谷歌新发布了一个精确标注动作的数据集,堪称ImageNet视频版

作者: Chunhui Gu & David Ross
编译:魏子敏,龙牧雪,谭婧
以下为google blog原文,大数据文摘对其进行了编译:
在计算机视觉领域,教会机器在视频中理解人类行为是一个非常基础的研究课题,这一点对于视频搜索和发现,运动分析以及手势交互都至关重要。过去几年,尽管我们在识别图片中的物体这个领域取得了一些令人兴奋的突破,但是,识别人的动作仍然是一个比较大的挑战。
这是由于,视频中的“动作”识别,天然地比物体识别更困难,这就使得建立一个优质的动作标注视频数据集非常不容易。目前确实存在很多重要的动作标注数据集,例如,ucf101,activitynet和DeepMind的Kinetics。尽管这些数据集都采用图像分类标签的标注结构,给每个视频或视频剪辑的动作进行了一定的标注。但是,复杂的场景下,标注了多人执行不同操作的数据集在业内依然空白。
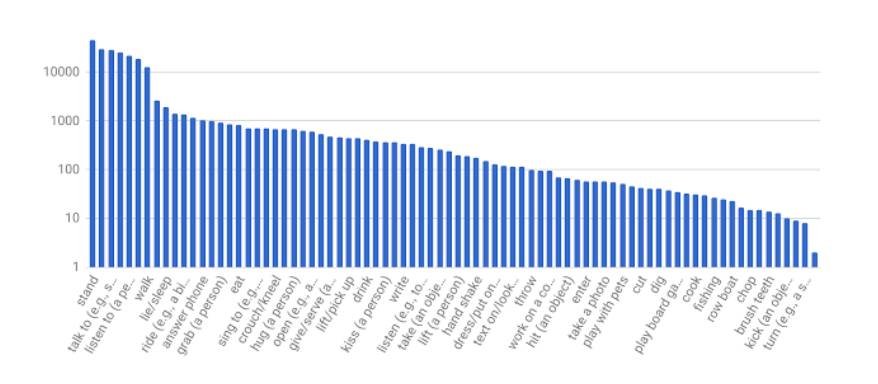
为了促进对人类动作识别的进一步研究,我们发布了AVA(atomic visual actions)。这个数据集为视频中的每个人都打上了多个动作标签。AVA由YouTube上公开视频的URLs组成,标注了80个独立个体行为(例如“走”、“踢(一个物体)”、“握手”,共有57.6k视频片段,96k标记的人类行动,以及总的210K动作标签。你可以浏览网站(https://research.google.com/ava/)来探索数据集和下载标注,以及阅读我们的arXiv论文,论文描述了数据集的设计与开发(论文地址:https://arxiv.org/abs/1705.08421)。
相比其他的动作数据集,AVA数据集有以下这些特点:
以人为中心进行标注:每个动作标签都基于人物本身,而不是一段视频或者剪辑片段。因此,我们能够为不同动作中的各类人加上不同的标签,这一点非常常见。
原子级视觉动作:我们对需要标注的动作进行了合理的时间限制(3秒钟),以确保动作符合人的生理机能,同时有明显的视觉特征。
真实视频作为视觉材料:我们使用不同题材和国家的电影作为AVA的标注材料,进而确保数据库中包含各类型的人类行为。

视频来源中的3秒视觉片段标签,用方框标注出每个动作素材(为确保清晰,每个例子中只出现了一个框。)
为了创作AVA数据集,我们首先从YouTube上搜集了一批种类各异的长视频内容,以“电影”和“电视剧”作为主要标签,其中的专业演员来自不同国家。我们从每个视频中剪辑出了一段15分钟的片段,并且标准化地将这些片段组合成为了一段视频样本,每一段这样的样本都包换300个无重叠的3秒片段。这一采样策略确保了相关内容中动作的连贯有序。
接下来,我们手动标注了所有以3秒隔断、被方框框起来的动作。对于每一个标注框中人,标注者会从一个之前选出来的动作词库(包含80类目)中选择合适的标签,来描述框中人的动作。这些动作将被划分为三组:姿态类,人-物交互类,人-人交互类。为了确保标签对于动作的穷尽性,我们给AVA的所有标签打上了较多的分类,我们将其总结如下:
通过AVA,我们得到了一些有趣的统计数据,这是之前任何数据集中都没有体现出来的。比如,由于大量人物都被标注了至少两个动作,我们可以发现当多个动作标签同时出现的时候,动作的组合具有一定规律。下面这张图显示了AVA中出现最频繁的“动作组合”。这印证了我们的常识:人们通常一边“唱歌”一边“玩乐器”,在“和孩子一起玩”的同时“把一个人举起来”,在“接吻”时“拥抱”。
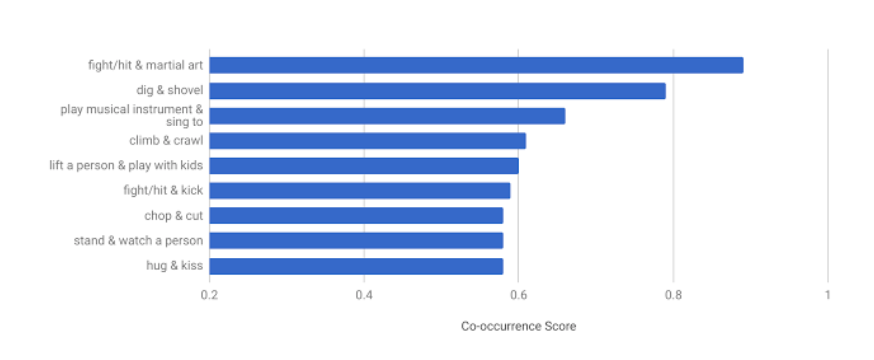
图:AVA中同时出现最多的“动作组合”
(吹黑管的小编哭晕,永远不能一边唱歌一边演奏呢)
为了验证AVA数据集中人类动作识别系统的有效性,我们在AVA上实现了一个已有的深度学习基准模型,这个模型在一个小得多的JHMDB数据集上表现良好。由于比例、背景、摄影角度的原因,这个模型在AVA上的表现属于中等水平(18.4%mAP)。这表明,在未来几年中,AVA都将对开发和验证新的动作识别算法非常有用。
我们希望AVA的发布能推动动作识别的进步,并为多人同时执行复杂动作标签之上的建模提供机会。我们会持续扩大和改进AVA,并且非常希望得到你们的反馈。
优质课程推荐《人工智能的数学基础》
往期学员评价(by 张铮)
《人工智能的数学基础》这门课值得AI新人学习。
之前看李航的《统计学习方法》一直看不懂。上了这门课才知道以“凸优化-SVM”为一轴,以“梯度下降-矩阵”为一轴,内容相互交叉。学习课程之后,再看机器学习基础书籍就没有太多压力了。 真实体会。


往期精彩文章
点击图片阅读






