开发 | 如何用FPGA加速卷积神经网络(CNN)?
AI科技评论按,本文来源于王天祺在知乎问题【如何用FPGA加速卷积神经网络(CNN)?】下的回答,AI科技评论获其授权转发。
以下主要引用自西安邮电大学李涛老师关于连接智能和符号智能的报告,以及fpl2016上ASU的 Yufei Ma的文章和slide,推荐大家去读下原文。
Scalable and Modularized RTL Compilation of Convolutional Neural Network onto FPGA
地址:http://fpl2016.org/slides/S5b_1.pdf
我做过一些计算加速的工作,个人感觉要入手先要想好几个问题: 要加速的是什么应用,应用的瓶颈是什么,再针对这个瓶颈,参考前人工作选择合适的方案。
过早地执着于fpga的技术细节(用hdl还是hls,用啥芯片,用啥接口)容易只见树木不见森林。现在software define network/flash/xxx,已然大势所趋。之前开组会时跟同志们聊过,算法是纲,纲举目张;软件是妈,软件是爹,软件比基金委都亲。所以推荐先把cnn的算法看一下,拿一些开源代码跑一下经典的例子(lenet, alexnet, etc)看好输入输出,摸清算法。
比如以下是一个lenet的cpp和opencl的实现:
nachiket/papaa-opencl
地址:https://github.com/nachiket/papaa-opencl
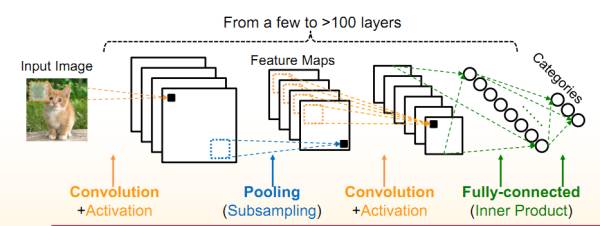
以下图片源自Yufei Ma的Slide。
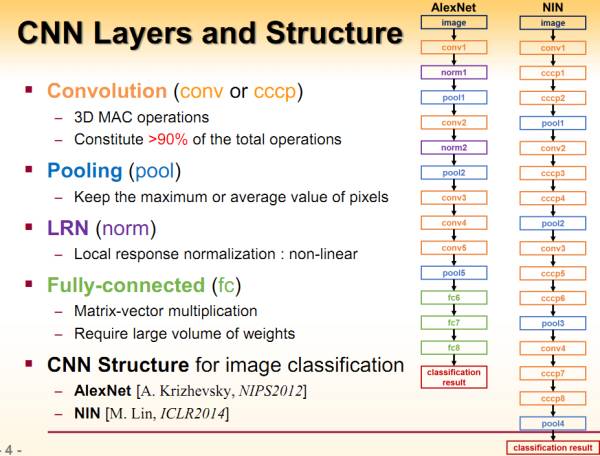
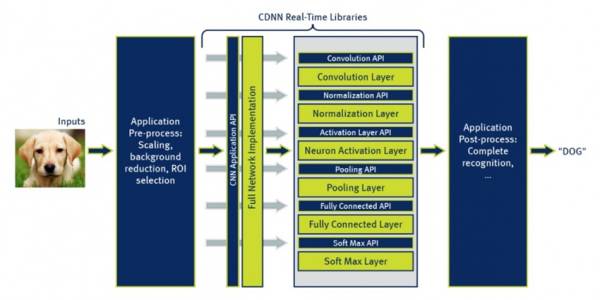
可以看到cnn算法主要由conv ,pooling,norm等几个部分组成。工作时将image跟weight灌进去,最终得到预测结果。
接下来拿profiler(比如perf)去分析下软件算法,找找热点和性能瓶颈。在cnn里面主要耗时的就是conv二维卷积了。性能瓶颈也主要在于卷积时需要大量乘加运算,参与计算的大量weight参数会带来的很多访存请求。
接下来考察下前人的工作和当前的灌水热点。按理说这种大量的乘加运算用dsp应该不错,但是在cnn中大家并不需要这么大的位宽,有时候8位就够了。dsp动辄32/64位的乘加器实在是浪费。于是乎大家就开始减位宽,多堆几个运算单元。面对大量的访存请求,大家就开始设计各种tricky的缓存了。
以下是大家的一些灌水方向:


于是就有了以下各路硬件设计:


有人照着dsp风格去设计加速器:
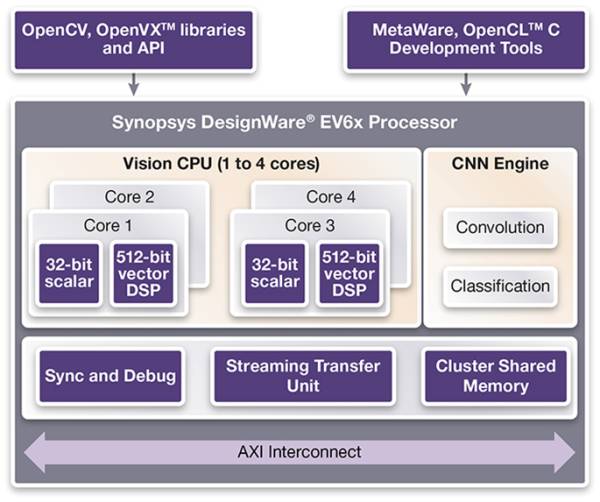
ceva也出了一系列面向CNN的IP:
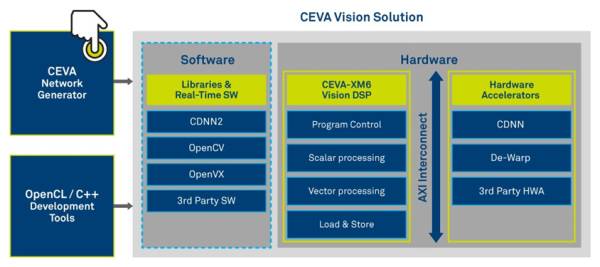
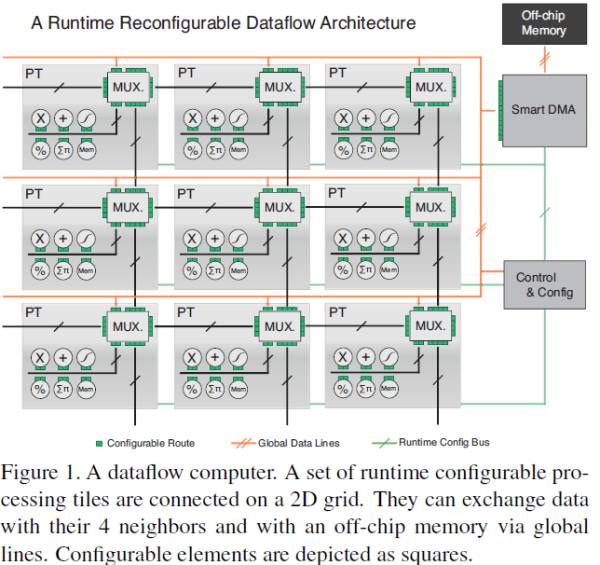
有人用了脉动阵列或者Dataflow的风格:
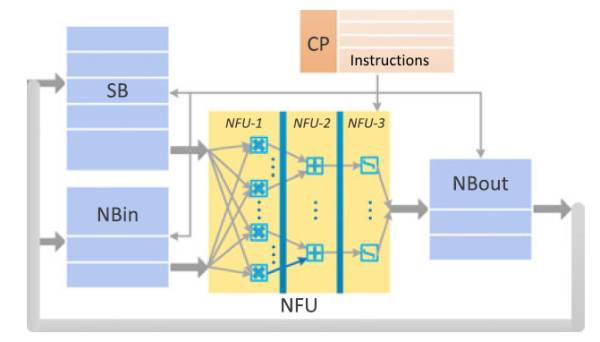
有人设计了专用的芯片比如计算所的Cambricon:
还有的就是你提到的fpga。
所有的事情到了硬件层面实际上能用的手段也就有限了。不外乎堆资源和切流水两招。再不然就是做一些bit level的小技巧,比如乘法器变查表之类的,这些技巧在很多二十年前的dsp教材里面都描述得很细致了,拿来用就好。比如这本书亲测有效。
VLSI Digital Signal Processing System--Design and Implementation by Keshab
典型的fpga实现可以参考Yufei Ma的文章,不论是conv,还是pooling,依葫芦画瓢设计data path,切好流水,再想好状态机加上控制信号。这些就看大家撸rtl的基本功了。
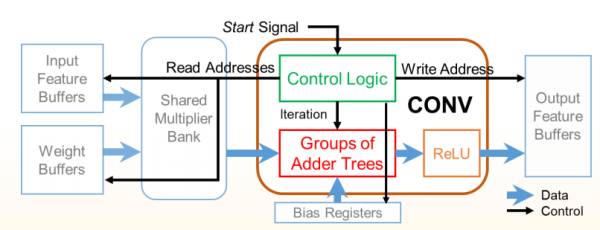
比如Conv模块如下图,主要拿一堆乘法器以及加法器树搭好data path,切好流水,接着加上控制信号。
Pooling也是大同小异:
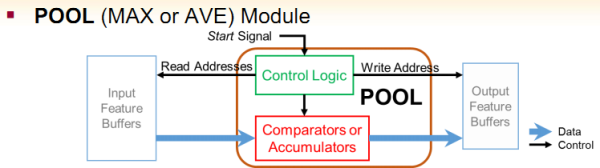
还有Norm:
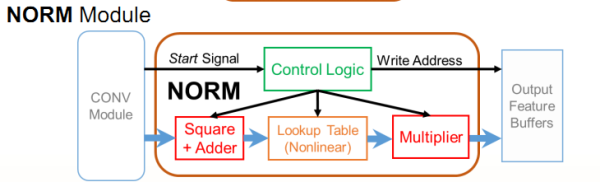
最后把这些模块通过router连接,外面再套一层控制模块,封成ip就好了。
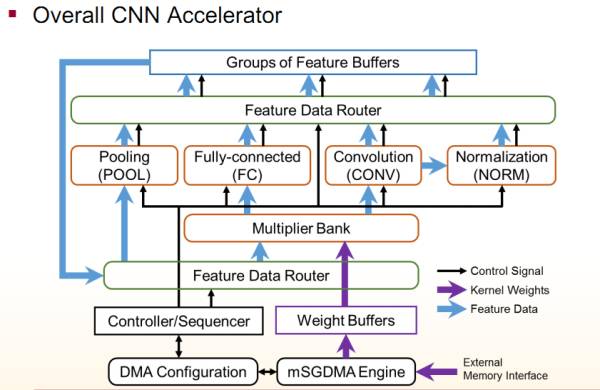
剩下的就是集成进你的系统(microblaze, nios还是arm,配好dma,写好灌数据的驱动,这些就是各有各的道儿了)。推荐动手码rtl前先写好文档,约定好端口,寄存器和软件api,否则边写边改容易乱。
整体来说,cnn这种应用流水线控制相对cpu简单,没有写cpu的那一堆hazard让人烦心,也不用写汇编器啥的。太大的cnn放在fpga里挺费劲,做出创新很难,但是fpga上写个能用的lenet这种级别的cnn还是挺容易的。最后还可以依照惯例跟cpu比性能,跟gpu比功耗。
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————





