杨强教授:AI算法重点转向关注数据安全隐私
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
近日,国际人工智能领域最为权威重要的学术会议之一,第三十三届AAAI人工智能顶级会议(AAAI-19 The National Conference on Artificial Intelligence)在美国夏威夷举行。

在AAAI 2019上,国际人工智能学会理事长,微众银行首席人工智能官(CAIO)杨强教授作为特邀演讲嘉宾,发表了主题为「GDPR、数据短缺和人工智能」的特邀演讲(AAAI Invited Talk),讲述了「联邦迁移学习」的安全的分布式建模原理和在数据合规上的意义,同时微众银行首次发布了基于联邦学习的「联邦AI生态系统」(Federated AI Ecosystem),开源了「联邦AI解决方案」FATE(Federated AI Technology Enabler),开启了开启FL技术新征程。

▌杨强教授关于联邦迁移学习演讲现场
那么,到底什么是「联邦学习」?为什么我们需要用到联邦学习?
「联邦学习」(也翻译为联盟学习/联合学习)可以理解为一个数据联邦,联邦内各企业身份地位相同,无须进行数据移动或互通,而是通过某种加密机制进行参数交换,从而建立一个虚拟的共有模型,让彼此都能获得模型效果的提升
大数据架构为中心的算法导向
在弱AI时代,人工智能对场景和数据的依赖性仍然极大,而数据获取却愈发困难,主要体现在:
一方面,数据孤岛现象严重,利用率差成本高。定向数据的收集与标注本就是个去芜存精的过程,需要排除大量无用与低质量数据,要采集到足够的有效数据,其难度与成本不是每个公司都愿意或有能力负荷的;另外从数据资源分布来看,大量行业数据只掌握在少数企业手中,或零散分布在不同企业,考虑到竞争与利益关系、数据隐私等,数据很难共通,孤岛现象十分严重。
另一方面,数据安全与用户隐私问题愈被看重。随着企业间的数据争夺战愈演愈烈,数据市场的竞争与交易开始逐步走向规范,监管也愈加严格,数据互通愈发困难。
如欧盟在2018年5月25日正式实施了史上最严的个人数据保护条例GDPR(通用数据保护条例),法案强调,机器学习模型必须具有可解释性,而且对于收集用户数据,必须公开、透明,用户可以要求经营者删除其个人数据并且停止利用其数据进行建模。
2019年1月21日,谷歌公司就成为依据此法遭高额处罚的首家美国科技公司,被罚款5000万欧元。
「这样的大环境下,下一步人工智能的重点会从以 AI 基础算法为中心的导向,转移到以保障安全隐私的大数据架构为中心的算法导向上。」(杨强教授语)
联邦学习的出现,正好可以解决以上两个问题。
模型训练与云端存储分离
传统的「机器学习」一般在单机或者集群上集中处理数据、训练模型。像我们常说的「云计算」便是把各自的数据聚到一起,通过远程的处理能力来产生结果,再把结果下载到本地加以使用。
这样的处理方式十分有效,但显然并不适用所有场景。对例如金融、家庭、智能驾驶等对数据隐私性或处理速度要求较高的场景而言仍未达到要求。
「联邦学习」的突破则在于,它将机器学习的「模型训练」和「云端存储」二者成功解绑,所有训练数据留在企业本地,上传的只是模型的变更部分。此外,系统还会将所有企业上传的模型差异做平均化更新,以改善共享模型,改善后的模型企业可立即使用。从而数据隐私与处理速度得到了保证。
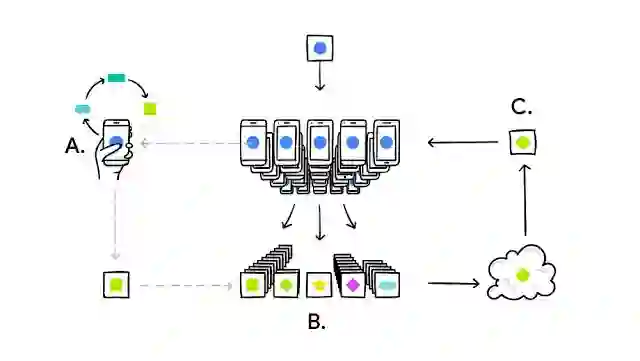
▌A.本地化的模型训练 B.基于大量用户的模型改进融合为共享模型 C.不断重复,完善共享模型
极视角,极市平台与联邦学习
极视角与杨强教授所在的微众银行建立了战略合作伙伴关系,极视角成为国内首家将「联邦学习」应用于计算机视觉领域的AI公司,将辅助优化极市平台现有图像识别领域70%的算法应用。
对于开发者而言,开源的FATE提供了所必须的多方协同建模工作流管理、加密机器学习工具库和并行计算基础设施抽象三层能力,同时提供了很多开箱即用的联邦学习算法和联邦迁移学习算法供开发者参考,能极大简化了联盟AI开发的流程并降低了部署难度。
系统预计在2019上半年上线,届时极视角将会挑选5~10个算法抢先上线,这些算法将在系统中自动实现模型训练—模型优化——反馈使用的闭环。欢迎关注~
*延伸阅读
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~




