继 Google、IBM 之后,Facebook公布行为识别数据集!人工智能的下一个关键将是理解视频,并读懂你的行为
转载声明:本文转载自「DeepTech深科技」,作者:詹子娴、黄珊
搜索「mit-tr」即可关注。
2017 年 12 月 29 日,Facebook 与麻省理工学院计算机科学与人工智能实验室(CSAIL)合作公布了一个带有标签的大型视频数据集 SLAC(Sparsely Labeled ACtions),包括了 200 个动作类别、52 万个未剪辑的视频以及 175 万个剪辑注释,另外 Facebook 也表示,使用这个框架注释剪辑(annotating a clip)平均只要 8.8 秒,相较于传统手动剪辑、动作定位的方式,能够省下 95% 的标注时间,可帮助研究人员更快速、有效率的训练机器识别各种动作。

图|Facebook 公布的 SLAC 数据集用于训练 AI 识别动作,像是除草、贴壁纸、使用划船机健身器材等一连串的动作。(图片来源:Facebook)
参与这项计划的 Facebook 研究科学家严志程在他的 Facebook 帐号上表示:“SLAC 不只是为动作识别提供了一个新的基准,也是一个能够有效预先训练视频模型(pre-train video models)的大型数据集,之后通过迁移学习转到小规模的数据集上,只要经过微调就能取得很好的效果。”
而这也是继 Google、IBM 之后,又有一家 AI 巨头公司公布了视频数据集,希望让机器能够理解人类生活的动作。为什么这些大型公司都纷纷将注意力放到了视频上,因为对于计算机视觉技术的突破已经从静态的图像识别转向到了视频理解,甚至是希望达到人类程度的理解。
视频理解是计算机视觉的下一个前沿
计算机视觉(CV)技术发展了数十载,在 2012 年出现了一个重要的分水岭,那就是深度学习技术的应用及带来的突破。2012 年的大规模视觉识别竞赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge),师承深度学习之父 Geoffrey Hinton 的多伦多大学研究生 Alex Krizhevsky 以 GPU 训练他开发的深度卷积神经网络结构 AlexNet,赢得了该届比赛的冠军。
ILSVRC 挑战赛自 2010 年开办,先前表现最佳的系统错误率仍超过 25%,Alex Krizhevsky 通过深度学习将错误率大幅降低到只有 15.4%,这是首次有参赛者以“深度学习”架构参赛,而且还以很大的差距领先其它队伍,因此被视为是 AI Big Bang(AI 大爆发)的起源,从此之后深度学习成了学界、行业界的主流,到了 2015 年错误率进一步降低到只有 3.7%,比人眼识别的错误率区间 5~10% 还低,2017 年冠军的错误率更只有 2.3%。先不辩论计算机辨认图片是否真的比人类更精准这个问题,但至少机器识别图像可以说是接近相当完美。
众多研究人员利用深度学习并在比赛上屡创佳绩,若再继续举办类似的比赛已无太大的意义,因此,2017 ILSVRC 以最后一届的身份举办,未来对于计算机视觉技术的期待将从图像识别、物体识别转向其它有待突破的领域,例如计算机视觉理解、视频理解。
像素的世界已经超过了图片
“像素(pixel)的世界已经超过了图片(picture),然而多年来视频仍是机器学习研究人员面临的挑战”,“视频就像是计算机视觉里的暗数据,我们正在开始关注数字世界的暗数据问题,”Google 人工智能与机器学习首席科学家李飞飞在 2017 年 Google Next Cloud 大会上清楚的指出。
