出品 | AI科技大本营(ID:rgznai100)
作为数据科学家,我们已经对 Pandas 或 SQL 等其他关系数据库非常熟悉了。我们习惯于将行中的用户视为列。但现实世界的表现真的如此吗?
在互联世界中,用户不能被视为独立实体。他们之间具有一定的关系,在构建机器学习模型时,有时也希望包含这样的关系。
在关系型数据库中,我们无法在不同的行(用户)之间使用这种关系,但在图形数据库中,这样做是相当简单的。
在这篇文章中将为大家介绍一些重要的图算法,以及Python 的代码实现。
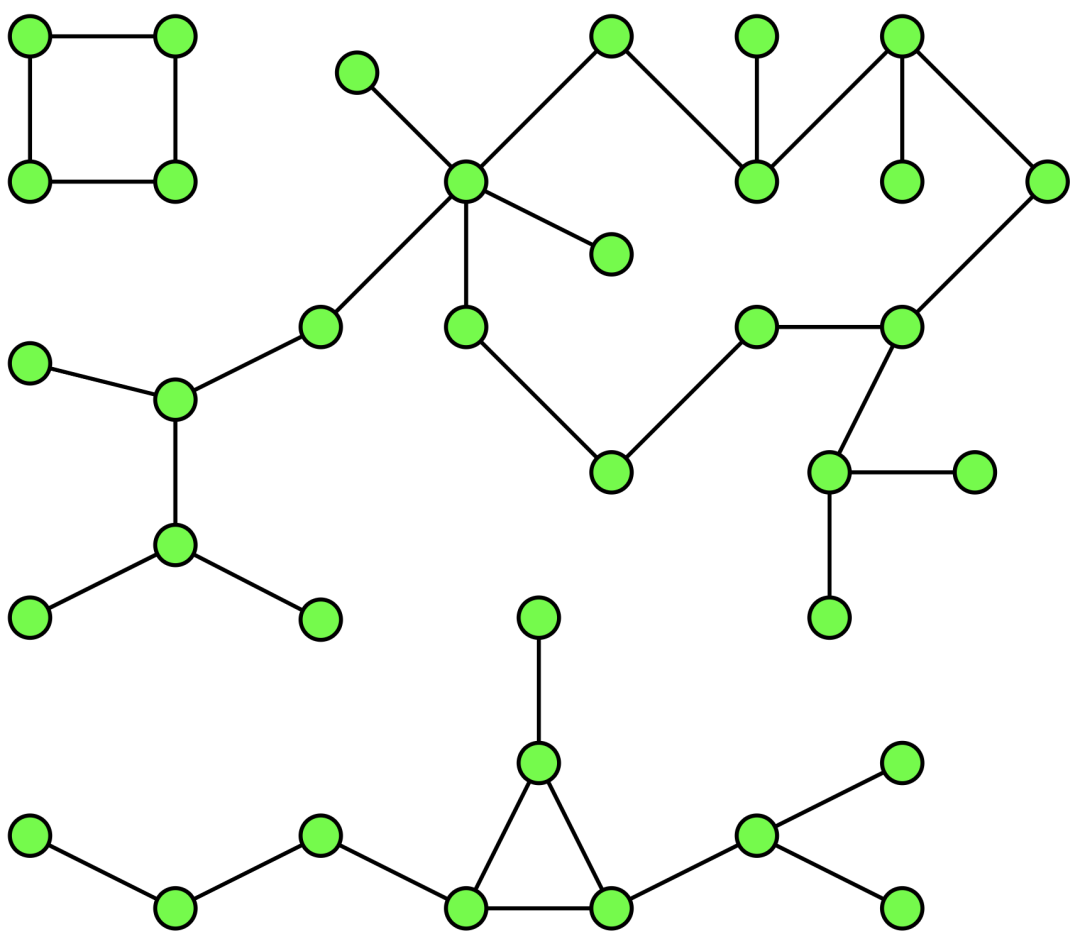
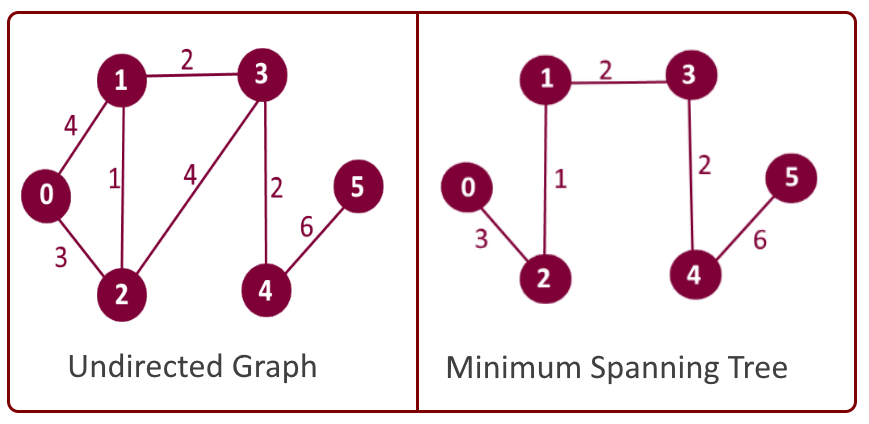
将上图中的连通分量算法近似看作一种硬聚类算法,该算法旨在寻找相关数据的簇类。举一个具体的例子:假设拥有连接世界上任意城市的路网数据,我们需要找出世界上所有的大陆,以及它们所包含的城市。我们该如何实现这一目标呢?
基于BFS / DFS的连通分量算法能够达成这一目的,接下来,我们将用 Networkx 实现这一算法。
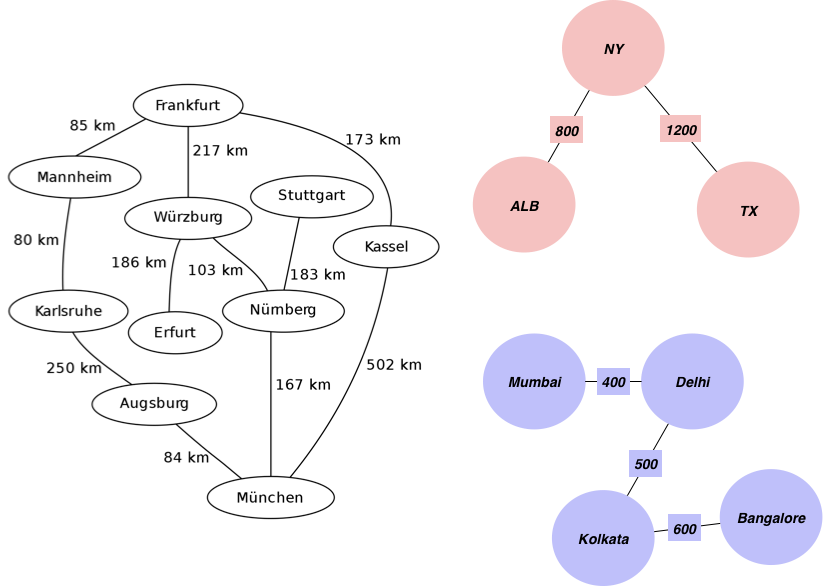
使用 Python 中的 Networkx 模块来创建和分析图数据库。如下面的示意图所示,图中包含了各个城市和它们之间的距离信息。
首先创建边的列表,列表中每个元素包含两个城市的名称,以及它们之间的距离。
edgelist = [['Mannheim', 'Frankfurt', 85], ['Mannheim', 'Karlsruhe', 80], ['Erfurt', 'Wurzburg', 186], ['Munchen', 'Numberg', 167], ['Munchen', 'Augsburg', 84], ['Munchen', 'Kassel', 502], ['Numberg', 'Stuttgart', 183], ['Numberg', 'Wurzburg', 103], ['Numberg', 'Munchen', 167], ['Stuttgart', 'Numberg', 183], ['Augsburg', 'Munchen', 84], ['Augsburg', 'Karlsruhe', 250], ['Kassel', 'Munchen', 502], ['Kassel', 'Frankfurt', 173], ['Frankfurt', 'Mannheim', 85], ['Frankfurt', 'Wurzburg', 217], ['Frankfurt', 'Kassel', 173], ['Wurzburg', 'Numberg', 103], ['Wurzburg', 