深度 | 用于图像分割的卷积神经网络:从R-CNN到Mark R-CNN
选自Athelas
作者:Dhruv Parthasarathy
机器之心编译
参与:王宇欣、hustcxy、黄小天
卷积神经网络(CNN)的作用远不止分类那么简单!在本文中,我们将看到卷积神经网络(CNN)如何在图像实例分割任务中提升其结果。
自从 Alex Krizhevsky、Geoff Hinton 和 Ilya Sutskever 在 2012 年赢得了 ImageNet 的冠军,卷积神经网络就成为了分割图像的黄金准则。事实上,从那时起,卷积神经网络不断获得完善,并已在 ImageNet 挑战上超越人类。
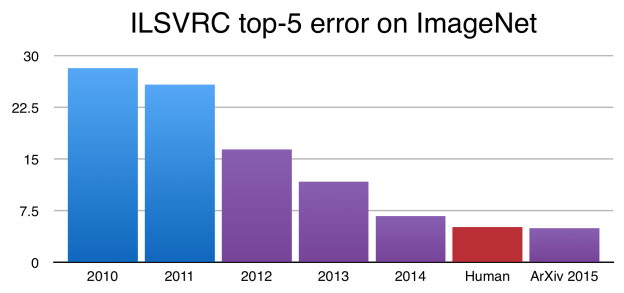
现在,卷积神经网络在 ImageNet 的表现已超越人类。图中 y 轴代表 ImageNet 错误率。
虽然这些结果令人印象深刻,但与真实的人类视觉理解的多样性和复杂性相比,图像分类还是简单得多。

分类挑战赛使用的图像实例。注意图像的构图以及对象的唯一性。
在分类中,图像的焦点通常是一个单一目标,任务即是对图像进行简单描述(见上文)。但是当我们在观察周遭世界时,我们处理的任务相对复杂的多。

现实中的情景通常由许多不同的互相重叠的目标、背景以及行为构成。
我们看到的情景包含多个互相重叠的目标以及不同的背景,并且我们不仅要分类这些不同的目标还要识别其边界、差异以及彼此的关系!

在图像分割中,我们的目的是对图像中的不同目标进行分类,并确定其边界。来源:Mask R-CNN
卷积神经网络可以帮我们处理如此复杂的任务吗?也就是说,给定一个更为复杂的图像,我们是否可以使用卷积神经网络识别图像中不同的物体及其边界?事实上,正如 Ross Girshick 和其同事在过去几年所做的那样,答案毫无疑问是肯定的。
本文的目标
在本文中,我们将介绍目标检测和分割的某些主流技术背后的直观知识,并了解其演变历程。具体来说,我们将介绍 R-CNN(区域 CNN),卷积神经网络在这个问题上的最初的应用,及变体 Fast R-CNN 和 Faster R-CNN。最后,我们将介绍 Facebook Research 最近发布的一篇文章 Mask R-CNN,它扩展了这种对象检测技术从而可以实现像素级分割。上述四篇论文的链接如下:
1. R-CNN: https://arxiv.org/abs/1311.2524
2. Fast R-CNN: https://arxiv.org/abs/1504.08083
3. Faster R-CNN: https://arxiv.org/abs/1506.01497
4. Mask R-CNN: https://arxiv.org/abs/1703.06870
2014 年:R-CNN - 首次将 CNN 用于目标检测

目标检测算法,比如 R-CNN,可分析图像并识别主要对象的位置和类别。
受到多伦多大学 Hinton 实验室的研究的启发,加州伯克利大学一个由 Jitendra Malik 领导的小组,问了他们自己一个在今天看来似乎是不可避免的问题:
Krizhevsky et. al 的研究成果可在何种程度上被推广至目标检测?
目标检测是一种找到图像中的不同目标并进行分类的任务(如上图所示)。通过在 PASCAL VOC Challenge 测试(一个知名的对象检测挑战赛,类似于 ImageNet),由 Ross Girshick(将在下文细讲)、Jeff Donahue 和 Trevor Darrel 组成的团队发现这个问题确实可通过 Krizhevsky 的研究结果获得解决。他们写道:
Krizhevsky et. al 第一次提出:相比基于更简单、HOG 般的特征的系统,卷及神经网络可显著提升 PASCAL VOC 上的目标检测性能。
现在让我们花点时间来了解他们的架构 R-CNN 的运作的方式。
理解 R-CNN
R-CNN 的目的为接收图像,并正确识别图像中主要目标(通过边界框)的位置。
输入:图像
输出:边界框+图像中每个目标的标注
但是我们如何找出这些边界框的位置?R-CNN 做了我们也可以直观做到的——在图像中假设了一系列边界,看它们是否可以真的对应一个目标。