视频在当代人的生活中越来越重要,除了观看之外,更通过智能手机、GoPro、无人机等自产了许多用户生成内容(UGC),YouTube、Facebook、Snapchat 每日视频观看次数也持续升高,在未来几年还会有许多设备增加,像是智能监控摄影机到自动驾驶汽车等,这些设备都是以相机作为感知的工具、以影像作为理解世界的入口,因此,如何让机器看得懂视频,对于 AI 的技术发展及商业应用只会越来越重要。
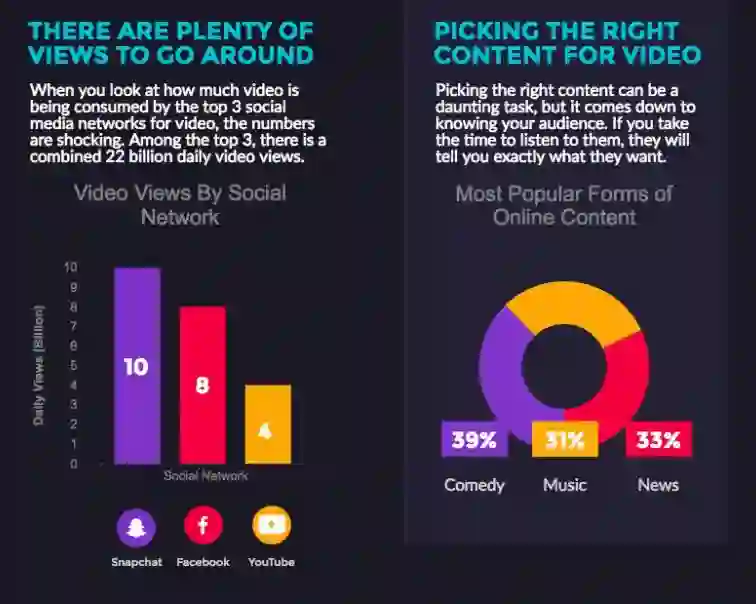
图| Snapchat、YouTube、Facebook 是视频的主要观看平台。(数据来源:RENDRFX)
生活是动词,不是名词
有人可能会认为,机器已经可以识别图像了,会分辨猫、狗、汽车、红绿灯,为什么还需要机器看懂视频,这之间有差别吗?答案是肯定的。
“生活不仅是一系列的快照,是随着时间变化在现实世界发生的事,这是关于动词,而不是名词,”专攻机器人感知的初创公司 TwentyBN 产品主管 Moritz Mueller-Freitag 道出重点。而 TwentyBN 利用一年的时间建立两个视频数据集:一是针对人类-对象互动的 Something-something 数据库,另一则是关于手势动作的 Jester 数据集。
他进一步解释,深度学习近年来取得了历史性的进步,可以在静止的图像中识别物体,表现不输给人类,但是计算机理解视频的空间和时间仍然是一个未解的问题。因为照片只是一张静态图片,但一段视频则是“动作的叙述”,透露的信息包括了三维几何、材料性质、物体持久性、重力等。

图|TwentyBN 建立手势动作的 Jester 数据集。(数据来源: Moritz Mueller-Freitag 的 Medium)
举例来说,一张照片上有一个人站在路边的角落,但是照片并不会告诉你“动作的叙述”:这个人在那边站了多久?是呆站着还是来回徘徊?也就是说,照片可提供的资讯在某些领域或应用是不够的,例如安防。
从事 AI 安防方案开发,并在美国市场拿下不少大型订单的初创公司盾心(Umbo CV)创办人关宇翔就表示,安防领域通常关注暴力行为及犯罪行为,爬围墙、挥舞手臂等动作可能只有短短 5 秒钟,另外,假设有一个人在人烟稀少的 ATM 附近徘徊,系统侦测他滞留过久,就会向管理者发出警报,这些都牵涉了一段时间跟连续性的动作,因此盾心在开发并训练机器时就是同时利用照片及视频,因为只是光靠照片作为训练素材,开发出来的安防产品肯定不够聪明,品质自然就不合格。
用原子动作教机器
对我们人类来说,对于物理世界的详细理解是很直觉化的,但是在人工智能和机器人技术的当前应用中还是有很大程度被忽略了。要突破这个发展现况,首先就是要有大量的数据,就像先前李飞飞和普林斯顿大学教授李凯发起的 ImageNet 计划,建立一个多达 150 亿张图像的庞大数据库。帮助 AI 理解视频也可以采取类似的方式,需要“视频”的训练集。
目前有一些公开的视频标签数据集,像是 UCF101、ActivityNet、或是 DeepMind 的 Kinetics。不过,这些数据集主要是标注了影像的分类,而不是针对包含了多人动作的复杂场景,不过一直到 Google 公布了原子视觉动作(AVA)数据集,才将人类动作分类的更为明确和细致。
Google 官方博客指出,识别人类动作仍然是一个巨大的挑战,原因在于人类动作的定义不如视频中的对象来得完善,AVA 利用 YouTube 上的公开视频为基础,区分出 80 个原子动作(atomic actions),例如行走、踢(一个对象/东西)、握手等等,共 21 万个行动标签。

图|Google AVA 数据集利用电影、电视为基础,区分出 80 个原子动作(图片来源:Google Blog)
