谷歌大脑提出TCN,能让机器人边看视频边模仿

▷谷歌大脑 Time-Contrastive Networks(TCN)论文解读视频
翻译 | Laura 校对 | 吴璇 整理 | 凡江
在「Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation」这篇论文中,谷歌的研究者提出了一种从观察中学习世界的新方法。雷锋字幕组本期译制视频多角度展示了机器人仅仅通过观看视频,就能在无人监督的情况下,模拟视频动作的全过程。

除了视频演示之外,谷歌大脑并未对机器人系统提供监督学习。他们将这种方法运用于各种不同的任务,以此来训练真实和虚拟机器人。例如,倒水任务,放碟任务,和姿势模仿任务。

第一步
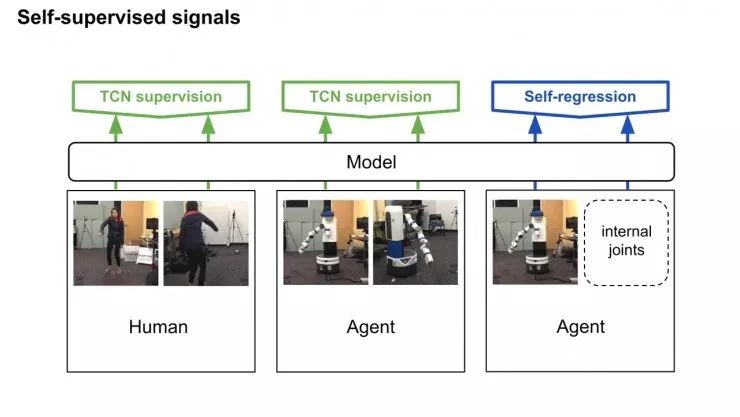
通过视频的分解镜头来学习,将时间作为监督信号,发现视频的不同属性。这组嵌入向量经由一组非结构化和未标记的视频训练,里面含有和任务相关的有效动作,也有一些随机行为,来体现真实世界中的各种可能状态。
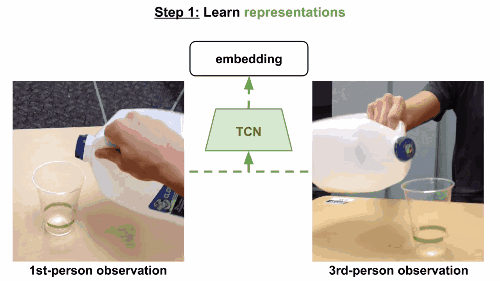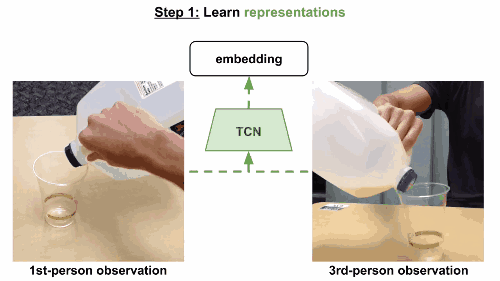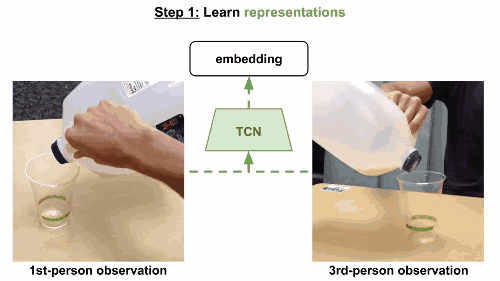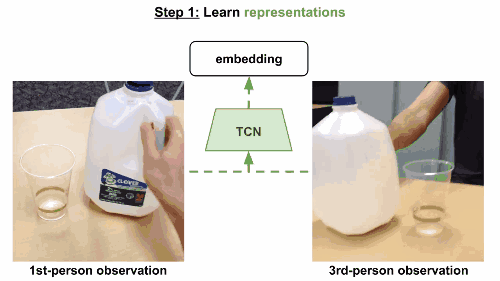
模型使用triplet loss误差函数,基于同一帧的多视角观察数据来训练多视角下同时出现的帧,在嵌入空间中互相关联。当然也可以考虑一个时间对比模型,只根据单一视角来训练。这一次,有效帧在锚点的一定范围内随机选定,根据有效范围计算边际范围。无效范围是在边际范围外随机选定。模型和之前一样进行训练。
第二步
通过强化学习来学习规则。基于TCN嵌入,根据第三方的真人示范来构造奖励函数。机械臂起初尝试一些随机动作,然后学会反复进行这些动作,就可以产生最高奖励的控制步骤,最后达成重现视频任务的效果。
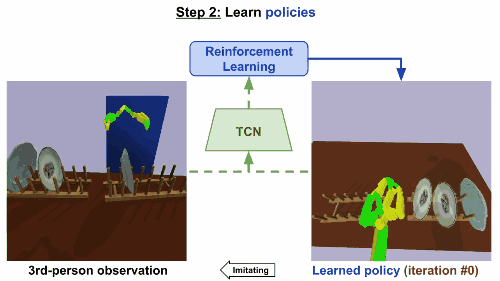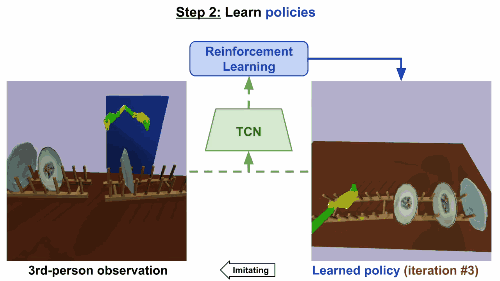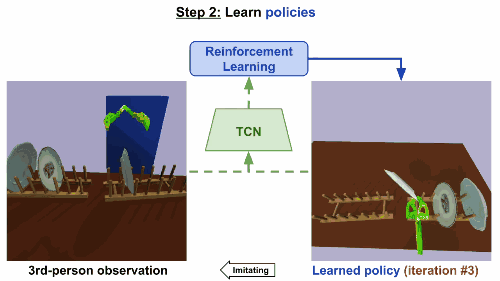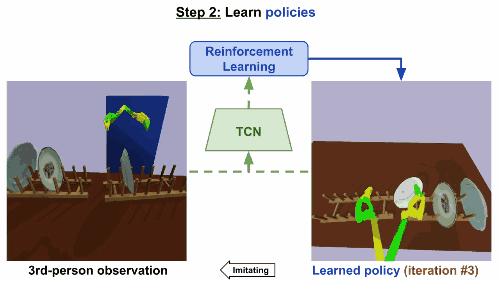
模型在仅仅经历了9次迭代后就成功收敛,大约相当于现实世界15分钟的训练。同样地,在移碟任务中,机器人最初尝试随机运动,然后学会成功拿起和移动一个盘子。
论文原址:
https://sermanet.github.io/tcn/
相关文章:




新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
谷歌大脑让机器尝试画画,虽然结果很勉强但过程你却不能不知道
▼▼▼