通过多个尺度的窗口选择性搜索,并搜寻共享纹理、颜色或强度的相邻像素。图片来源:https://www.koen.me/research/pub/uijlings-ijcv2013-draft.pdf
R-CNN 创造了这些边界框,或者区域提案(region proposal)关于这个被称为选择性搜索(Selective Search)的方法,可在这里(链接:http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf)阅读更多信息。在高级别中,选择性搜索(如上图所示)通过不同尺寸的窗口查看图像,并且对于不同尺寸,其尝试通过纹理、颜色或强度将相邻像素归类,以识别物体。
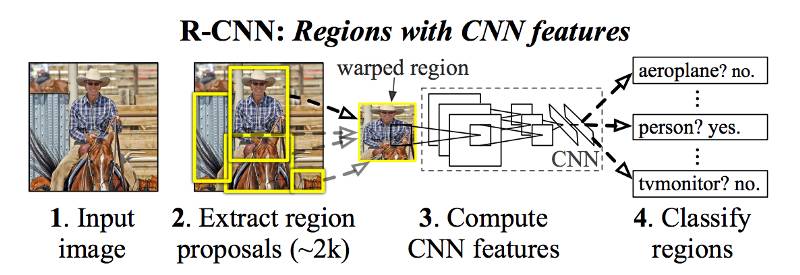
在创建一组区域提案(region proposal)后,R-CNN 只需将图像传递给修改版的 AlexNet 以确定其是否为有效区域。
一旦创建了这些提案,R-CNN 简单地将该区域卷曲到一个标准的平方尺寸,并将其传递给修改版的 AlexNet(ImageNet 2012 的冠军版本,其启发了 R-CNN),如上所示。
在 CNN 的最后一层,R-CNN 添加了一个支持向量机(SVM),它可以简单地界定物体是否为目标,以及是什么目标。这是上图中的第 4 步。
提升边界框
现在,在边界框里找到了目标,我们可以收紧边框以适应目标的真实尺寸吗?我们的确可以这样做,这也是 R-CNN 的最后一步。R-CNN 在区域提案上运行简单的线性回归,以生成更紧密的边界框坐标从而获得最终结果。下面是这一回归模型的输入和输出:
输入:对应于目标的图像子区域
输出:子区域中目标的新边界框坐标
所以,概括一下,R-CNN 只是以下几个简单的步骤
1. 为边界框生成一组提案。
2. 通过预训练的 AlexNet 运行边界框中的图像,最后通过 SVM 来查看框中图像的目标是什么。
3. 通过线性回归模型运行边框,一旦目标完成分类,输出边框的更紧密的坐标。
2015: Fast R-CNN - 加速和简化 R-CNN

