图像翻译哪家强?香港科技大学博士揭秘:预训练is All You Need!
![]()
新智元报道
新智元报道
【新智元导读】最近一位香港科技大学博士提出了一个新模型PITI,成功在图像翻译任务中取得新sota,并且生成质量获得93.6%的认可,背后的核心科技竟然是预训练?
图像到图像翻译(Image-to-Image Translation)任务可以将一张输入图像进行指定的风格转换,也就是最终学习到一个函数能让A域图像映射到B域内,以此为基础可以解决许多实际问题,如风格迁移、属性迁移、图像超分辨率等等,在内容创作领域的应用场景十分丰富。

图像到图像的翻译问题本质上与使用深度生成模型(deep generative model)学习输入的自然图像的条件分布有关。
目前大量的相关工作都是在特定任务上进行定制模型,虽然推动了艺术的发展,但现有的解决方案要产生满足实际使用的高保真图像仍然很困难。
随着预训练范式在各种视觉和自然语言处理任务的成功,香港科技大学和微软亚洲研究院的研究人员提出了一个全新的模型PITI,成功将预训练模型引入到图像翻译任务中,在各种下游任务中的生成质量都得到显著提高,并且新方法在few-shot图像翻译方面也展现出极大潜力。

论文链接:https://tengfei-wang.github.io/PITI/index.html
代码链接:https://github.com/PITI-Synthesis/PITI
其关键思想是使用预训练的神经网络来捕捉自然图像流形(natural image manifold),从而使图像翻译等同于遍历该流形并找到与输入语义相关的可行点。
具体来说,合成网络应该使用大量的图像进行预训练作为生成先验,从其潜空间的任何采样都会生成一个合理的输出。有了一个强大的预训练合成网络后,下游的训练只需要将用户的输入适应于预训练的模型所能识别的隐藏表征即可。
之前的工作为了适应图像的语义分布,可能会降低图像生成的质量,而这篇论文提出的新框架由于在预训练阶段已经保证生成的样本严格位于自然图像流形上,所以图像翻译的质量也不会受到损失。

生成性先验应当具备以下两个特性:
1、预训练的模型应该有很强的能力来模拟复杂的场景,最好能捕捉到整个自然图像的分布,而GANs模型通常用于特定领域的图像生成,比如人脸。
2、需要从两种潜码中生成图像:一种表征图像语义,另一种说明图像变化。一个语义和低维的潜码对于下游任务来说是至关重要的,否则将很难把不同的模式输入映射到一个复杂的潜空间。
基于上述两点观察,研究人员决定采用GLIDE模型作为预训练生成先验,它是一个在海量数据上训练的扩散模型,可以生成各种类别图像。由于GLIDE模型的训练输入为文本-图像对,所以它天然就是一个理想的语义潜空间。
为了适应下游任务,还需要训练一个特定任务的head用来把图像翻译的输入(例如segmentation mask)映射到预训练模型的潜空间。
因此,下游任务的网络采用了一个编码器-解码器的结构:编码器将输入翻译到一个与任务无关的潜空间,然后由一个解码器(即扩散模型)相应地生成一个可信的图像。
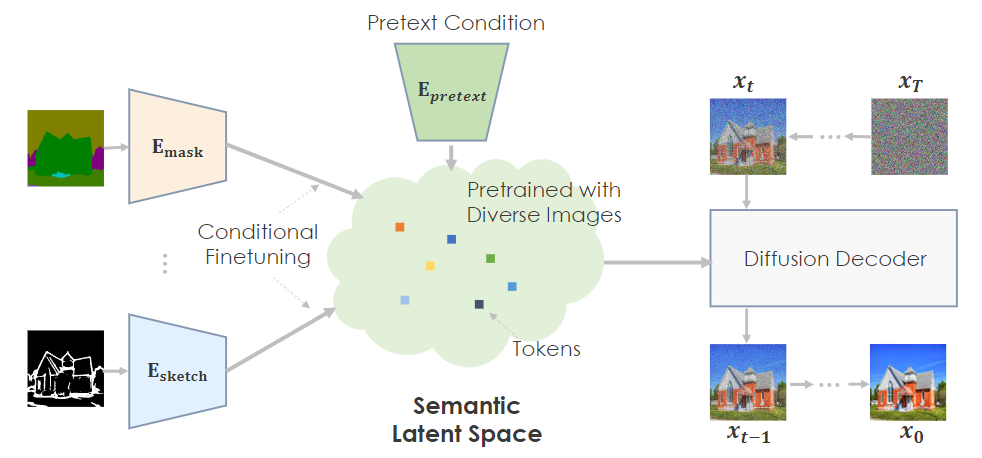
在实践中,首先固定预训练的解码器,只更新编码器,然后再对整个网络进行联合微调。这种分阶段的训练可以最大限度地利用预训练的知识,同时确保对给定输入的忠实性。
文中还进一步提出了提高扩散模型生成质量的技术:
1、采用分层生成策略,先生成一个粗略的图像,再进行超分辨率。由于去噪扩散步骤中的高斯噪声假设,扩散上采样器往往会产生过度平滑的结果,因此在去噪过程中引入对抗性训练,能够极大提高感知质量(perceptual quality)
2、常用的无分类器引导可能会导致图像过饱和,细节丢失严重。为了解决这个问题,研究人员提出对噪声统计进行归一化。这种规范化的引导采样可以生成更positive的引导,从而产生更高的生成质量。
在实验部分,研究人员采用了一个两阶段的微调方案:首先固定解码器,并以3.5e-5的学习率和128的batch size训练编码器;然后以3e-5的学习率联合训练整个模型。
在评估模型质量时,主要在三个图像到图像的翻译任务上进行:
1、mask-to-image synthesis(遮罩到图像的合成),ADE20K包含2万张室内和室外图像,有150个标注的语义类别用于训练。COCO包含12万训练图像,具有复杂的空间背景和182个语义类别。
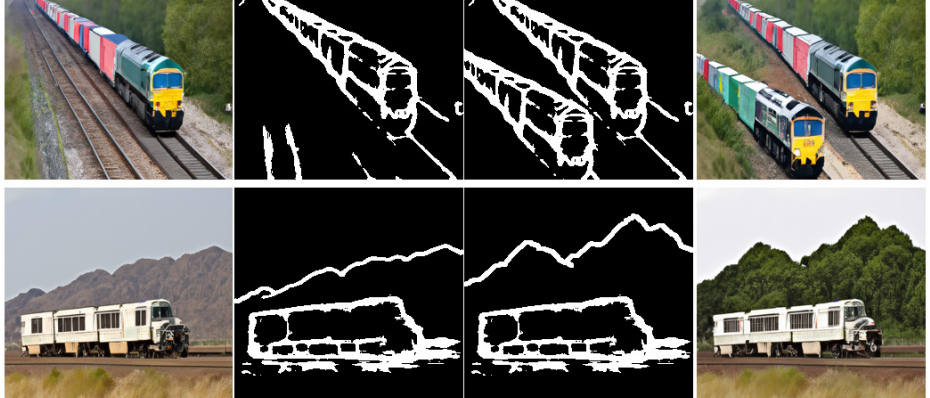
2、sketch-to-image synthesis(草图到图像的合成), 通过HED提取图像的草图,然后将提取的草图二值化。然后在COCO-Stuff和一个专有的数据集上进行评估,该数据集包括从Flickr收集的5万训练图像和2000测试图像的风景图片。

