![]()
该活动由图灵奖得主Yoshua Bengio教授与微众银行首席人工智能官杨强教授、滴滴智能控制首席科学家唐剑博士领衔,由微众银行(WeBank)、滴滴出行(Didi Chuxing)和加拿大蒙特利尔学习算法研究所(Mila)共同主办,AI研习社协办,AI科技评论作为独家合作媒体共同举办。
以下,AI科技评论整理了Yoshua Bengio、杨强和唐剑的演讲的主要观点,以及问答内容。
由于时间限制,嘉宾在演讲过程中仅回答了部分问题,AI研习社还特别对观众的问题进行了收集,并请嘉宾在之后进行录播回答
。本次论坛将整理有回放,感兴趣的观众可以关注文末“阅读原文”页面,观众提问整理在文末展示。
Yoshua Bengio
在本次论坛中,Yoshua Bengio的演讲主题是《深度学习:从系统1到系统2》。
Yoshua Bengio提到,人的认知系统包含两个子系统:系统1和系统2。系统1是直觉系统,主要负责快速、无意识、非语言的认知,这是目前深度学习主要做的事情;系统2是逻辑分析系统,是有意识的、带逻辑、规划、推理以及可以语言表达的系统,这是未来深度学习需要着重考虑的。
对于系统2来说,基本的要素包括注意力和意识,意识先验可以使用稀疏因子图模型来实现,这是一个思路,实现了因果关系。从人的角度来看意识,语言是高层次的表示,这需要把人的两个认知系统即系统1和系统2有机的结合起来,也就是说把低层次的表示和高层次的决策结合起来,从而实现系统进化。
对于如何用深度学习来实现系统2,Yoshua Bengio指出,最关键就是处理数据分布中的变化。对于处理数据分布,传统机器学习都是基于独立同分布的假设,但实际需要关注更多的是分布外泛化。尤其是从强化学习的角度来考虑,需要考虑哪些是影响数据分布变化的因素。
1、深度学习是基于统计的学习,其预测结果中总会有一些错误,而基于符号逻辑的AI必须在逻辑上保持一致并且没有错误。那么将这两个系统结合起来时,如何使这两个系统中的矛盾得到解决?
我选择的途径不是重用经典符号系统方法,因为太脆弱了,甚至比现在的AI系统还要脆弱。这是因为经典符号系统要求一切都必须是完美的,它们不能很好地处理错误。
现代机器学习实际上是基于概率观点的。因此,错误不是问题。与此相关的另一个联系,是使用深度学习处理推理的现代方法。
例如,如果不想做出硬性决策,而要做出软性决策,则可以依靠规划。软概率决策的优点是,我们可以对不同的元素施加不同的权重,其中一个可能会获得90%的成功率。但是我们仍然会收到学习信号,这使学习变得非常高效。
我不是竞争的忠实拥护者,我认为协作的效率更高。如果共享知识,知识将以更快的速度增长,那就是我们在科学中的做法。
杨强
在本次论坛中,杨强教授的演讲主题是《结合联邦学习与迁移学习》。
在演讲中,杨强教授介绍到他们正在把联邦学习和迁移学习结合起来。
联邦学习在应用中往往存在一个现象,即每一个数据拥有方所持有的数据,也许和别人的分布是不一样的,也许和别人的表达也是不一样的。比方说一个摄像头中可能看到更多的是男性,另一个摄像头看到的更多的是女性,这样的分布是不一样的。在这种状况下建模,对机器学习来说是有困难的,因为机器学习要求数据遵从统一分布,并且表达也是类似的,而不能一部分数据是图像,而另一部分数据是文字。这种异构的数据在现实中经常发生,所以有必要来做联邦学习和迁移学习的结合。
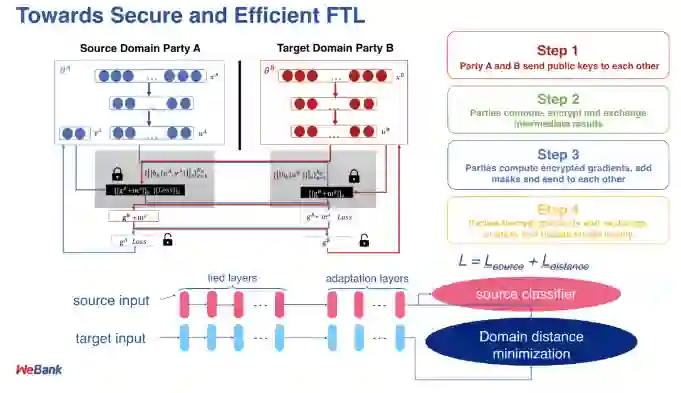
这种结合可以体现在各个层面,以深度学习为例,左边的图展示的是两个神经网络,蓝色的神经网络有很多数据标签,所以可以建一个很好的神经网络模型,但是红色的神经网络却缺乏这样的数据,我们考虑将蓝色神经网络的数据迁移到红色的神经网络中。过去,迁移学习是不考虑隐私的,模型和数据都可以被物理运到红色神经网络进行知识迁移。现在有了隐私顾虑,是不是可以用联邦学习达到迁移学习的效果?答案是可以。