Ross Girshick 编写了 R-CNN 和 Fast R-CNN,并持续推动着 Facebook Research 在计算机视觉方面的进展。
R-CNN 性能很棒,但是因为下述原因运行很慢:
1. 它需要 CNN(AlexNet)针对每个单图像的每个区域提案进行前向传递(每个图像大约 2000 次向前传递)。
2. 它必须分别训练三个不同的模型 - CNN 生成图像特征,预测类别的分类器和收紧边界框的回归模型。这使得传递(pipeline)难以训练。
2015 年,R-CNN 的第一作者 Ross Girshick 解决了这两个问题,并创造了第二个算法——Fast R-CNN。下面是其主要思想。
Fast R-CNN 见解 1:ROI(兴趣区域)池化
对于 CNN 的前向传递,Girshick 意识到,对于每个图像,很多提出的图像区域总是相互重叠,使得我们一遍又一遍地重复进行 CNN 计算(大约 2000 次!)。他的想法很简单:为什么不让每个图像只运行一次 CNN,然后找到一种在 2000 个提案中共享计算的方法?
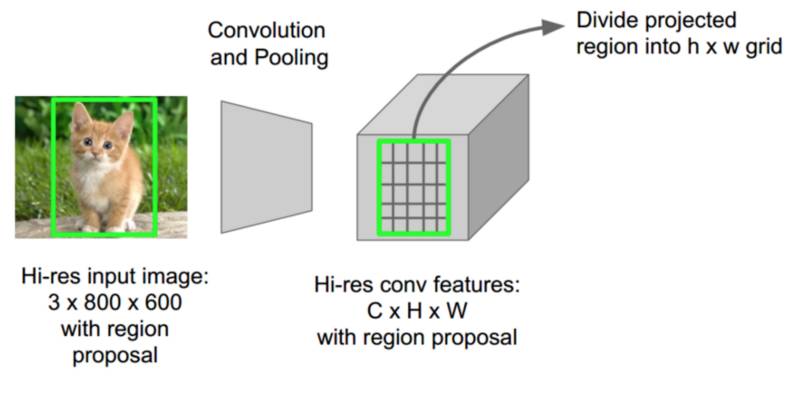
在 ROIPool 中,创建了图像的完整前向传递,并从获得的前向传递中提取每个兴趣区域的转换特征。来源:CS231N 幻灯片,Fei Fei Li、Andrei Karpathy、和 Justin Johnson 斯坦福大学
这正是 Fast R-CNN 使用被称为 RoIPool(兴趣区域池化)的技术所完成的事情。其要点在于,RoIPool 分享了 CNN 在图像子区域的前向传递。在上图中,请注意如何通过从 CNN 的特征映射选择相应的区域来获取每个区域的 CNN 特征。然后,每个区域的特征简单地池化(通常使用最大池化(Max Pooling))。所以我们所需要的是原始图像的一次传递,而非大约 2000 次!
Fast R-CNN 见解 2:将所有模型并入一个网络
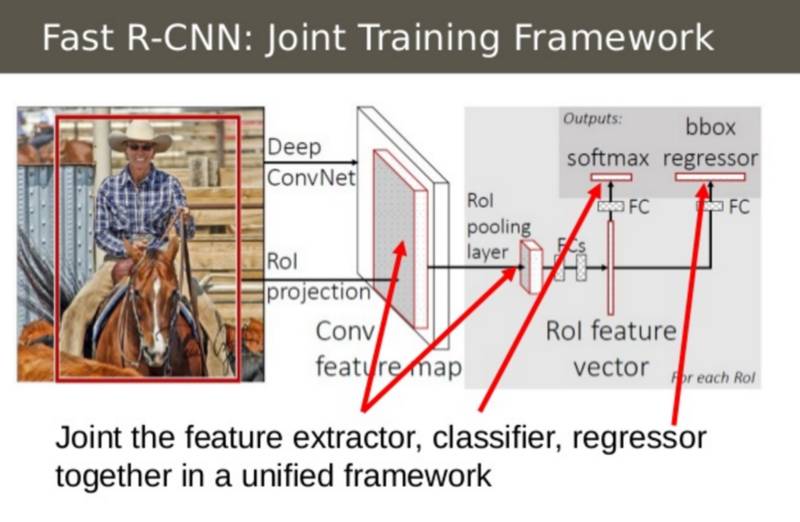
Fast R-CNN 将卷积神经网络(CNN),分类器和边界框回归器组合为一个简单的网络。
Fast R-CNN 的第二个见解是在单一模型中联合训练卷积神经网络、分类器和边界框回归器。之前我们有不同的模型来提取图像特征(CNN),分类(SVM)和紧缩边界框(回归器),而 Fast R-CNN 使用单一网络计算上述三个模型。
在上述图像中,你可以看到这些工作是如何完成的。Fast R-CNN 在 CNN 顶部用简单的 softmax 层代替了支持向量机分类器(SVM classfier)以输出分类。它还添加了与 softmax 层平行的线性回归层以输出边界框坐标。这样,所有需要的输出均来自一个单一网络!下面是整个模型的输入和输出:
输入:带有区域提案的图像
输出:带有更紧密边界框的每个区域的目标分类
2016:Faster R-CNN—加速区域提案
即使有了这些进步,Faster R-CNN 中仍存在一个瓶颈问题——区域提案器(region proposer)。正如我们所知,检测目标位置的第一步是产生一系列的潜在边界框或者供测试的兴趣区域。在 Fast R-CNN,通过使用选择性搜索创建这些提案,这是一个相当缓慢的过程,被认为是整个流程的瓶颈。

