使用 Canal 实现数据异构
大型系统中,数据库通常会使用分库分表 来解决容量和性能问题,但分库分表后会使不同维度的查询和聚合查询变得很麻烦。
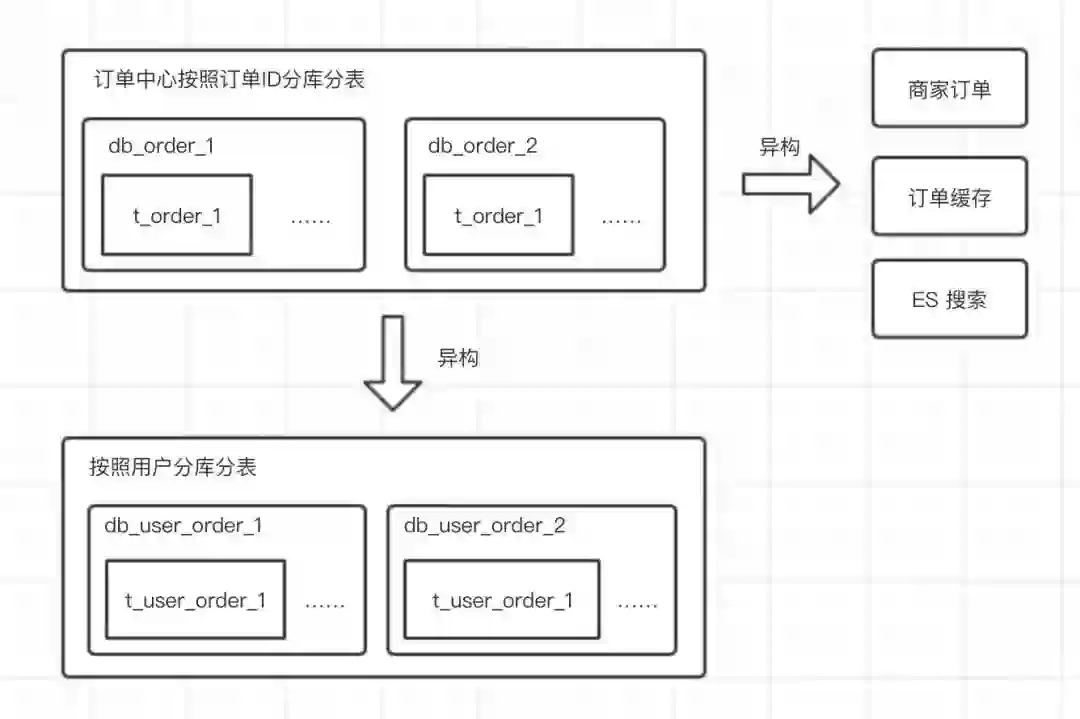
例如订单表,根据订单ID拆分到不同的表中。
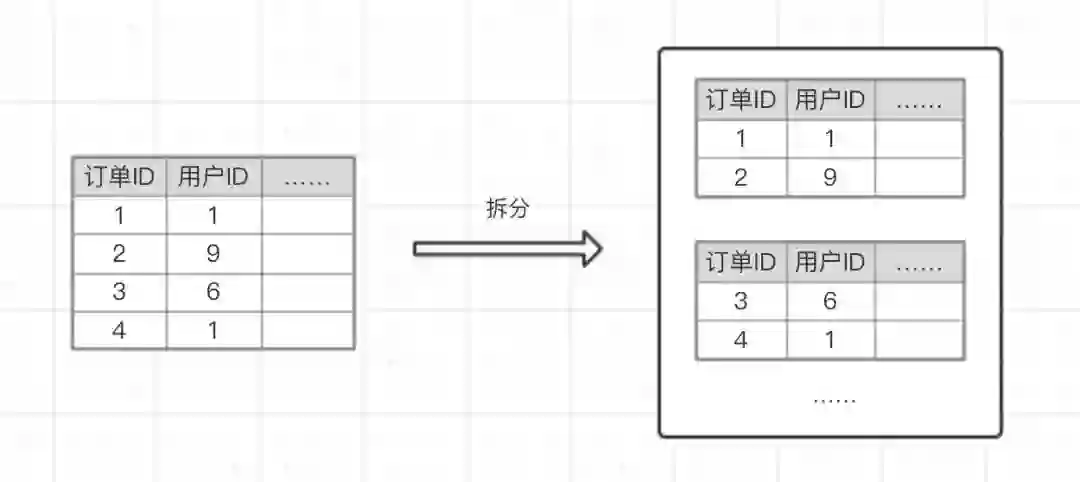
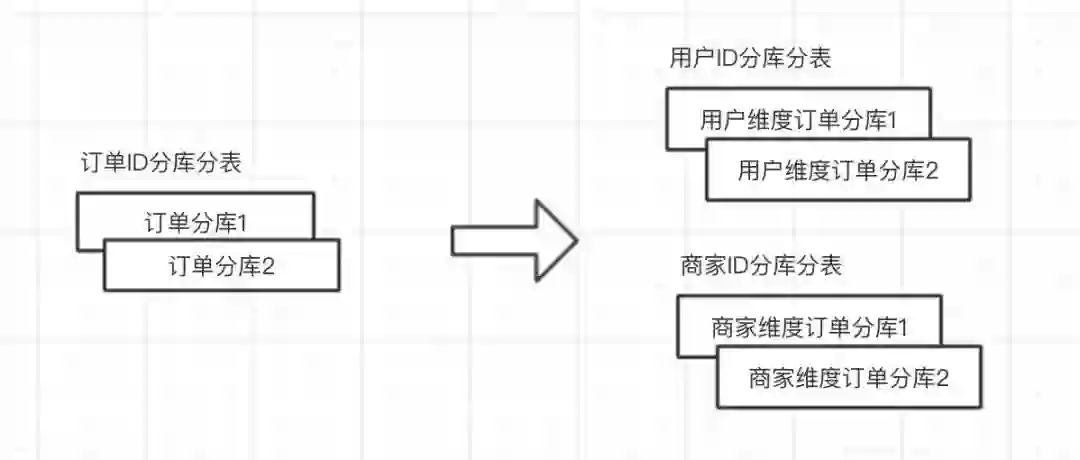
某个用户的订单可能会散落在多个表中,那用户查询自己的订单列表怎么办?这种情况就可以通过数据异构来解决,按照不同查询维度建立表结构,这样就可以按照不同维度进行查询,例如:
或者把数据放入ES:
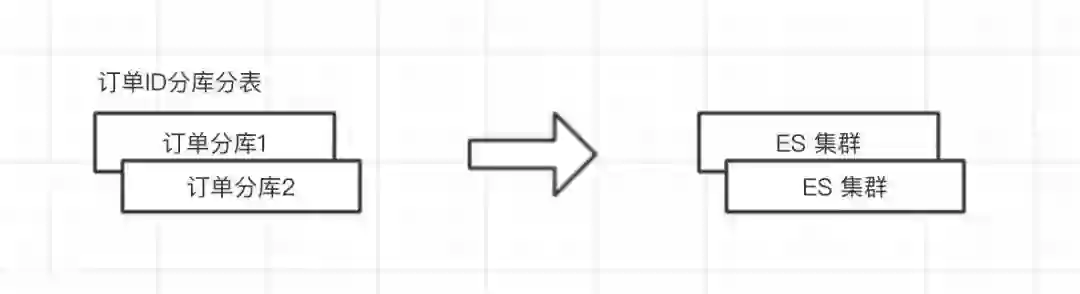
数据异构主要存储数据之间的关系,然后通过查询源库获取实际数据,有时也可以通过数据冗余来提升查询性能。
上面这种方式是查询维度的异构,还有聚合数据异构。
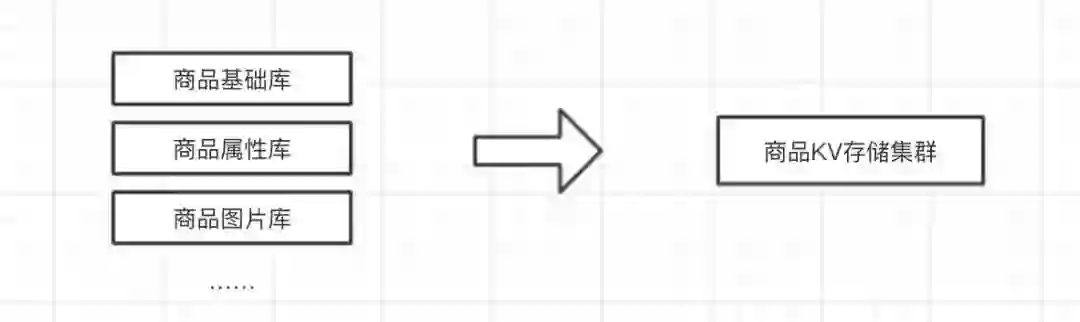
例如商品详情页中包括商品基本信息、商品属性、商品图片,在前端展示时,根据商品ID进行查询,需要查询3个甚至更多的库才能查到所有展示数据,这就是数据聚合的情景。
2. 数据异构的实现方式