在两边沟通的过程中,除了隐私加密以外,还要进行一项迁移学习的运算,保证两边数据的分布和两边数据的表达都是相同的。要达到这一点,双方首先要把各自方的模型和数据迁移到一个共同的子空间,这个迁移过程可以通过某种数学运算进行,比如和函数,效果相当于我们把神经网络的某些层迁移到了新的场景下。
这个工作中需要经过多番迁移和对比,所以效率很低。最近他们又提出了一个加速算法,使得每一方本地的数据计算尽量多,跨合作方的计算尽量少,以联邦块的方式进行梯度交互,结果证明效果非常好。另外随机森林也可以采用这个方法实现迁移学习和联邦学习的结合。
为实现良好模型,进行联邦训练需要的参数量有多大?当前的基础设施是否足够?
这是一个很好的问题,因为效率是一个重大挑战。因此,在建立联邦学习两方之间的关系时,需要传递梯度信息以及损失信息,尽管采用的是加密形式。
因此,我们会面临挑战。一个是加密和解密,另一个是分布式通信。我们无需在双方之间建立特定的高速通信,尽管这样做会有所帮助。我们正在探索通过底层网络结构来优化此过程。
唐剑
唐剑博士的演讲主题是《AIoT关键技术及其在交通中的应用》。
在演讲中,唐剑指出,AIoT的关键技术是深度模型压缩,而相应的解决方案则是一种自动化和系统化的框架。然后,他展示了运输场景中的一些应用,并描绘了未来的研究方向。
唐剑在博士生期间的研究课题是无线传感器网络,后来人们称该方向为IoT,也就是今天的物联网,现在正变得越来越流行。IoT可以简单理解为连接传感器等事物的通信网络。
唐剑博士提出了一个很简单的等式,AIoT=AI+IoT,IoT可以简单理解为连接传感器等事物的通信网络,AIoT就是利用AI算法和模型使得物联网变得越来越智能。而
以
后的大趋势将是,大量AI学习模型将被部署在资源受限的IoT设备上。
目前的挑战在于,一方面,那些闲置的IoT设备通常很便宜,特别是它们通常具有非常有限的计算能力、内存和存储。另一方面,实际上很多应用程序都需要拥有实时性能。例如,在辅助驾驶系统中,就对实时性有非常强烈的要求。
所以,这是AI学习模型要考虑的基本权衡,即准确率与模型大小之间的关系。
如果要实现更高的准确率,一般需要选择更大更深的深度学习模型,但是很难将这些模型部署到廉价且资源有限的设备上。这也是AIoT面临的最大挑战,而对应的解决方案就是深度模型压缩。
目前有很多对深度模型进行加速和压缩的方法,其中三种最流行的方法是权重修剪、量化和知识蒸馏。
关于权重修剪,唐剑博士特别提到了发表在NIPS2015上的一项工作提出的非结构化修剪方法。
量化就是用更低的精度对权重进行取值,从而大大减少模型尺寸,只是可能损失一些准确率。
知识蒸馏最初由Hinton发表在NIPS2014的论文中提出。主要思想就是将大模型(老师网络)的泛化能力迁移到小模型(学生网络)上,具体来说就是讲老师网络预测的类别概率作为“软”标签来训练学生网络。
接下来,唐剑博士介绍了他们的解决方案,即自动化和系统化的框架。
该框架事实上是引入了一种自动化的过程,以确定模型压缩中重要的超参数。
唐剑博士发现,在模型压缩中,最重要的超参数其实是每个层的压缩率。
该框架可以将模型压缩为80倍,而准确率损失仅有1%。
滴滴在安全车载智能硬件桔视中搭载了预警系统,借助深度学习算法,可以为驾驶员提供疲劳驾驶提醒、分心驾驶检测、烟雾检测等等,有助于安全驾驶。
其中,睡意检测模型应用了权重修剪和量化方法,而高级驾驶员辅助系统则应用了知识蒸馏方法。
最后,唐剑博士总结了模型压缩的未来研究方向,包括基于AutoML的方法、联合权重修剪、量化和知识蒸馏的方法、目标检测模型的压缩和加速、语义/实例分割模型的压缩和加速、结合压缩的编译、系统级别的调度和资源优化等。
1、滴滴和其他公司的驾驶安全检测系统比如Mobileye之间的区别?