3、geometry-to-image synthesis(几何图形到图像的合成),用到的数据集为DIODE,其中包含2.5万训练图像和770张测试图像。
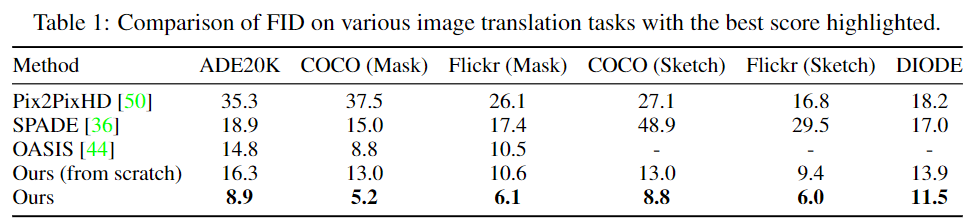
用于对比的基线模型有三个,分别为Pix2PixHD, SPADE, 和OASIS,因为目前为止还没有研究采用扩散模型,所以为了对比,作者还额外提供了一个扩散模型作为基线,但不采用预训练的方式,而是从头开始训练。
在先前工作中得出的结论为,InceptionNet测量的FID可能与感知质量不相关,因为该模型最初是为ImageNet分类训练的,而这篇论文在定量评估中使用CLIP模型计算FID,其特征空间更加稳健和可迁移。
实验结果显示提出的新方法始终以很大的幅度领先其他没有预训练的模型。与最先进的方法OASIS相比,在mask-to-image的合成上,FID方面取得了明显的改进(ADE20K上5.9,COCO上3.6,Flickr上4.4);在草图到图像和几何到图像的合成任务上也显示出良好的性能。
在定性分析上,主要是在不同任务上评估视觉效果。与在复杂场景中遭受严重伪影的从头训练的方法相比,预训练的模型大大改善了生成图像的质量和多样性。由于COCO数据集包含许多具有不同组合的类别,所有的基线方法都不能生成结构的视觉上的好结果。

相比之下,新方法可以在复杂场景下生成具有正确语义且生动的细节,而且该方法对不同的输入模式都具有良好的适用性。

研究人员还在亚马逊Mechanical Turk上对COCO-Stuff的mask-to-image合成进行了用户调研,有20位参与者投了3000票。参与者每次可以看到一对图像,需要选择一个自认为更真实的图像。
实验结果可以看到,文中所提出的方法在很大程度上超过了从头开始训练的模型和其他基线。

文章的第一作者Tengfei Wang是香港科技大学的三年级博士生,曾在腾讯AI Lab和MSRA实习过,主要研究方向为图像/视频处理,图像/视频生成和其他底层的视觉方向。




