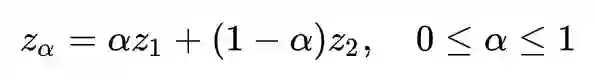
考虑 α 从 0 到 1 的变化过程,我们期望看到的 g(zα) 是图片 g(z1) 逐渐过渡到图片 g(z2),事实上也正是如此。
为什么插值一定要在隐变量空间差值呢?为什么直接对原始图片插值得不到有价值的结果。这其实和也和正态分布有关,因为我们有如下的卷积定理(此卷积非彼卷积,它是数学的卷积算子,不是神经网络的卷积层):
如果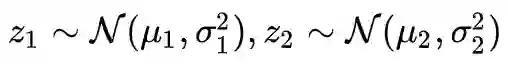
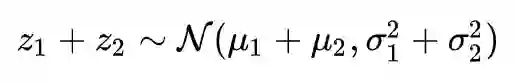
特别地,如果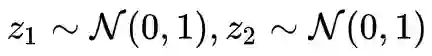
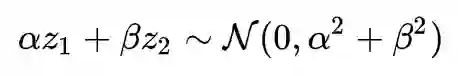
这也就是说正态分布的随机变量的和还是正态分布。这意味着什么呢?意味着在正态分布的世界里,两个变量的线性插值还仍然处在这个世界。这不是一个普通的性质,因为显然对两个真实样本插值就不一定是真实的图片了。
对于有监督任务,线性插值这个性质有什么价值呢?有,而且很重要。我们知道标注数据集很难得,如果我们能将有限的训练集的隐变量空间都合理地映射到标准正态分布,那么,我们可以期望训练集没有覆盖到的部分也可能被我们考虑到了,因为它的隐变量可能只是原来训练集的隐变量的线性插值。
也就是说,当我们完成有监督训练,并且把隐变量分布也规整为标准正态分布之后,我们实际上已经把训练集之间的过渡样本也考虑进去了,从而相当于覆盖了更多的样本了。
注:我们通常考虑的是空间域均匀线性插值,即 β=1−α 的形式,但从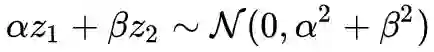
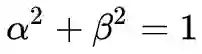
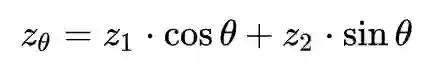
其次,可能读者会想到,当 GAN 的先验分布用均匀分布时,不也可以线性插值吗?这好像不是正态分布独有的呀?
其实均匀分布的卷积不再是均匀分布了,但是它的概率密度函数刚好集中在原来均匀分布的中间(只不过不均匀了,相当于取了原来的一个子集),所以插值效果还能让人满意,只不过从理论上来看它不够优美。另外从实践来看,目前 GAN 的训练中也多用正态分布了,训练起来比用均匀分布效果更好些。
学习与遗忘
最后,说了那么多,其实所有内容有一个非常直观的对应:遗忘。
遗忘也是深度学习中一个很重要的课题,时不时有相关的研究成果出来。比如我们用新领域的数据集的微调训练好的模型,模型往往就只能适用于新领域,而不是两个领域都能用,这就是深度学习的“灾难性遗忘”问题。又比如前段时间出来个研究,说 LSTM 的三个门之中,只保留“遗忘门”其实就足够了。
至于前面说了很长的信息瓶颈,跟遗忘也是对应的。因为大脑的容量就固定在那里,你只好用有限的信息完成你的任务,这就提取出了有价值的信息。
还是那个经典的例子,银行的工作人员也许看一看、摸一摸就能辨别出假币出来,但是他们对人民币非常了解吗?他们能画出人民币的轮廓吗?我觉得应该做不到。因为他们为了完成这个任务所分配的大脑容量也有限的,他们只需要辨别假币的最重要的信息。这就是大脑的信息瓶颈。
前面说的深度学习的信息瓶颈,也可以同样地类比。一般认为神经网络有效的基础是信息损失,逐层把无用的信息损失掉(忘记),最后保留有效的、泛化的信息,但神经网络参数实在太多,有时候不一定能达到这个目的,所以信息瓶颈就往神经网络加了个约束,相当于“强迫”神经网络去忘记无用的信息。
但也正因为如此,VIB 并非总是能提升你原来模型的效果,因为如果你的模型本来就已经“逐层把无用的信息损失掉(忘记),最后保留有效的、泛化的信息”了,那么 VIB 就是多余的了。VIB 只是一个正则项,跟其他所有正则项一样,效果都不是绝对的。
我突然想到了《倚天屠龙记》里边张无忌学太极剑的一段描述:
“要知张三丰传给他的乃是“剑意”,而非“剑招”,要他将所见到的剑招忘得半点不剩,才能得其神髓,临敌时以意驭剑,千变万化,无穷无尽。倘若尚有一两招剑法忘不乾净,心有拘囿,剑法便不能纯”。
原来遗忘才是最高境界!所以,本文虽然看上去不扣题,但却是一篇实实在在的散文——《论遗忘的重要性》。

▲ 《倚天屠龙记之魔教教主》截屏
参考文献
[1] Alexander A. Alemi, Ian Fischer, Joshua V. Dillon and Kevin Murphy. Deep Variational Information Bottleneck. In International Conference on Learning Representations (ICLR), 2017.
[2] Xue Bin Peng, Angjoo Kanazawa, Sam Toyer, Pieter Abbeel, Sergey Levine: Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow. CoRR abs/1810.00821 (2018)

点击以下标题查看作者其他文章:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客