微软研究院首席研究员孙剑领导了 Faster R-CNN 团队。
2015 年中期,由 Shaoqing Ren、Kaiming He、Ross Girshick 和孙剑组成的微软研究团队,找到了一种被其命为 Faster R-CNN 的架构,几乎把区域生成步骤的成本降为零。
Faster R-CNN 的洞见是,区域提案取决于通过 CNN 的前向(forward pass)计算(分类的第一步)的图像特征。为什么不重复使用区域提案的相同的 CNN 结果,以取代单独运行选择性搜索算法?
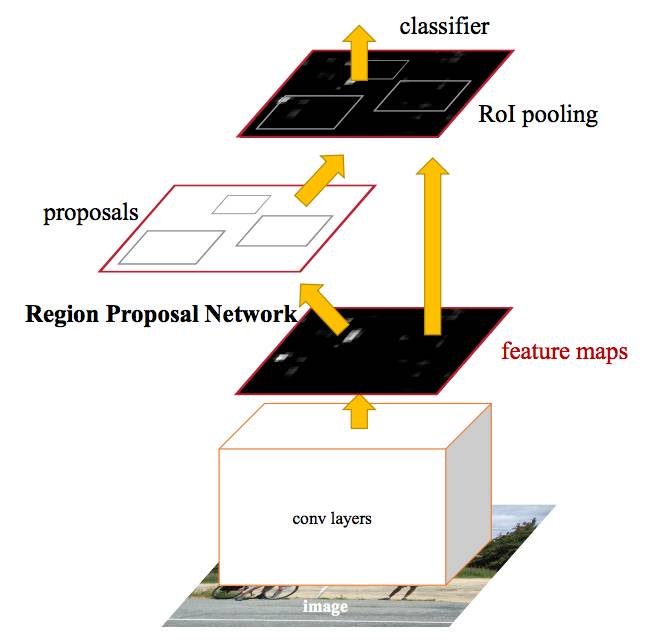
在 Faster R-CNN,单个 CNN 用于区域提案和分类。
事实上,这正是 Faster R-CNN 团队取得的成就。上图中你可以看到单个 CNN 如何执行区域提案和分类。这样一来,只需训练一个 CNN,我们几乎就可以免费获得区域提案!作者写道:
我们观察到,区域检测器(如 Fast R-CNN)使用的卷积特征映射也可用于生成区域提案 [从而使区域提案的成本几乎为零]。
以下是其模型的输入和输出:
输入:图像(注意并不需要区域提案)。
输出:图像中目标的分类和边界框坐标。
如何生成区域
让我们花点时间看看 Faster R-CNN 如何从 CNN 特征生成这些区域提案。Faster R-CNN 在 CNN 特征的顶部添加了一个简单的完全卷积网络,创建了所谓的区域提案网络。
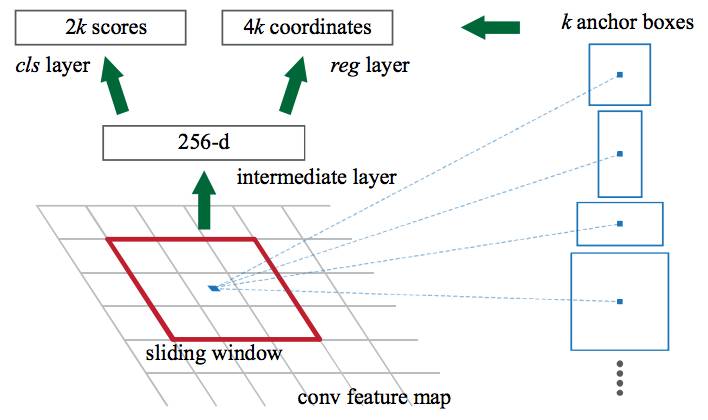
区域提案网络在 CNN 的特征上滑动一个窗口。在每个窗口位置,网络在每个锚点输出一个分值和一个边界框(因此,4k 个框坐标,其中 k 是锚点的数量)。
区域生成网络的工作是在 CNN 特征映射上传递滑动窗口,并在每个窗口中输出 k 个潜在边界框和分值,以便评估这些框有多好。这些 k 框表征什么?

