清华大学、中国人工智能学会重磅发布《2019人工智能发展报告》(附报告下载)

11月30日下午,2019中国人工智能产业年会重磅发布《2019人工智能发展报告》(Report of Artificial Intelligence Development 2019)。唐杰教授代表报告编写相关单位就《2019人工智能发展报告》主要内容进行了介绍。报告力图综合展现中国乃至全球人工智能重点领域发展现状与趋势,助力产业健康发展,服务国家战略决策。
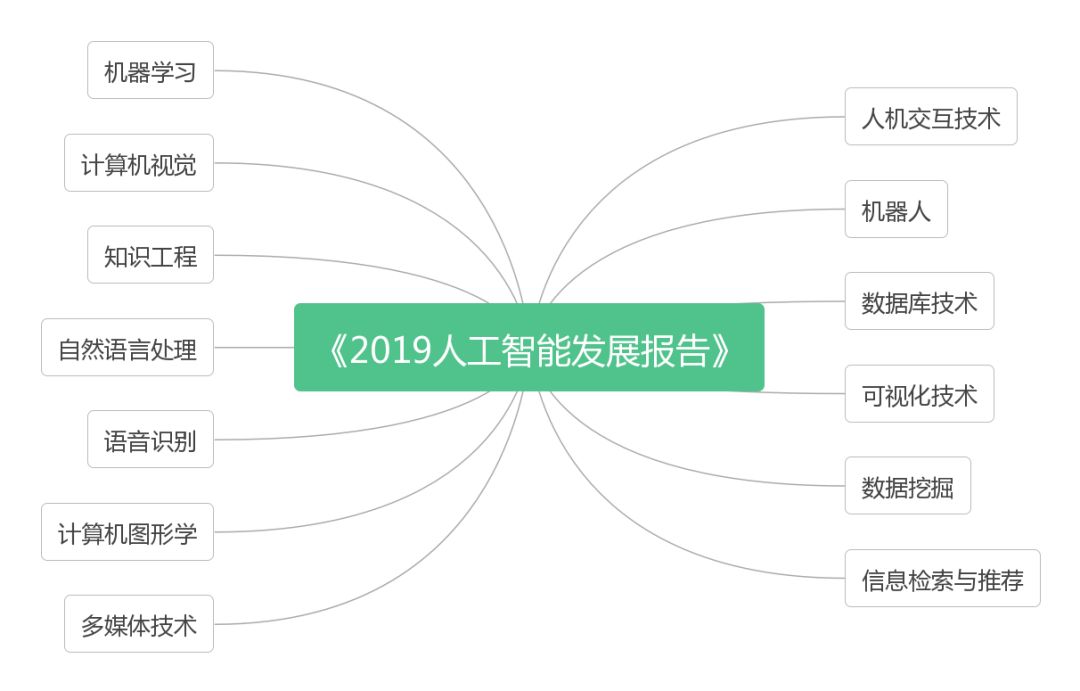 报告涉及AI 13个子领域
报告涉及AI 13个子领域
内容涵盖了人工智能13个子领域,包括:机器学习、知识工程、计算机视觉、自然语言处理、语音识别、计算机图形学、多媒体技术、人机交互、机器人、数据库技术、可视化、数据挖掘、信息检索与推荐。
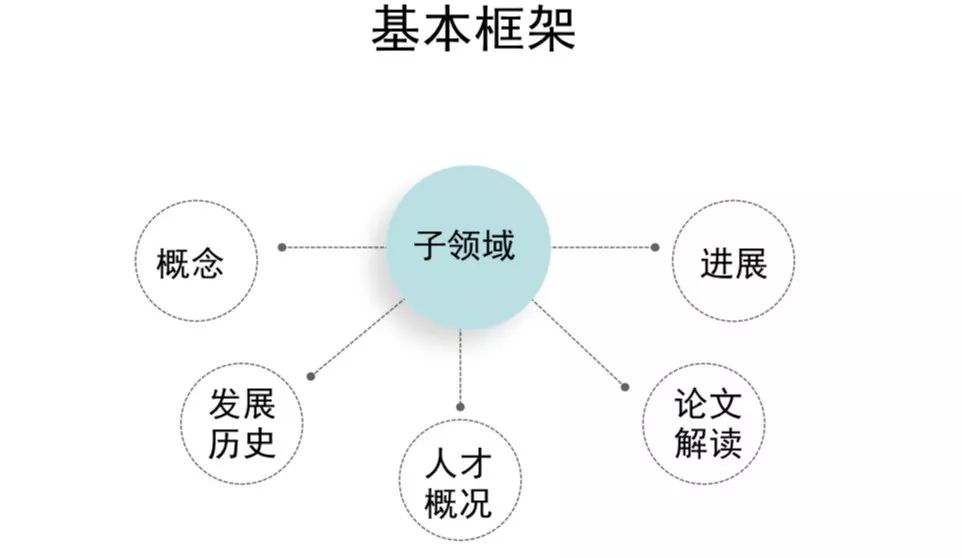