有一个常用的实现方式就是 订阅数据库变更日志,比如订阅MySQL的binlog日志模拟数据库的主从同步机制,然后解析变更日志将数据写到订单列表,从而实现数据异构。
2.1 MySQL 主从复制原理
既然是模拟主从同步机制,下面复习下MySQL的主从复制原理。
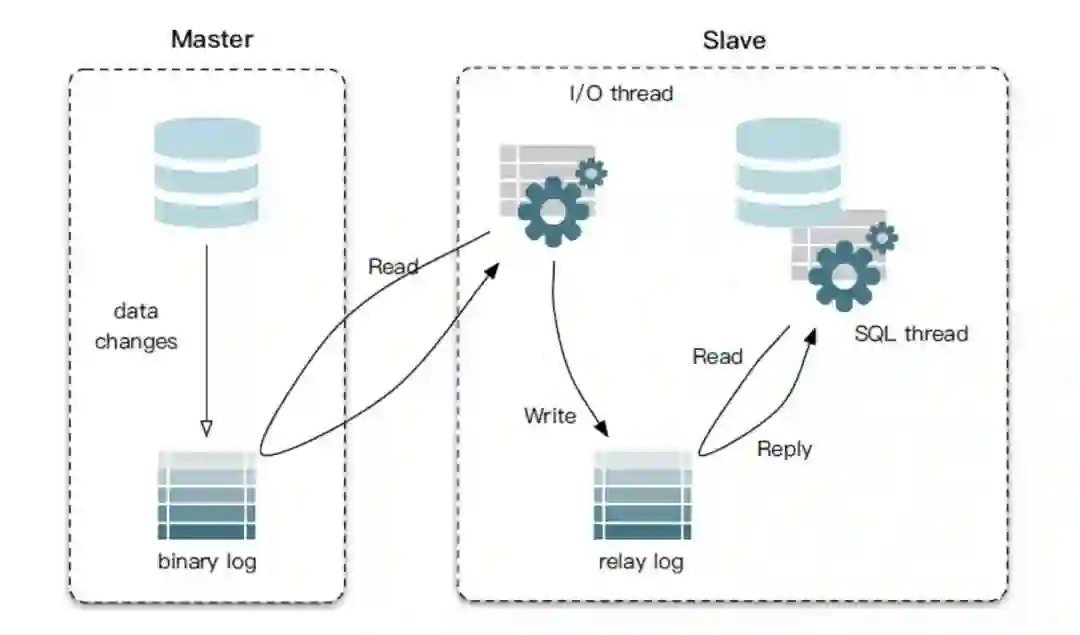
client 将数据写入 master。
master 将变更记录写入二进制日志 binlog。
slave 订阅 master 的 binlog 日志,通过 I/O 线程从 binlog 的指定位置拉取日志进行同步。
slave I/O 线程读取到日志后先写入 relay log 重放日志中。
slave 通过一个 SQL 线程读取 relay log 进行日志重放,实现主从数据库之间的同步。
2.2 Canal 介绍
Canal 是阿里开源的一款基于MySQL binlog 的增量订阅与消费组件,可以把 Canal 看做 slave 数据库,订阅主库的 binlog 日志,然后读取并解析,实现数据的同步/异构。
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave。
通过 Canal 可以订阅数据库的 binlog,然后进行数据消费,例如数据镜像、数据异构、数据索引、缓存更新等,这种机制可以实现数据的有序性和一致性。
Canal 结构图:

首先部署 canal server,可以部署多台,但只有一台是活跃的,其他作为备机,其高可用是通过 zk 维护的。
canal server 通过主从机制订阅数据库的 binlog 日志。
canal client 订阅 canal server,对变更的表数据进行消费处理,根据实际应用场景写入镜像数据库、异构数据库、缓存等。
canal client 也可以有多台,同样只有一台是活跃的,其他为备机,也是通过 zk 来维护其高可用性,zk 还维护了当前消费到的日志位置。
canal server 读取的 binlog 事件只存储在内存中,而且只有一个 canal client 能进行消费。
如果需要多个消费者,可以在 canal client 中把数据写入消息队列,然后使用队列的消费者进行处理,而不是启动多个 canal server 订阅 binlog,因为这样会使数据库的压力较大。
如果数据库本身的压力已经较大,可以让 canal server 订阅现有 slave 的 binlog 日志,形成 master - slave -slave 的结构。
Canal 项目地址:
https://github.com/alibaba/canal
点击👇阅读原文,查看文章列表




