使用 C# 代码实现拓扑排序
(点击上方蓝字,可快速关注我们)
来源:myzony
cnblogs.com/myzony/p/9201768.html
一、介绍
自己之前并没有接触过拓扑排序,顶多听说过拓扑图。在写前一篇文章的时候,看到 Abp 框架在处理模块依赖项的时候使用了拓扑排序,来确保顶级节点始终是最先进行加载的。
第一次看到觉得很神奇,看了一下维基百科头也是略微大,自己的水平也是停留在冒泡排序的层次。
二、原理
先来一个基本定义:
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
每个顶点出现且只出现一次。
若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
例如,有一个集合它的依赖关系如下图:
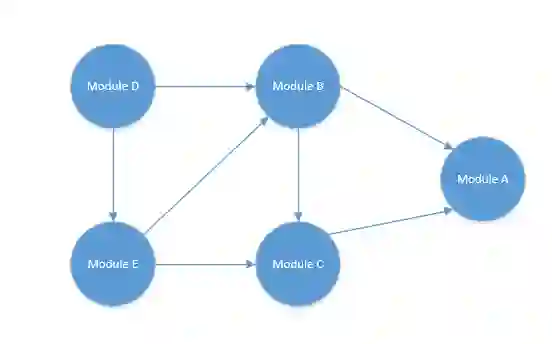
可以看到他有一个依赖关系:
Module D 依赖于 Module E 与 Module B 。
Module E 依赖于 Module B 与 Module C 。
Module B 依赖于 Module A 与 Module C 。
Module C 依赖于 Module A 。
Module A 无依赖 。
这个就是一个 DAG 图,我们要得到它的拓扑排序,一个简单的步骤如下:
从 DAG 图中选择一个没有前驱的顶点并输出。
从 DAG 图中删除该顶点,以及以它为起点的有向边。
重复步骤 1、2 直到当前的 DAG 图为空,或者当前图不存在无前驱的顶点为止。
按照以上步骤,我们来进行一个排序试试。
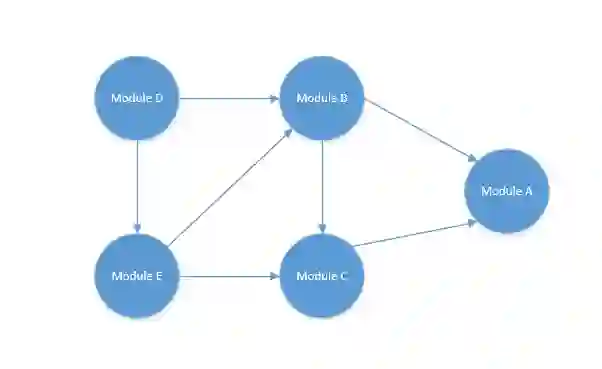
最后的排序结果就是:
Module D -> Module E -> Module B -> Module C -> Module A
emmmm,其实一个有向无环图可以有一个或者多个拓扑序列的,因为有的时候会存在一种情况,即以下这种情况:
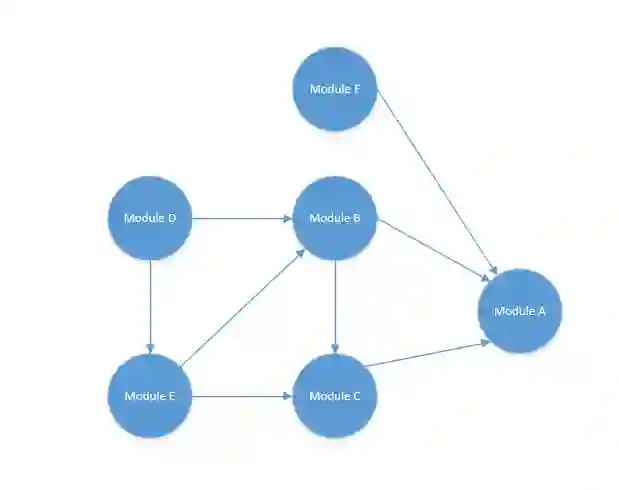
这个时候你就可能会有这两种结果
D->E->B->C->F->A
D->E->B->F->C->A
因为 F 与 C 是平级的,他们初始化顺序即便不同也没有什么影响,因为他们的依赖层级是一致的,不过细心的朋友可能会发现这个顺序好像是反的,我们还需要将其再反转一次。
三、实现
上面这种方法仅适用于已知入度的时候,也就是说这些内容本身就是存在于一个有向无环图之中的,如果按照以上方法进行拓扑排序,你需要维护一个入度为 0 的队列,然后每次迭代移除入度为 0 顶点所指向的顶点入度。
例如有以下图:
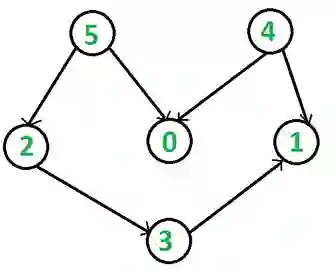
按照我们之前的算法,
首先初始化队列,将 5 与 4 这两个入度为 0 的顶点加入队列当中。
执行 While 循环,条件是队列不为空。
之后首先拿出 4 。
然后针对其指向的顶点 0 与 顶点 1 的入度减去 1。
减去指向顶点入度的时候同时判断,被减去入度的顶点其值是否为 0 。
这里 1 入度被减去 1 ,为 0 ,添加到队列。
0 顶点入度减去 1 ,为 1。
队列现在有 5 与 1 这两个顶点,循环判断队列不为空。
5 指向的顶点 0 入度 减去 1,顶点 0 入度为 0 ,插入队列。
这样反复循环,最终队列全部清空,退出循环,得到拓扑排序的结果4, 5, 2, 0, 3, 1 。
四、深度优先搜索实现
在参考资料 1 的代码当中使用的是深度优先算法,它适用于有向无环图。
有以下有向环图 G2:

对上图 G2 进行深度优先遍历,首先从入度为 0 的顶点 A 开始遍历:
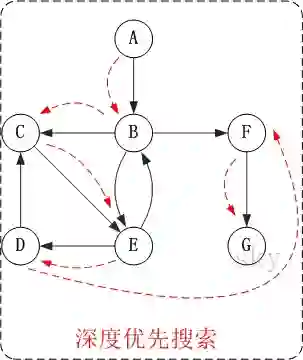
它的步骤如下:
访问 A 。
访问 B 。
访问 C 。
在访问了 B 后应该是访问 B 的另外一个顶点,这里可以是随机的也可以是有序的,具体取决于你存储的序列顺序,这里先访问 C 。
访问 E 。
访问 D 。
这里访问 D 是因为 B 已经被访问过了,所以访问顶点 D 。
访问 F 。
因为顶点 C 已经被访问过,所以应该回溯访问顶点 B 的另一个有向边指向的顶点 F 。
访问 G 。
因此最后的访问顺序就是 A -> B -> C -> E -> D -> F -> G ,注意顺序还是不太对哦。
