|[IEEE TIP 2020]EraseNet:端到端的真实场景文本擦除方法
本文简要介绍了最近被IEEE TIP 2020 录用的论文 “EraseNet:End-to-end Text Removal in the Wild”的相关工作。该论文主要针对场景文字擦除的问题,首先从已有的场景文字检测与识别的公开数据集收集图片,通过人工标注构建了文字擦除的数据库SCUT-EnsText,并提出了EraseNet文字擦除模型,可以在整图级别不需要文本位置信息的先验下对场景中的文字进行擦除,最后也在该数据集以及之前在[1]提出的合成数据集上与之前方法进行了实验对比,验证了我们方法的有效性,建立了场景文字擦除问题的基准(Benchmark),以便于后续研究工作的开展。
场景文字擦除在近几年得到了越来越多的关注,这项技术在隐私保护、视觉信息翻译和图片内容编辑等方面都有着很重要的作用。文字擦除不仅仅是给自然场景中的文字打上马赛克这样简单,而是要考虑在擦掉文字的同时保持文本区域背景的原特征,这就为这个任务带来了挑战。目前围绕这一课题学者们也提出了诸如SceneTextEraser[2],EnsNet[1],MTRNet[3]等文字擦除模型,但这些模型基本都是基于合成数据SynthText[4]以及少量真实数据进行训练,当这些算法应用到真实场景中可能不具备泛化能力。因此,为了促进文字擦除技术的发展,亟待建立一个场景文字擦除的数据库,提供可靠的数据和分析用以评价不同擦除模型的性能。今天介绍的文章提出了新的真实场景下的文字擦除数据集SCUT-EnsText,并提出了EraseNet模型,该方法在文字擦除任务中取得了不错的性能。


图1展示了SCUT-EnsText的一些样本。这批数据主要采集自如ICDAR 2013,ICDAR 2015,SCUT CTW1500等公开数据集,数据来源如表格1所示。该数据集总共包含3562张场景图片,有着2w余个文本实例。这些文本涵盖中英文以及数字等不同字形,也将水平文本、任意四边形文本和曲线文本等考虑在内;同时考虑到背景复杂度对文字擦除的影响,也刻意挑选了不同背景、不同亮度的文本背景图片。这些特性增加了数据集的挑战性和对不同数据类型的适应性和泛化性。SCUT-EnsText训练集包含2749张图片,测试集813张图片,它为场景文字擦除任务建立了新的基准。
这篇文章同时提出了一个端到端场景文字擦除模型,通过引入两阶段的编解码器(Coarse-to-refinement)以及一个额外的文本感知分支构建了文字擦除生成对抗网络EraseNet,模型的流程图如图2所示。
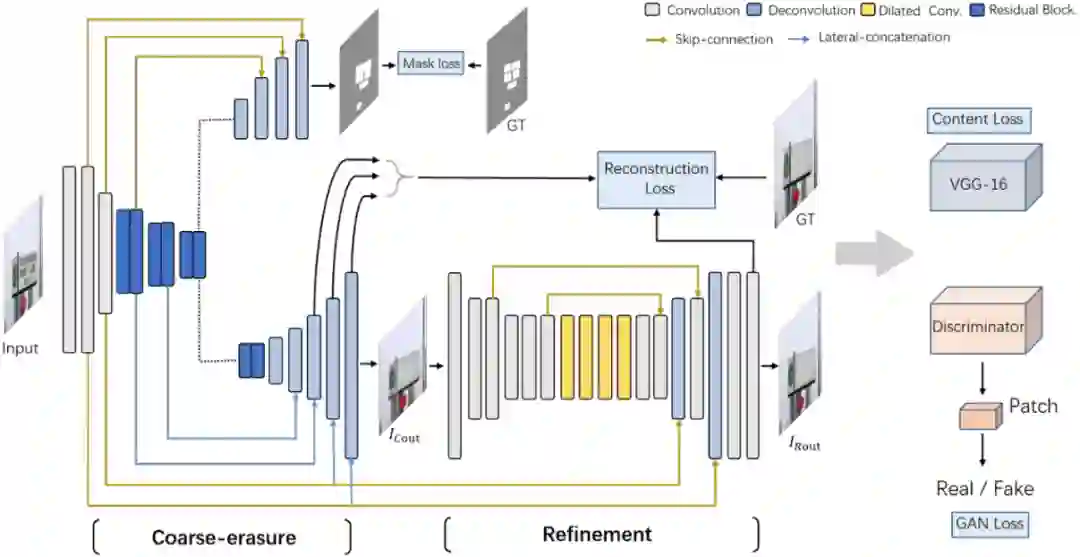