'Erfurt', 186], ['Wurzburg', 'Frankfurt', 217], ['Karlsruhe', 'Mannheim', 80], ['Karlsruhe', 'Augsburg', 250],["Mumbai", "Delhi",400],["Delhi", "Kolkata",500],["Kolkata", "Bangalore",600],["TX", "NY",1200],["ALB", "NY",800]]
g = nx.Graph()for edge in edgelist: g.add_edge(edge[0],edge[1], weight = edge[2])
现在,我们想从这张图中找出不同的大陆及其包含的城市。我们可以使用使用连通分量算法来执行此操作:
for i, x in enumerate(nx.connected_components(g)): print("cc"+str(i)+":",x)------------------------------------------------------------cc0: {'Frankfurt', 'Kassel', 'Munchen', 'Numberg', 'Erfurt', 'Stuttgart', 'Karlsruhe', 'Wurzburg', 'Mannheim', 'Augsburg'}cc1: {'Kolkata', 'Bangalore', 'Mumbai', 'Delhi'}cc2: {'ALB', 'NY', 'TX'}
从结果中可以看出,只需使用边缘和顶点,我们就能在数据中找到不同的连通分量。 该算法可以在不同的数据上运行,以满足前文提到的两种其他运用。
继续第一节中的例子,我们拥有了德国的城市群及其相互距离的图表。为了计算从法兰克福前往慕尼黑的最短路径,我们需要用到 Dijkstra 算法。Dijkstra 是这样描述他的算法的:
从鹿特丹到格罗宁根的最短途径是什么?或者换句话说:从特定城市到特定城市的最短路径是什么?这便是最短路径算法,而我只用了二十分钟就完成了该算法的设计。 一天早上,我和未婚妻在阿姆斯特丹购物,我们逛累了,便在咖啡馆的露台上喝了一杯咖啡。而我,就想着我能够做到这一点,于是我就设计了这个最短路径算法。正如我所说,这是一个二十分钟的发明。事实上,它发表于1959年,也就是三年后。它之所以如此美妙,其中一个原因在于我没有用铅笔和纸张就设计了它。后来我才知道,没有铅笔和纸的设计的一个优点就是,你几乎被迫避免所有可避免的复杂性。最终,这个算法让我感到非常惊讶,而且也成为了我名声的基石之一。
于2001年接受ACM通讯公司 Philip L. Frana 的采访时的回答