据我所知,Mobileye是辅助系统的领先者。它实际上提供所谓的L2级辅助。它实际上已连接基于计算机视觉的系统与汽车上的控制系统。而我们的系统并不直接与汽车的控制系统相连,这是最大的不同。
2、开发这些驾驶安全检测系统的最终目的是什么?AI要多久才能实现完全的自动驾驶?
基本上,尤其是L5级自动驾驶,还有很长的路要走,至少还需要五到十年时间才能实现。因此,我认为在当前阶段,拥有辅助驾驶系统仍然非常重要,它可以帮助我们改善路况和减少事故。
观众问题
Yoshua Bengio:
(1) 你如何看待中美在AI领域的算力差距?
(2) 你如何看待机器学习中的对待样本?
(3) 关于OOD(out-of- distribution)泛化,已知IID(独立同分布)假设不适用的情况下,现在他们组里对新假设的研究进展如何?他觉得主要的难点会在什么地方?
(4) 基于变量间的稀疏因子图(sparse factor graph)来进行因果关系推断的研究,是否可以利用图神经网络来捕捉很好的因果关系?
杨强:
(1)在联邦学习中,如果所有参与者都没有完整的标签(垂直联邦案例),我们如何衡量联邦训练的性能(例如准确性等)?
(2)联邦学习参与者用于实现良好模型而改组的参数有多少?当前的互联网基础设施足够应对这一需求了吗?
(3)假如银行或医院也参与到联邦学习中,成为数据管理员,他们并不希望参与的数据透明化,或为个人数据管理员拥有、接触,您是否有考虑到其中可能涉及的法律或道德问题?
(4)您如何看待无监督学习与自监督学习的发展前景?
(5)机器如何才能学会感知与系统思考,而不仅是分类( family resemblance)?
(6)迁移学习可以创建强大的逻辑吗?
(7)您在这次分享中将Bert与GPT-3在用少量数据训训练预训练语言模型上进行了对比,主要想表达的观点是什么?
(8)在联合学习中,集中训练有什么作用?
(9)在共享知识/模型时,如何定义(或保护)共享知识的所有权?
(10)杨教授提到,当没有目标域标签时,应使用域自适应。当一些目标域标签存在时,应使用监督迁移学习。关于“一些”,您是否能具体谈谈?我们是否可以简单地标记一些目标域数据并减轻对域适应的使用?
唐剑:
(1)滴滴研究网络压缩的商业场景是怎样的?
(2)滴滴所研究或应用的网络压缩适用于哪些应用或商业场景?
(3)请问Mobileye和滴滴这两者的DMS有什么区别?
AI科技评论联合【机械工业出版社华章公司】为大家带来15本“新版蜥蜴书”正版新书。
在10月24号头条文章《1024快乐!最受欢迎的AI好书《蜥蜴书第2版》送给大家!》留言区留言,谈一谈你对本书内容相关的看法和期待,或你对机器学习/深度学习的理解。
AI 科技评论将会在留言区选出 15名读者,每人送出《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》一本(在其他公号已获赠本书者重复参加无效)。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月24日 - 2020年10月31日(23:00),活动推送内仅允许中奖一次。
![]()
点击阅读原文,直达直播专题页~