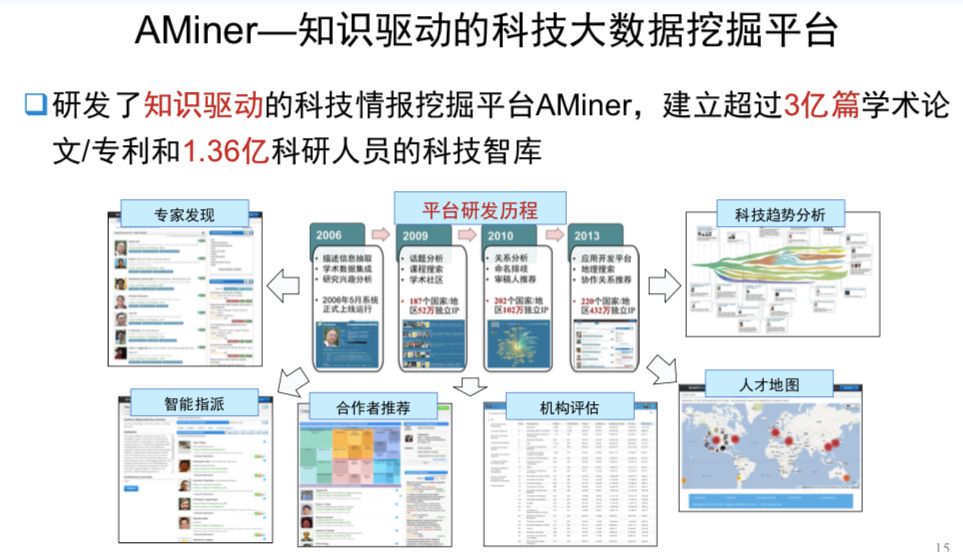
报告基本框架如上图所示,包括领域概念阐释、发展历史梳理、人才概括、关键论文解读以及相应领域的前沿进展。
1、报告呈现两大亮点
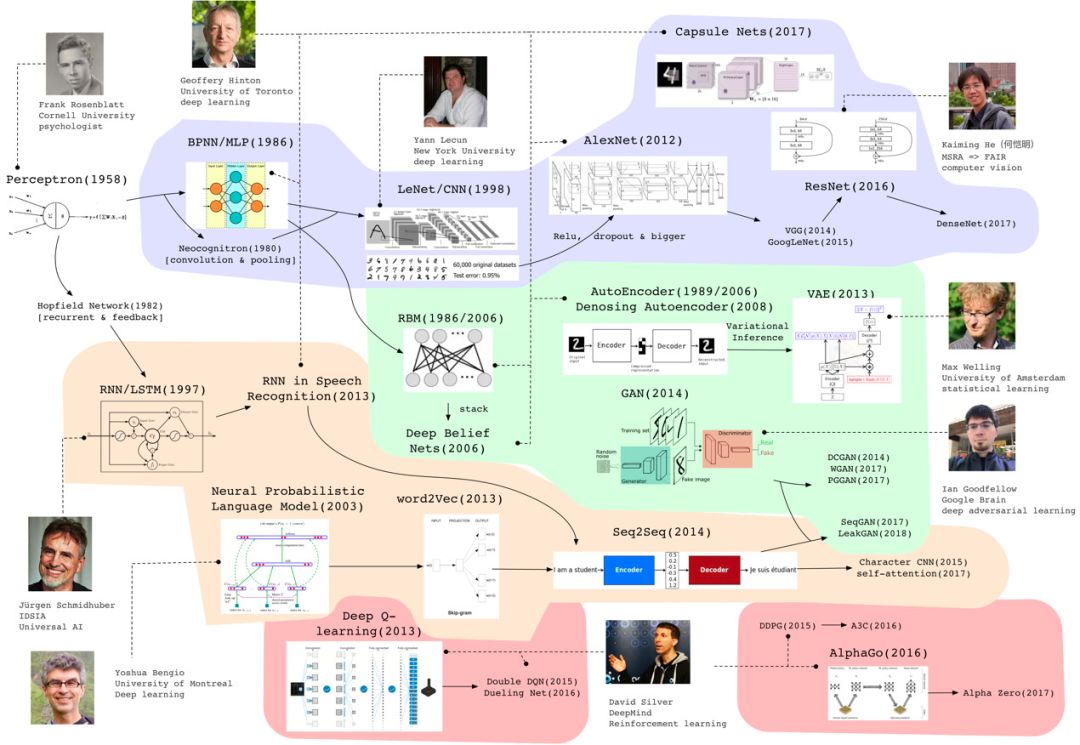
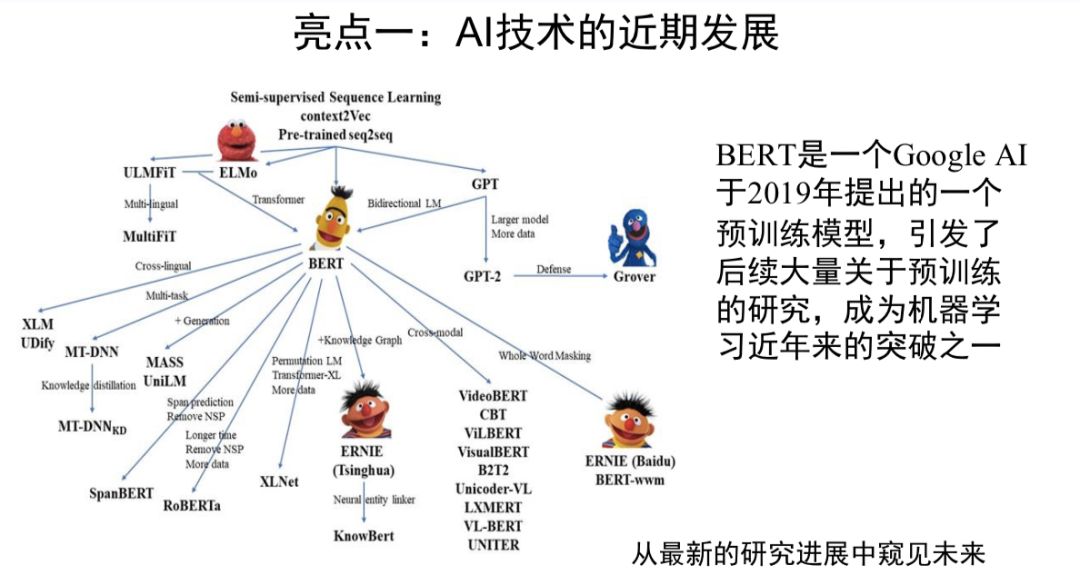
亮点一还体现在详细的知识图谱中。
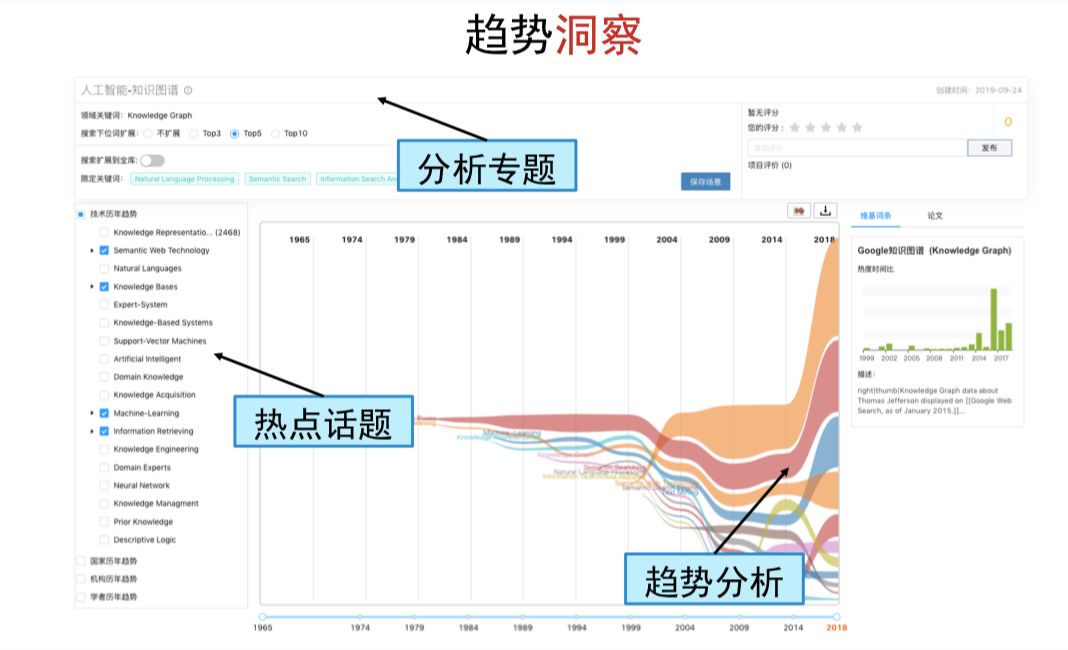