不久前,MIT IBM Watson AI Lab 公布了一个视频数据集 Moments in Time Dataset,首先是一举扩大了数据的规模,共有 100 万个 3 秒钟的视频片段,同时深化动作的情境,涵盖了广泛的英语语意、以人为中心的数据,他们建立了 300 多个日常生活常见的“动词”标签,而且是描绘了非常具体的情境,像是化妆、瞄准、除草或是体育赛事的跳高等,同样是采取把事情分解成原子动作的概念,希望能供研究人员使用以协助训练机器学习系统的开发及应用。

图|MIT IBM Watson AI Lab 公布了具有 100 万个视频的数据集 Moments in Time Dataset,建立了 300 个动作标签。(图片来源:MIT IBM Watson AI Lab )

图|Moments in Time Dataset 数据集同样是采取把事情分解成原子动作的概念,建立动作标签。(图片来源:MIT IBM Watson AI Lab )
参与这项专案的 IBM 视频分析科学家 Dan Gutfreund 指出,这不只是标注一些基本动作如跑、走、笑而已,如果要让机器了解差异,例如跳(jump)跟跳高(jump high),就必须考量“跳高”这一项特殊的活动,因为跳高是环绕着“跑”、“跳”、“拱桥”(arching)、“落下”到“着陆”这些基本动作的组合。
此外,这个数据集还考量到了不少独特但重要的地方,例如,有时候你看不到动作但听到声音,你还是会知道是在做什么,因此,他们也把只有背景声音的视频像是“拍手”的声音放进数据集内,“这有助于开发多模的动作识别模型,”他说。
另外,就是考量标签间的变异性(inter-label variability),例如“打开”(open),一只狗张开嘴巴、或是一个人打开门,看起来就是不一样,但都是同一个英文动词,这就是所谓的标签变异性,而这些情况就会被放进一个“开放”类别,以帮助机器理解比较棘手的动词。
另外,也可以发现 Google AVA 和 Moments in Time Dataset 的视频都是 3 秒钟,Dan Gutfreund 表示,选择 3 秒并不是随意决定的,而是人类短期记忆的平均时间值,也就是说,3 秒虽短但也足够长到让人类是有意识地在处理或进行某个事件。
在商业上有很大的潜力
也因为视频理解在商业上有很大的潜力,例如视频平台、自动驾驶、安防等涉及到视频的场景都很适合通过 AI 技术做的更深入,目前已经有越来越多的企业投入,像是 Facebook、阿里巴巴、今日头条 AI 实验室等。
今日头条人工智能实验室对 DT 君表示:“AI 在视频理解领域正处在一个高速成长期,事实上 AI 在视频理解上做的要比在语音识别领域还要好一些。”
头条有很多辅助创作者创作的小工具都是依赖于人工智能对视频的理解,比如帮助创作者在视频内自动选取封面图,以及从视频中自动选取优质的视频段落等等。因为很多创作者上传完视频封面都是默认的视频第一帧,但很多时候视频第一帧的效果并不好,机器可以帮助选择视频中优质的一帧或者段落作为视频封面。
同时,人工智能也参与到了审核低俗视频的工作中,因为像火山小视频、抖音都属于 UGC 用户自上传,并且每天的内容上传量非常大,一些视频可能会涉及到色情或者低俗,机器可以和人工结合,帮助审核,极大地提高了效率。
另外,也有不少人锁定在运动领域,让计算机观看篮球、足球等比赛的影片,学习各种规则及动运员的技巧,通过深度学习技术让计算机能够判读球员或球队的战术,同样的,比赛也是一种涉及时间序列、连续动作的变化,利用视频训练会比图像来得适合得多。
视频理解是另一场资本竞赛?
