编辑:LRS
【新智元导读】Transformer在图像分类任务上经过充分训练已经足以完全超越CNN模型,但GAN仍然是Transformer无法踏足的领域。最近港中文博士提出首个基于Transformer的条件GAN模型STransGAN,缓解了Transformer的部分问题,但成像质量仍不如CNN。
Transformer不仅在自然语言表达方面表现出色,在计算机视觉方面的潜力也被挖掘出来,不断称霸各大CV榜单。
Transformer的成功主要归功于注意力层的表示学习能力,这种能力也能够支持Transformer模型在其他领域上的应用。
最近,有研究人员将生成对抗网络(GAN)中常用的CNN主干网络替换为Transformer用于图像合成。一些前期研究结果表明,将Transformer直接用于GAN中并不是一件很容易的事,特别是之前被设计用于分类的GAN中经常会导致CNN图像合成性能的下降。
例如与基于CNN的StyleGAN2实现的3.16 FID相比,ViT作为主干网络的GAN模型仅在64×64 Celeba数据集中实现了8.92的FID。Frechet Inception Distance (FID) 计算结果为真实图像计算的特征向量与生成的图像之间的距离。
此外,这种Transformer结构也会使GAN网络的训练变得更加不稳定,严重依赖于手工调整超参数。
针对这个问题,来自香港中文大学的研究人员发表了一篇论文,旨在了解GAN 模型中Transformer 的内在行为,以缩小基于Transformer的GAN模型与基于CNN主干的GAN模型之间的性能差距。文中不仅研究了无条件的图像合成,而且还研究了如何更少地探索的条件设置。
这项研究也是首次在条件设计(conditional setting)下成功使用基于Transformer的GAN模型。
文章的第一作者是徐瑞,目前是香港中文大学多媒体实验室四年级博士生,导师是汤晓鸥教授,本科毕业于清华大学电子工程系。主要研究方向为深入学习及其在计算机视觉中的应用,正在进行的工作包括图像/视频绘画和图像合成。他在图像/视频分割、检测和实例分割方面有丰富的研究经验。
研究结果主要为Transformer 在GAN 中的使用提供了三点实践和设计原则:
特征提取的局部性对于图像分类中Transformer的效率和性能至关重要,在GAN 图像生成实验中也可以观察到同样的结果。特别是,在现有基于Transformer 的GANs 中实施的全局自注意力操作会降低图像合成性能,并且在计算上无法应用于高分辨率图像生成。在这些方法中,Swin Layer被证明是提供局部感应偏差的最有效的模块。
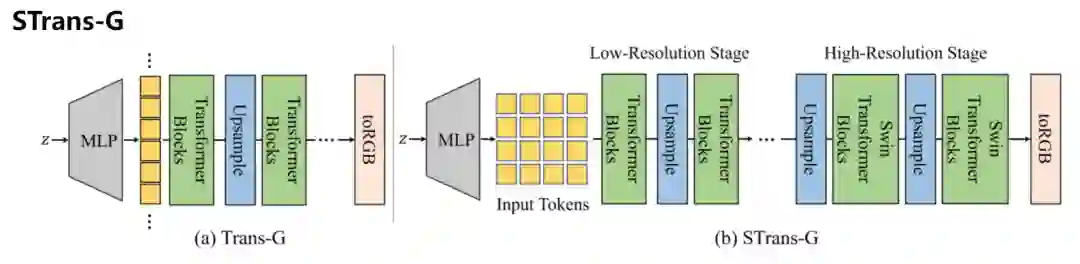
文中提出了一种新的基于Transformer的GAN网络架构设计,生成器部分称为STrans-G。
模型首先从一个简单的基线结构Trans-G开始,它由标准的视觉Transformer 块组成。然而,Trans-G生成的样本通常包含严重的人工痕迹(artifacts)和违和的细节,从而导致在视觉上看质量比较差。