print(nx.shortest_path(g, 'Stuttgart','Frankfurt',weight='weight'))print(nx.shortest_path_length(g, 'Stuttgart','Frankfurt',weight='weight'))--------------------------------------------------------['Stuttgart', 'Numberg', 'Wurzburg', 'Frankfurt']503
for x in nx.all_pairs_dijkstra_path(g,weight='weight'): print(x)--------------------------------------------------------('Mannheim', {'Mannheim': ['Mannheim'], 'Frankfurt': ['Mannheim', 'Frankfurt'], 'Karlsruhe': ['Mannheim', 'Karlsruhe'], 'Augsburg': ['Mannheim', 'Karlsruhe', 'Augsburg'], 'Kassel': ['Mannheim', 'Frankfurt', 'Kassel'], 'Wurzburg': ['Mannheim', 'Frankfurt', 'Wurzburg'], 'Munchen': ['Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen'], 'Erfurt': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})('Frankfurt', {'Frankfurt': ['Frankfurt'], 'Mannheim': ['Frankfurt', 'Mannheim'], 'Kassel': ['Frankfurt', 'Kassel'], 'Wurzburg': ['Frankfurt', 'Wurzburg'], 'Karlsruhe': ['Frankfurt', 'Mannheim', 'Karlsruhe'], 'Augsburg': ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg'], 'Munchen': ['Frankfurt', 'Wurzburg', 'Numberg', 'Munchen'], 'Erfurt': ['Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})....