生成器 EnsNet的输出很多时候存在擦除不彻底的问题,比如文本只擦了一部分或者会留有明显的文本轮廓,于是EraseNet在EnsNet生成器的基础上额外加了一个编解码网络作为对第一阶段输出结果的进一步微调(Refinement),训练的时候会对两个阶段的输出都进行有效的监督以确保生成图片的质量。此外,考虑到整图级别的端到端文字擦除会存在文本遗漏的问题,一个简单直接的想法便是额外加入一个文本感知分支,将网络作为一个多任务学习的模型,在进行擦除的同时能比较准确的定位文字区域的位置,对于这个分支,考虑到样本不均衡的问题我们使用Dice Loss去优化,Dice Loss的定义如下:
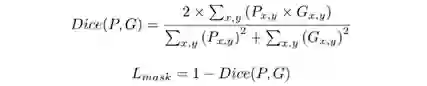
判别器为了保证生成器输出结果的质量(文字擦除区域的质量以及该区域与非文本背景区域的连续性等), 本文使用了局部-全局(local-global)FCN作为判别器。它最终将全局和局部的特征Patch拼接在一起进行真或假的判定。
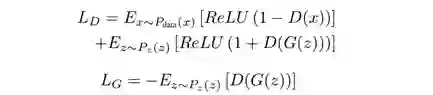
除了上述介绍的Dice Loss和Ganloss,本文还引入了Local-aware Reconstruction Loss, Content Loss(包含Style Loss [6]和Perceptual Loss [7])。
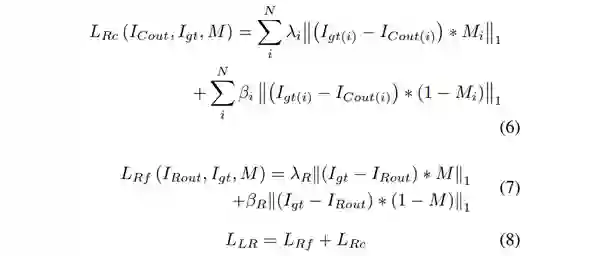
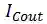 和
和
 分别代表Coarse阶段输出和最终微调后的输出。
分别代表Coarse阶段输出和最终微调后的输出。
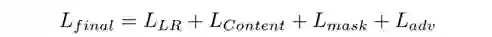
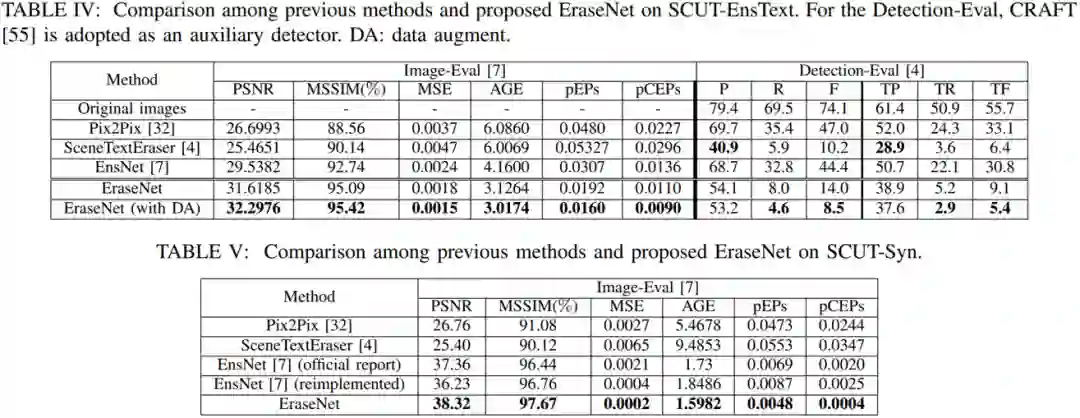
实验主要在SCUT-EnsText和EnsNet[1]提出的8800张(8000用于训练,800测试)合成数据集上进行。
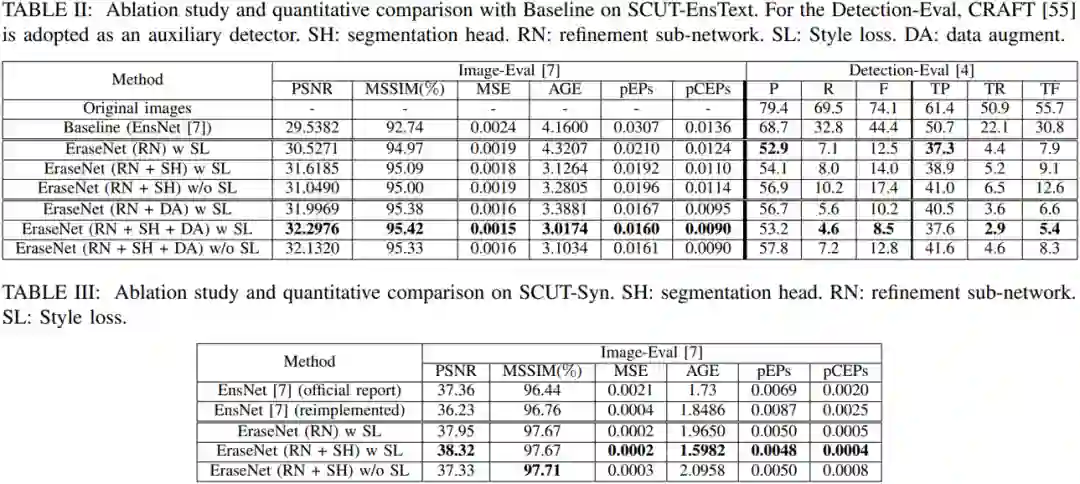

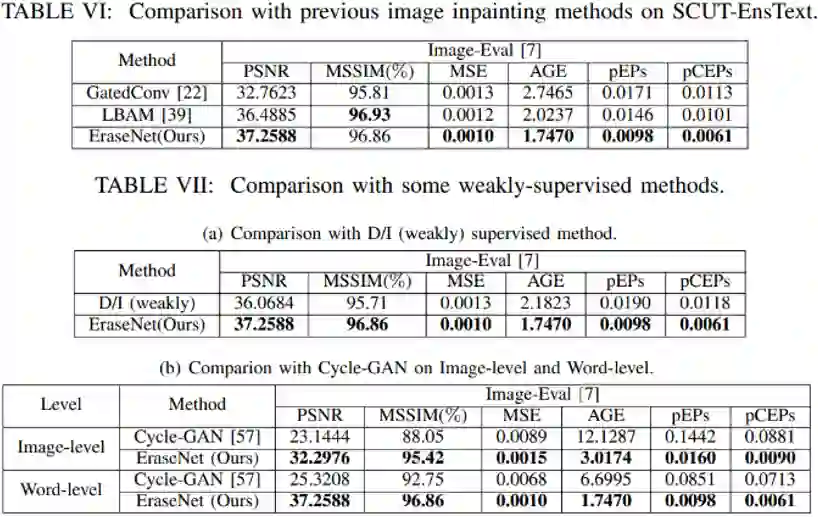
量化结果对比和可视化结果图都验证了EraseNet各模块的有效性以及Content Loss在文字擦除任务中的积极作用。


-
本文提出了一个真实场景下用于场景文字擦除的数据集,能够用于文字擦除以及后续进行文本编辑等方面的研究。 -
本文构建了一个端到端场景文字擦除的网络EraseNet,它可以在整图级别不需要文本位置信息的先验下对场景中的文字进行擦除,并能取得较好的性能。
-
EraseNet论文链接:https://ieeexplore.ieee.org/document/9180003 -
EraseNet代码:https://github.com/lcy0604/EraseNet -