我们知道,用于人的边框往往是水平和垂直的。我们可以使用这种直觉,通过创建这样维度的锚点来指导区域提案网络。
我们知道图像中的目标应该符合某些常见的纵横比和尺寸。例如,我们想要一些类似人类形状的矩形框。同样,我们不会看到很多非常窄的边界框。以这种方式,我们创建 k 这样的常用纵横比,称之为锚点框。对于每个这样的锚点框,我们在图像中每个位置输出一个边界框和分值。
考虑到这些锚点框,我们来看看区域提案网络的输入和输出:
输入:CNN 特征图。
输出:每个锚点的边界框。分值表征边界框中的图像作为目标的可能性。
然后,我们仅将每个可能成为目标的边界框传递到 Fast R-CNN,生成分类和收紧边界框。
2017:Mask R-CNN - 扩展 Faster R-CNN 以用于像素级分割

图像实例分割的目的是在像素级场景中识别不同目标。
到目前为止,我们已经懂得如何以许多有趣的方式使用 CNN,以有效地定位图像中带有边框的不同目标。
我们能进一步扩展这些技术,定位每个目标的精确像素,而非仅限于边框吗?这个问题被称为图像分割。Kaiming He 和一群研究人员,包括 Girshick,在 Facebook AI 上使用一种称为 Mask R-CNN 的架构探索了这一图像分割问题。