-
Dijkstra 算法的变体在 Google 地图中广泛使用,用于计算最短的路线。
-
想象身处在沃尔玛商店,我们知道了各个过道之间的距离,我们希望为从过道 A 到过道 D 的客户提供最短路径。
-
如下图所示,当我们知道了领英中用户的一级连接、二级连接时,如何得知幕后的信息呢?Dijkstra 算法可以帮到我们。
![]()
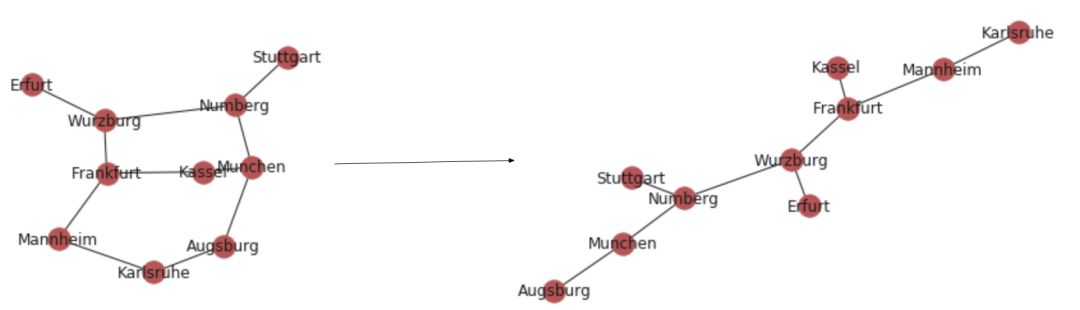
假设我们在水管工程公司或互联网光纤公司工作,我们需要使用最少的电线(或者管道)连接图表中的所有城市。我们如何做到这一点?
# nx.minimum_spanning_tree(g) returns a instance of type graphnx.draw_networkx(nx.minimum_spanning_tree(g))
-
最小生成树在网络设计中有着最直接的应用,包括计算机网络,电信网络,运输网络,供水网络和电网。(最小生成树最初就是为此发明的)
-
-
聚类——首先构造最小生成树,然后使用类间距离和类内距离来设定阈值,从而破坏最小生成树中的某些连边,最终完成聚类的目的
-
图像分割——首先在图形上构建最小生成树,其中像素是节点,像素之间的距离基于某种相似性度量(例如颜色,强度等),然后进行图的分割。
4、网页排序(Pagerank)
![]()
Pagerank 是为谷歌提供长期支持的页面排序算法。根据输入和输出链接的数量和质量,该算法对每个页面进行打分。
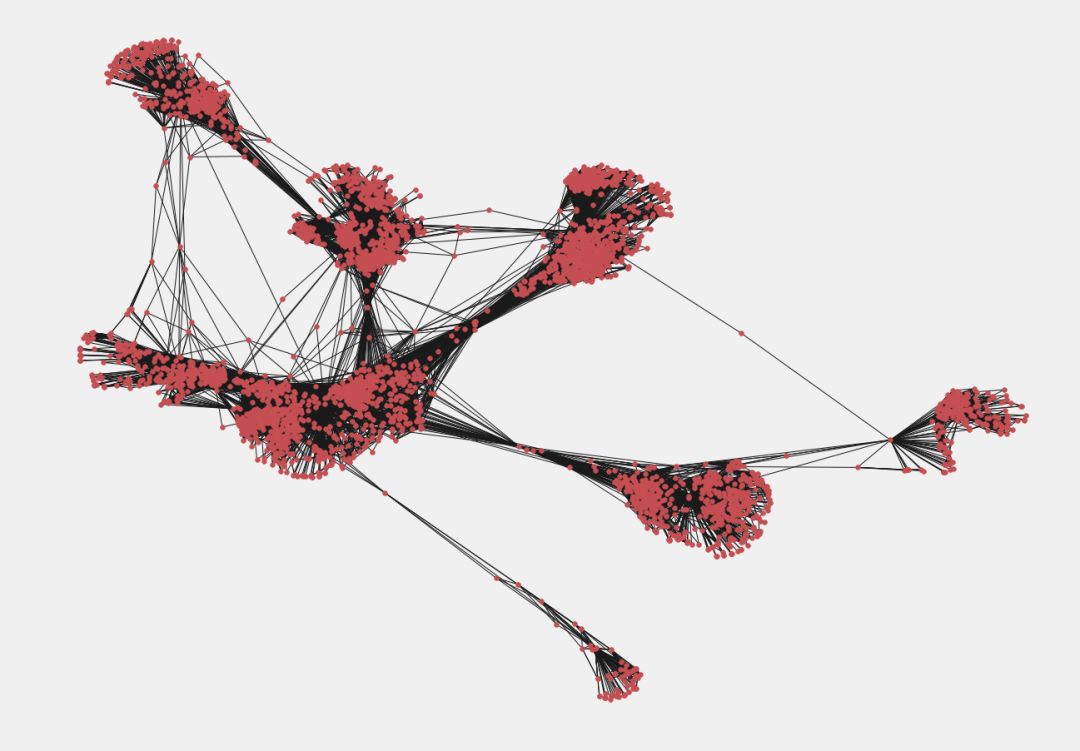
在本节中,我们将使用 Facebook 数据。首先,利用 Facebook 用户之间的连接,我们使用以下方法创建图:
# reading the datasetfb = nx.read_edgelist('../input/facebook-combined.txt', create_using = nx.Graph(), nodetype = int)
pos = nx.spring_layout(fb)import warningswarnings.filterwarnings('ignore')plt.style.use('fivethirtyeight')plt.rcParams['figure.figsize'] = (20, 15)plt.axis('off')nx.draw_networkx(fb, pos, with_labels = False, node_size = 35)plt.show()
![]()
现在,我们想要找到具有高影响力的用户。直观上来讲,Pagerank 会给拥有很多朋友的用户提供更高的分数,而这些用户的朋友反过来会拥有很多朋友。
pageranks = nx.pagerank(fb)print(pageranks)------------------------------------------------------{0: 0.006289602618466542, 1: 0.00023590202311540972, 2: 0.00020310565091694562, 3: 0.00022552359869430617, 4: 0.00023849264701222462,........}