SCUT-EnsText数据集链接:https://github.com/HCIILAB/SCUT-EnsText
[1] S. Zhang, Y. Liu, L. Jin, Y. Huang, andS. Lai, “Ensnet: Ensconce text in the wild,” in Proceedings of AAAI, vol. 33,2019, pp. 801–808.
[2] T. Nakamura, A. Zhu, K. Yanai, and S.Uchida, “Scene text eraser,” in Proceedings of ICDAR, vol. 01, 2017, pp.832–837.
[3] O. Tursun, R. Zeng, S. Denman, S.Sivapalan, S. Sridharan, and C. Fookes, “Mtrnet: A generic scene text eraser,”in Proceedings of ICDAR, 2019, pp. 39–44.
[4] A. Gupta, A. Vedaldi and A. Zisserman,"Synthetic Data for Text Localisation in Natural Images," 2016IEEE Conference on Computer Vision and Pattern Recognition (CVPR), LasVegas, NV, 2016, pp. 2315-2324.
[5] T. Miyato, T. Kataoka, M. Koyama, andY. Yoshida, “Spectral normalization for generative adversarial networks,” in Proceedings of ICLR, 2018.
[6] L. A. Gatys, A. S. Ecker, and M.Bethge, “Image style transfer using convolutional neural networks,” in Proceedings of CVPR, 2016, pp. 2414–2423.
[7] J. Johnson, A. Alahi, and L. Fei-Fei,“Perceptual losses for real-time style transfer and super-resolution,” in Proceedings of ECCV, 2016, pp. 694–711.
原文作者: Chongyu Liu, Yuliang Liu, Lianwen Jin, Shuaitao Zhang, Canjie Luo,Yongpan Wang