看起来跟之前的方法差不多,实现当中,其 Sort() 方法内部包含一个 visited 字典,用于标记已经访问过的顶点,sorted 则是已经排序完成的集合列表。
在字典里 Key 是顶点的值,其 value 值用来标识是否已经访问完所有路径,为 true 则表示正在处理该顶点,为 false 则表示已经处理完成。
现在我们来写实现吧:
public static IList<T> Sort<T>(IEnumerable<T> source, Func<T, IEnumerable<T>> getDependencies)
{
var sorted = new List<T>();
var visited = new Dictionary<T, bool>();
foreach (var item in source)
{
Visit(item, getDependencies, sorted, visited);
}
return sorted;
}
public static void Visit<T>(T item, Func<T, IEnumerable<T>> getDependencies, List<T> sorted, Dictionary<T, bool> visited)
{
bool inProcess;
var alreadyVisited = visited.TryGetValue(item, out inProcess);
// 如果已经访问该顶点,则直接返回
if (alreadyVisited)
{
// 如果处理的为当前节点,则说明存在循环引用
if (inProcess)
{
throw new ArgumentException("Cyclic dependency found.");
}
}
else
{
// 正在处理当前顶点
visited[item] = true;
// 获得所有依赖项
var dependencies = getDependencies(item);
// 如果依赖项集合不为空,遍历访问其依赖节点
if (dependencies != null)
{
foreach (var dependency in dependencies)
{
// 递归遍历访问
Visit(dependency, getDependencies, sorted, visited);
}
}
// 处理完成置为 false
visited[item] = false;
sorted.Add(item);
}
}
顶点定义:
// Item 定义
public class Item
{
// 条目名称
public string Name { get; private set; }
// 依赖项
public Item[] Dependencies { get; set; }
public Item(string name, params Item[] dependencies)
{
Name = name;
Dependencies = dependencies;
}
public override string ToString()
{
return Name;
}
}
调用:
static void Main(string[] args)
{
var moduleA = new Item("Module A");
var moduleC = new Item("Module C", moduleA);
var moduleB = new Item("Module B", moduleC);
var moduleE = new Item("Module E", moduleB);
var moduleD = new Item("Module D", moduleE);
var unsorted = new[] { moduleE, moduleA, moduleD, moduleB, moduleC };
var sorted = Sort(unsorted, x => x.Dependencies);
foreach (var item in sorted)
{
Console.WriteLine(item.Name);
}
Console.ReadLine();
}
结果:

看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能