使用如下代码,我们可以获取排序后 PageRank 值,或者最具有影响力的用户:
import operatorsorted_pagerank = sorted(pagerank.items(), key=operator.itemgetter(1),reverse = True)print(sorted_pagerank)------------------------------------------------------[(3437, 0.007614586844749603), (107, 0.006936420955866114), (1684, 0.0063671621383068295), (0, 0.006289602618466542), (1912, 0.0038769716008844974), (348, 0.0023480969727805783), (686, 0.0022193592598000193), (3980, 0.002170323579009993), (414, 0.0018002990470702262), (698, 0.0013171153138368807), (483, 0.0012974283300616082), (3830, 0.0011844348977671688), (376, 0.0009014073664792464), (2047, 0.000841029154597401), (56, 0.0008039024292749443), (25, 0.000800412660519768), (828, 0.0007886905420662135), (322, 0.0007867992190291396),......]
first_degree_connected_nodes = list(fb.neighbors(3437))second_degree_connected_nodes = []for x in first_degree_connected_nodes: second_degree_connected_nodes+=list(fb.neighbors(x))second_degree_connected_nodes.remove(3437)second_degree_connected_nodes = list(set(second_degree_connected_nodes))subgraph_3437 = nx.subgraph(fb,first_degree_connected_nodes+second_degree_connected_nodes)pos = nx.spring_layout(subgraph_3437)node_color = ['yellow' if v == 3437 else 'red' for v in subgraph_3437]node_size = [1000 if v == 3437 else 35 for v in subgraph_3437]plt.style.use('fivethirtyeight')plt.rcParams['figure.figsize'] = (20, 15)plt.axis('off')nx.draw_networkx(subgraph_3437, pos, with_labels = False, node_color=node_color,node_size=node_size )plt.show()
![]()
Pagerank 可以估算任何网络中节点的重要性。
-
-
-
它可以对推文进行排名,其中,用户和推文作为网络的节点。如果用户 A 跟随用户 B,则在用户之间创建连边;如果用户推文或者转发推文,则在用户和推文之间建立连边。
-
一些中心性度量的指标可以作为机器学习模型的特征,我们主要介绍其中的两个指标,其余的指标可以参考这个链接。
https://networkx.github.io/documentation/networkx-1.10/reference/algorithms.centrality.html#current-flow-closeness
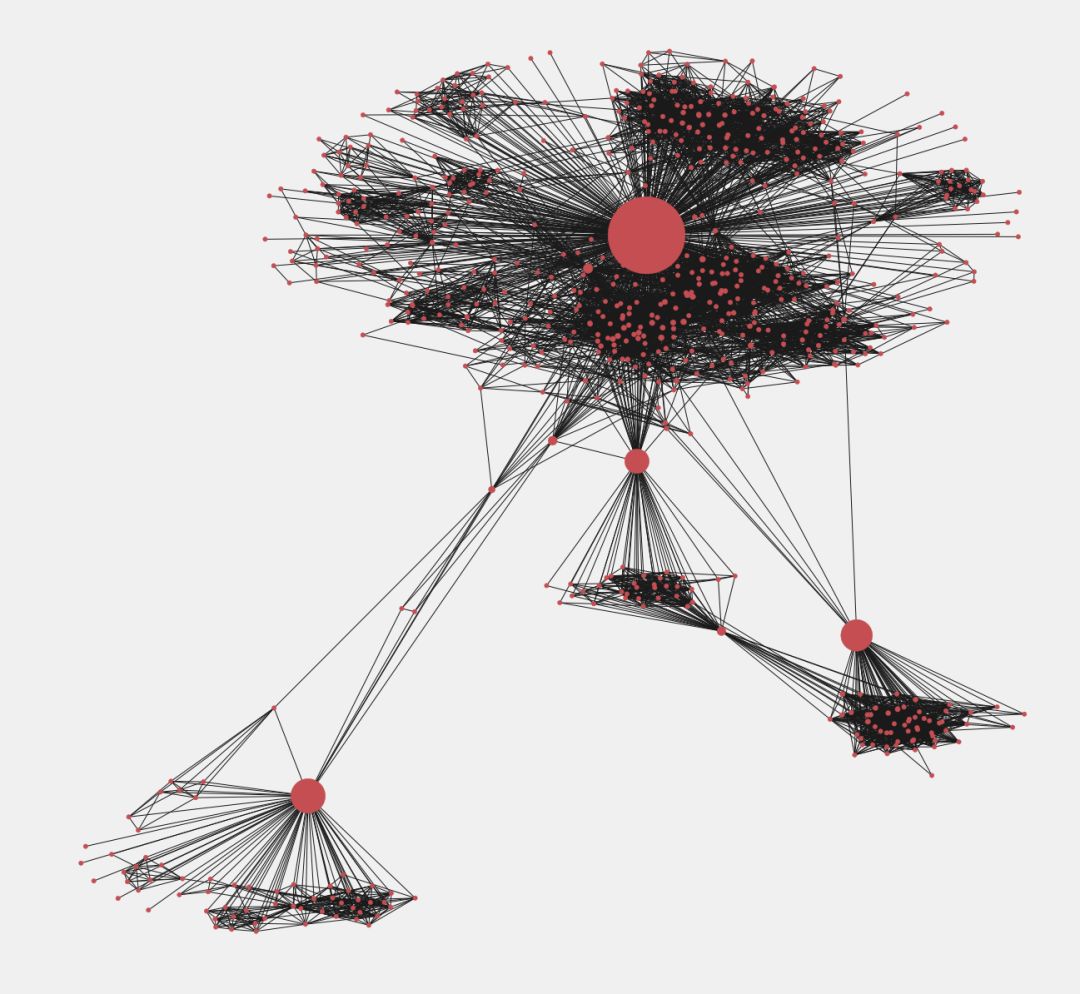
pos = nx.spring_layout(subgraph_3437)betweennessCentrality = nx.betweenness_centrality(subgraph_3437,normalized=True, endpoints=True)node_size = [v * 10000 for v in betweennessCentrality.values()]plt.figure(figsize=(20,20))nx.draw_networkx(subgraph_3437, pos=pos, with_labels=False, node_size=node_size )plt.axis('off')
![]()
如上图所示,节点的尺寸大小和介数中心性的大小成正比。具有较高介数中心性的节点被认为是信息的传递者,移除任意高介数中心性的节点将会撕裂网络,将完整的图打碎成几个互不连通的子图。
在这篇文章中,我们介绍了了一些最有影响力的图算法。随着社交数据的出现,图网络分析可以帮助我们改进模型和创造价值,甚至更多地了解这个世界。最后,贴上本文代码地址。
https://www.kaggle.com/mlwhiz/top-graph-algorithms
https://towardsdatascience.com/data-scientists-the-five-graph-algorithms-that-you-should-know-30f454fa5513