学界 | 小改进,大飞跃:深度学习中的最小牛顿求解器
选自arXiv
作者:João F. Henriques等
机器之心编译
参与:Huiyuan Zhuo、思源
牛顿法等利用二阶梯度信息的方法在深度学习中很少有应用,我们更喜欢直接使用一阶梯度信息求解最优参数。本论文提出了一种新型基于二阶信息的最优化方法,它的内存占用与带动量的 SGD 一样小,但当收敛速度却比只使用一阶信息的最优化方法快。
1 引言
随机梯度下降(SGD)和反向传播 [9] 是现今深度网络训练的算法核心。深度学习的成功证明了这种组合的有效性,它已经成功地运用在各种具有大型数据集和极深网络的不同任务中。
然而,尽管 SGD 有很多优点,但这种一阶方法的收敛速度(就迭代次数而言)还有很大的改进区间。尽管单次 SGD 迭代的计算速度非常快并且在优化开始时有迅速的进展,但很快,优化就会进入一个缓慢提升的阶段。这可以归因于迭代进入了目标函数错误缩放的参数空间中。在这种情况下,快速的进展需要在参数空间内不同的方向上采用不同的步长,而 SGD 无法实现这种迭代。
诸如牛顿法及其变体的二阶方法根据目标函数的局部曲率重新调整梯度,从而消除了这个问题。对于 R 中的标量损失,这种调整采用 H−1J 的形式,其中 H 是黑塞矩阵(Hessian matrix;二阶导数)或者是目标空间中局部曲率的一个近似,J 是目标函数的梯度。事实上,它们可以实现局部尺度不变性,并在梯度下降停滞 [24] 的地方取得显著进展。尽管在其它领域它们是无可比拟的,但一些问题阻碍了它们在深度模型中的应用。首先,因为黑塞矩阵的参数数量以二次形式增长,且通常有着数百万的参数,故而对它求逆或存储它是不现实的。其次,由于随机抽样,任何黑塞矩阵的估计都必然产生噪声和病态的条件数,因而经典的求逆方法如共轭梯度对于黑塞矩阵是不稳健的。
在本文中,我们提出了一种新的算法,它可以克服这些困难并使得二阶优化适用于深度学习。我们特别展示了如何去避免存储黑塞矩阵或其逆矩阵的任何估计值。反之,我们将牛顿更新,即 H−1J 的计算看成是求解一个能通过梯度下降法求解的线性系统。通过交叉求解步骤和参数更新步骤,求解这个线性系统的成本会随着时间推移被摊销。此外,与共轭梯度法不同,梯度下降的选择使其对噪声稳健。我们提出的方法增加了很小的开销,因为一个黑塞矩阵向量积可通过两步自动微分的现代网络实现。有趣的是,我们证明了我们的方法等价于带有一个额外项的动量 SGD(也称为重球法),这个额外项能计算曲率。因此,我们将该方法命名为 CURVEBALL。与其他方法不同,我们方法的总内存占用与动量 SGD 一样小。
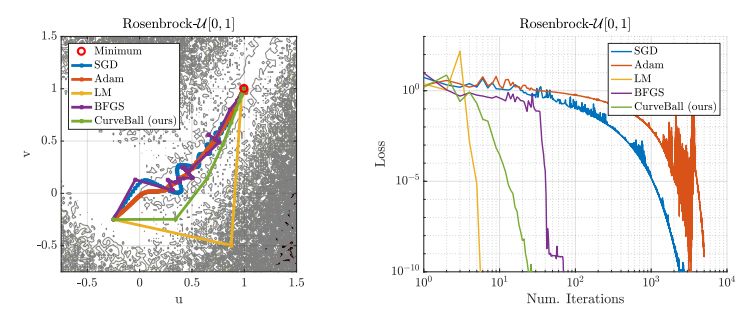
图 1:已知解决方案的问题。左:不同求解器的 Stochastic Rosenbrock 函数轨迹(较深的阴影区域表示较高的函数值)。右:针对轨迹图绘制的损失函数与迭代数之间的关系。