唐杰教授指出,“每一个领域都有丰富的知识图谱架构,从知识图谱可以一览整个领域的发展脉络。同时,通过这样的知识图谱还可以进一步开展包含主题分析、热点话题分析等多层次的趋势分析、趋势洞察等”。
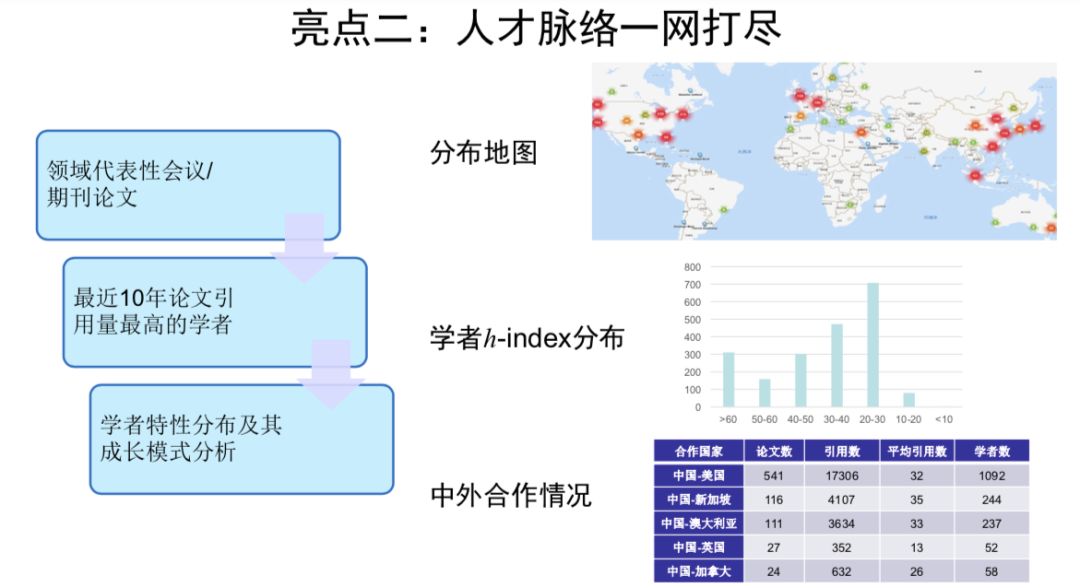
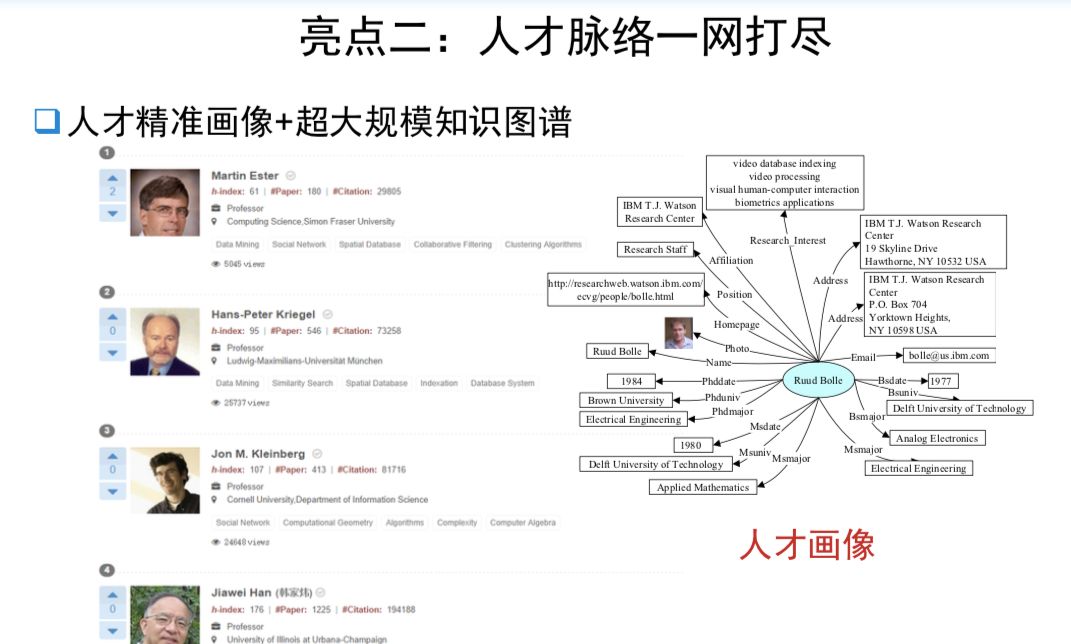
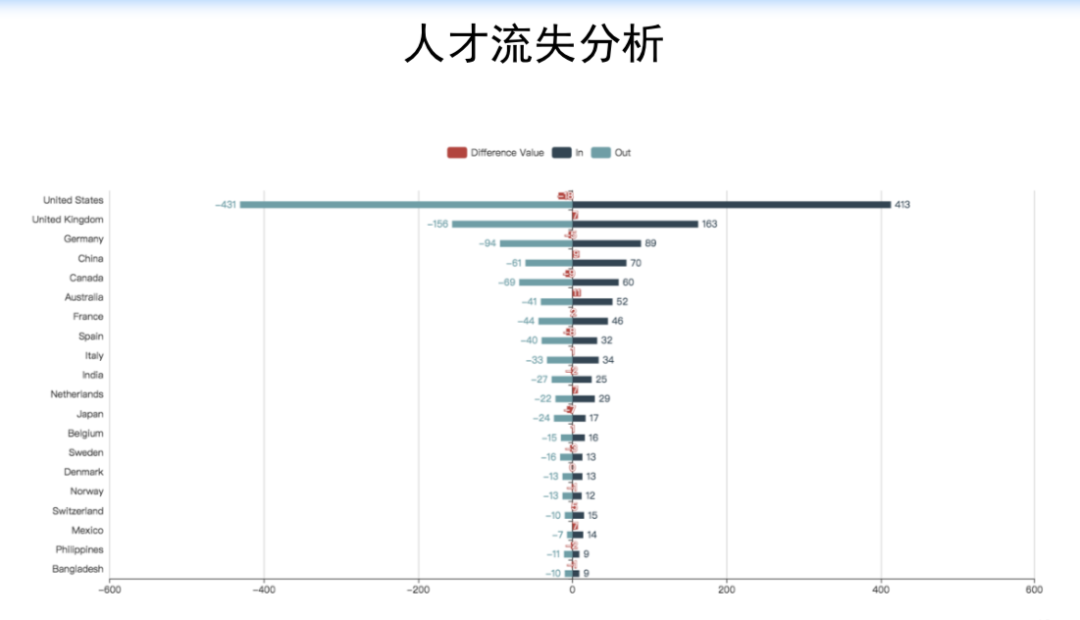


 点击“阅读原文”查看
人工智能的 10 大应用趋势
点击“阅读原文”查看
人工智能的 10 大应用趋势
登录查看更多
相关内容

Arxiv
6+阅读 · 2018年6月14日
Arxiv
3+阅读 · 2018年5月1日



相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年6月14日
Arxiv
3+阅读 · 2018年5月1日