Facebook AI 的研究员 Kaiming He 是 Mask R-CNN 的主要作者,也是 Faster R-CNN 的联合作者。
很像 Fast R-CNN 和 Faster R-CNN,Mask R-CNN 的基本原理非常简单直观。鉴于 Faster R-CNN 目标检测的效果非常好,我们能将其简单地扩展到像素级分割吗?
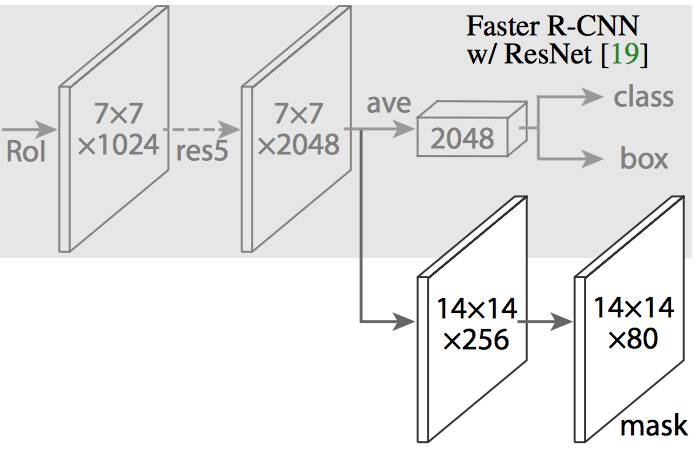
在 Mask R-CNN 中,在 Faster R-CNN 的 CNN 特征的顶部添加了一个简单的完全卷积网络(FCN),以生成 mask(分割输出)。请注意它是如何与 Faster R-CNN 的分类和边界框回归网络并行的。
Mask R-CNN 通过简单地向 Faster R-CNN 添加一个分支来输出二进制 mask,以说明给定像素是否是目标的一部分。如上所述,分支(在上图中为白色)仅仅是 CNN 特征图上的简单的全卷积网络。以下是其输入和输出:
输入:CNN 特征图。
输出:在像素属于目标的所有位置上都有 1s 的矩阵,其他位置为 0s(这称为二进制 mask)。
但 Mask R-CNN 作者不得不进行一个小的调整,使这个流程按预期工作。
RoiAlign——重对齐 RoIPool 以使其更准确
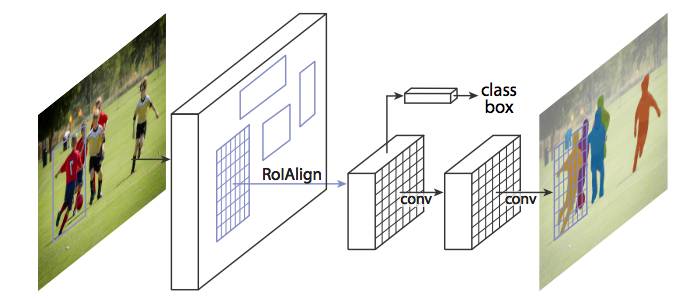
图像通过 RoIAlign 而不是 RoIPool 传递,使由 RoIPool 选择的特征图区域更精确地对应原始图像的区域。这是必要的,因为像素级分割需要比边界框更细粒度的对齐。
当运行没有修改的原始 Faster R-CNN 架构时,Mask R-CNN 作者意识到 RoIPool 选择的特征图的区域与原始图像的区域略不对齐。因为图像分割需要像素级特异性,不像边框,这自然地导致不准确。
作者通过使用 RoIAlign 方法简单地调整 RoIPool 来更精确地对齐,从而解决了这个问题。
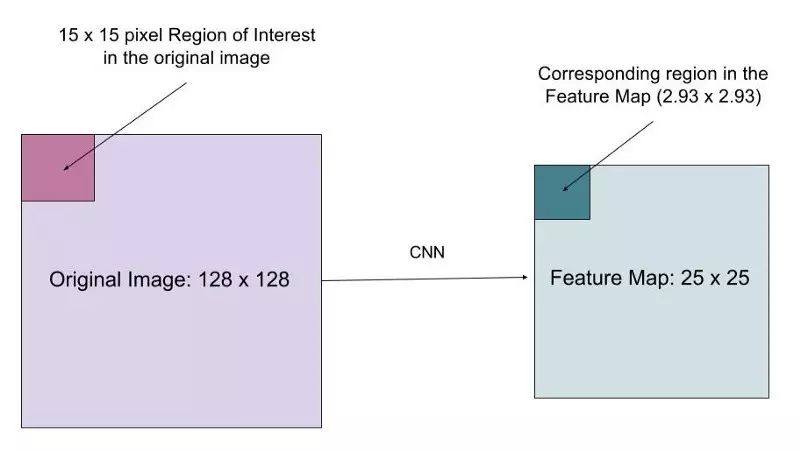
我们如何准确地将原始图像的相关区域映射到特征图上?
想象一下,我们有一个尺寸大小为 128x128 的图像和大小为 25x25 的特征图。想象一下,我们想要的是与原始图像中左上方 15x15 像素对应的区域(见上文)。我们如何从特征图选择这些像素?
我们知道原始图像中的每个像素对应于原始图像中的〜25/128 像素。要从原始图像中选择 15 像素,我们只需选择 15 * 25/128〜=2.93 像素。
在 RoIPool,我们会舍弃一些,只选择 2 个像素,导致轻微的错位。然而,在 RoIAlign,我们避免了这样的舍弃。相反,我们使用双线性插值来准确得到 2.93 像素的内容。这很大程度上,让我们避免了由 RoIPool 造成的错位。
一旦这些掩码生成,Mask R-CNN 简单地将它们与来自 Faster R-CNN 的分类和边界框组合,以产生如此惊人的精确分割:

Mask R-CNN 也能对图像中的目标进行分割和分类.
展望
在过去短短 3 年里,我们看到研究界如何从 Krizhevsky 等人最初结果发展为 R-CNN,最后一路成为 Mask R-CNN 的强大结果。单独来看,像 MASK R-CNN 这样的结果似乎是无法达到的惊人飞跃。然而,通过这篇文章,我希望你们认识到,通过多年的辛勤工作和协作,这些进步实际上是直观的且渐进的改进之路。R-CNN、Fast R-CNN、Faster R-CNN 和最终的 Mask R-CNN 提出的每个想法并不一定是跨越式发展,但是它们的总和却带来了非常显著的效果,帮助我们向人类水平的视觉能力又前进了几步。
特别令我兴奋的是,R-CNN 和 Mask R-CNN 间隔只有三年!随着持续的资金、关注和支持,计算机视觉在未来三年会有怎样的发展?我们非常期待。

原文链接:https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