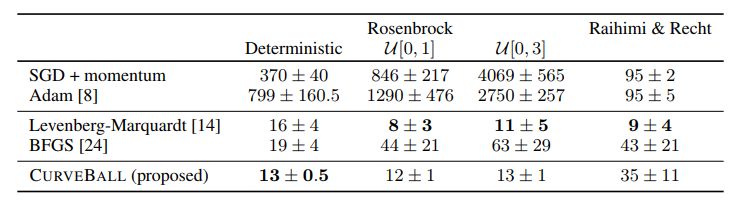
表 1:在小数据集上优化器的比较。对于每一个优化器,我们展示了解决问题所需迭代数的平均值 ± 标准差。对于随机 Rosenbrock 函数,U[λ1, λ2] 表示来自 U[λ1, λ2] 的噪声(详见 4.1)。
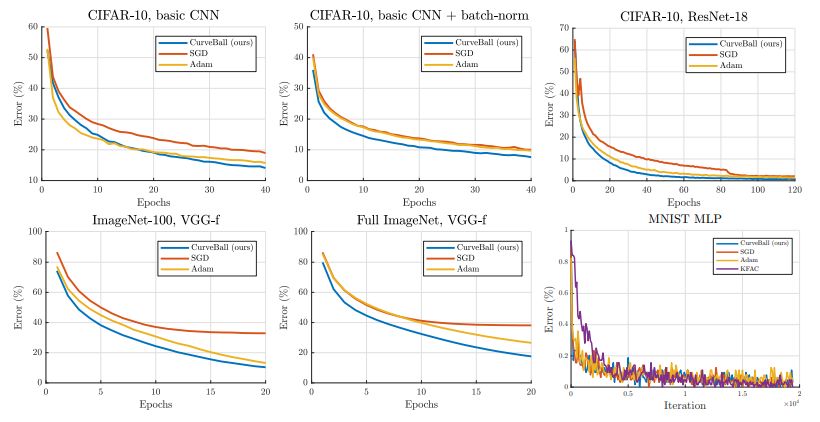
图 2:不同优化器在不同数据集和网络上的性能对比。在一系列实际设置下,包括大型数据集(ImageNet)、是否使用批量归一化和过度参数化的模型(ResNet),我们的方法似乎表现十分良好。
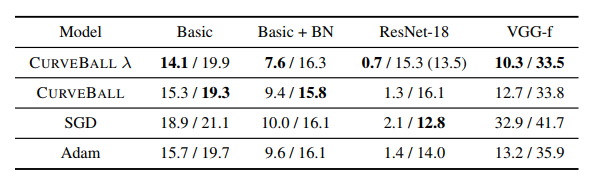
表 2:不同模型和优化方法的最佳百分比误差(训练/验证误差)。CURVEBALL λ 表示使用了重新调整的参数 λ(第 3 节)。括号内的数字表示带有额外 Dropout 正则化(比例 0.3)的验证误差。前 3 列在是在 CIFAR - 10 上训练的,第 4 列是在 ImageNet - 100 上训练的。
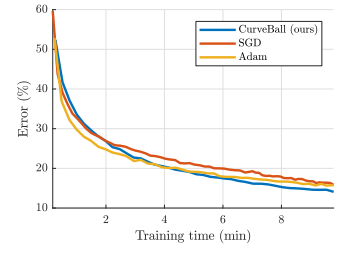
图 3:训练误差 vs. 训练时间(基于 CIFAR - 10 模型)。
论文:Small steps and giant leaps: Minimal Newton solvers for Deep Learning(小改进,大飞跃:深度学习中的最小牛顿求解器)

论文地址:https://arxiv.org/abs/1805.08095
我们提出了一种能直接替换现今深度学习求解器的快速二阶方法。与随机梯度下降法(SGD)比,它只需要在每次迭代时进行 2 次额外的前向自动微分操作,同时它的运算成本与 2 次标准前向传播相当且易于实现。我们的方法解决了现有二阶求解器长期存在的问题,即在每次迭代时需要对黑塞矩阵的近似精确求逆或使用共轭梯度法,而这个过程既昂贵又对噪声敏感。相反,我们提出保留逆黑塞矩阵投影梯度的单个估计,并在每次迭代时更新一次。这个估计值有着相同的维度,并与 SGD 中常用的动量变量相似。黑塞矩阵的估计是变动的。我们首先验证我们的方法—CurveBall 在一些已知闭式解的小问题(带噪声的 Rosenbrock 函数和退化的 2 层线性网络)上的有效性,而这是现今深度学习解释器仍在努力的地方。我们接着在 CIFAR、ImageNet 上训练一些大型模型,包括 ResNet,VGG-f 网络,我们的方法在没有调整超参数的情况下,表现出更快的收敛性。最后,所有的代码已经开源。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