不过,教计算机如何理解视频比理解图像要困难得多。很多事是在一瞬间发生,人类可以通过感官快速、轻松地处理,但机器需要算法才能理解物理世界以及行为者所执行的无数种行为,同时,手动替视频下标签以及机器的训练过程都得花上更多时间。
“视频比较难处理,要处理的问题复杂性比物体识别更高一步,”Dan Gutfreund 说,因为物体是物体,例如一条热狗就是热狗,但是视频常有许多动作,动作往往是一个复杂概念的集合,可以是简单的行为,但也可能是带有复杂的情绪、意图。
阿里巴巴 iDST 首席科学家任小枫在 2017 年 10 月的 AI Frontiers 大会上就指出,淘宝的购物搜寻从最初的文字进展到影像,越来越多商家放上产品解说、营销的视频或是开直播,故视频理解是 iDST 研究的方向之一,他举了优酷的植入式广告为例,他们内部开发了一个方案用于扫描 3D 物体,并且试图加入视频理解功能,有时成功但有时则不奏效。
除了要让机器理解抽象事物本身就很难之外,还有一个实际的问题,那就是成本,视频的数据量比图像大非常多,如果又是高画质影片,就得增加更多的运算资源、储存空间,这些都是昂贵的支出。“对初创公司来说,要花更多的钱在存储和处理计算资源上,你就必须考量成本效益,客户愿不愿意买单,”关宇翔说。视频理解就是另一场资本的竞赛。
而今日头条人工智能实验室对于 AI 理解视频内容的难点也提到了同样的看法,“相比图像,视频的信息更复杂,将其模型化的难度更大。其次视频内容的数据量更大,视频理解对存储计算资源以及实时性的要求也会更高。”
Google 首席产品经理 Apoorv Saxena 先前接受媒体采访时就指出,接下来就是做到通过视频中不同的图像、场景来描述每个场景,或是 AI 看完一部影片后总结它看到了什么,至少目前看来是很有希望做到。另外一个就是将视频理解与虚拟现实(virtual reality)结合,可以创造出一些有趣的突破,这是值得继续关注的领域。
利用迁移学习扩大应用
随着学术界及企业对于研究视频理解的投入,这个领域已经有些进展,但研究人员和科学家想得不光只是希望机器能够理解一个动作而已,这只是照亮暗数据的第一步而已,然后呢?
将视频理解与迁移学习(Transfer Learning)结合就是一个重要的方向,当机器能够有效率地识别一个行为,就希望能把这个知识转移到另一个情境,像是当机器已经看过人奔跑的视频,下次看到一个马在奔跑的视频,也要能够理解这是相同动作,“这就是‘迁移学习’,对于 AI 的未来会是非常重要,可以应用的领域像是自动驾驶、老人照护等,让我们看看机器如何实现迁移学习,”Danny Gutfreund 强调。
迁移学习是 AI 中的一门技术,被人工智能大牛吴恩达视为是“继监督学习之后,将引领下一波机器学习商业化浪潮的技术。”是指把在某一个环境下已经训练好的模型拿到新的环境下使用,而不用从头开始做起,概念就很像是当你已经学会西班牙文,再去学英文就会比从头学起来得容易。迁移学习的优势一来是可以缩短开发时间,二是可能解决训练数据不足的问题,像是手机品牌 HTC 近年来转型耕耘医疗领域,其健康医疗事业部总经理张智威曾公开表示,内部在开发中耳炎识别模型时,因为缺乏足够数据,所以尝试使用迁移学习以提高模型准确率。
Moritz Mueller-Freitag 也提出了类似看法,“如何从对物理概念的理解用来提供实用的现实解决方案?我们相信可以在迁移学习中找到答案。”他进一步指出,人类很习惯用类比的方式思考或做事,通过迁移学习,我们可以把一个已经用视频数据集训练过的神经网络,将其功能转移到特定的业务应用上,或是去解决更难的复杂问题。
在真实世界中,生活不只是一系列的快照,也不仅仅是认识图像中的动物、花朵或汽车,如果期待 AI 能够越来越像人,或至少要达到有如人类般感知周遭一切的能力,那么理解视频就是第一步,至少,现在这个暗数据已经因众多科学家投入而逐渐被点亮。
-End-