通过分析注意力层的内在行为,可以发现全局注意力总是打破图像数据的局部性,特别是在合成高分辨率特征时。
这一发现也促使研究人员探索各种局部注意机制在生成真实高分辨率图像中的作用。在仔细比较了不同的局部注意机制之后,最终选择了Swin架构作为模型架构块,构建了一个无CNN的生成器STrans-G。对注意力距离(attention distance)的进一步分析清楚地显示了全局注意和局部注意之间的差异。
2、留意判别器(discriminator)中的残差连接。
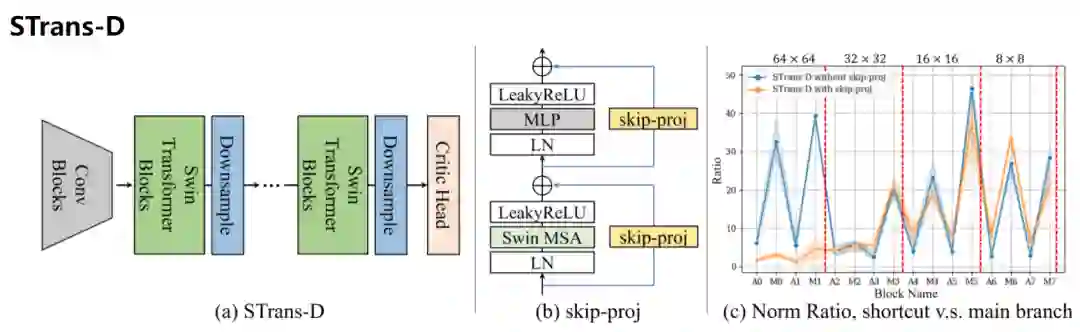
Transformer 在每个自注意力层的子层和点全连接层(pointwise fully connected layer)上使用残差连接。通过对范数比的详细分析,可以发现在基于Transformer 的判别器中,残差连接往往主导信息流。在判别器中执行自注意力和全连接操作的子层在训练过程中被无意中绕过,从而导致图像合成质量低下和收敛缓慢。研究人员通过将每个残差连接替换为跳跃投影层来解决这个问题,这样可以更好地保持残差块中的信息流。
判别器部分称为STrans-D,包括了一些经验上的策略。
首先采用轻量级卷积块将原始输入采样降低4倍,并将图像张量投影到任意维度,而不是像大多数视觉Transformer那样从embedding模块开始。卷积token 抽取器与patch embedding相比,采用了重叠的patch,保留了更多的细节信息。
第二,研究人员在所有注意力模块和MLP中采用均衡学习率(equalized learning rate)。这是由判别器中的Transformer块在使用小学习率来稳定其训练时的缓慢和不满意的收敛所做出的改变。通过在整个判别器中设置一个更大的学习率可以解决这一问题,并引入了一种特殊的sclaer,在运行时将Transformer 块的可学习参数相乘。
此外,研究人员将GeLU替换为LeakyRelu,并在注意和MLP模块的末尾添加非线性激活函数。
3、为Transformer 单独设计策略,而非条件正则化。
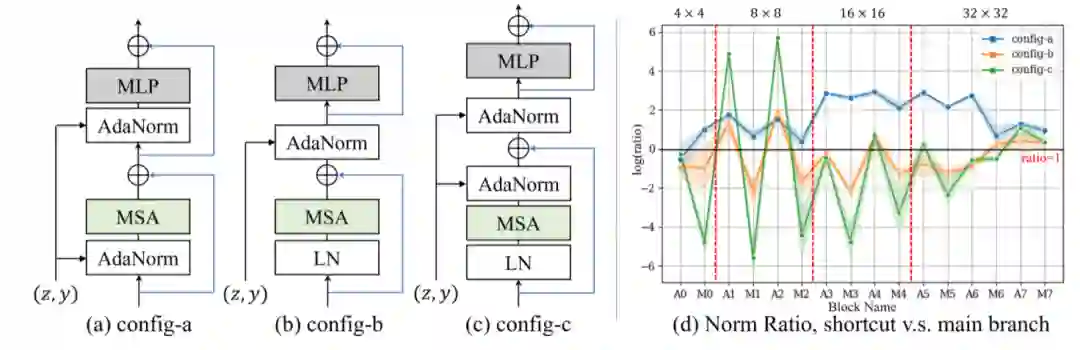
研究人员发现,传统的注入条件信息的方法对基于Transformer的条件GAN没有很好的效果。罪魁祸首是通过Transformer生成器中的残差连接在大信息流中。如果将条件信息注入主分支,那基本上都被忽略掉了,对最终输出几乎没有任何影响。研究人员提出了一种在主干中采用条件归一化层的可行方法,有助于在整个Transformer生成器中保留条件信息。
一个尝试是在Transformer块中直接采用AdaLN,但没有取得效果。特别是研究人员发现FID在前期的训练不再下降了。为了找到故障的发生处,研究人员又绘制了此基线配置的标准比率。存在多个具有高范数比的块,表明主分支中的一些AdaNorm层对中间特征的贡献很小,导致条件信息丢失。
为了保证条件信息的注入,一个简单的解决方案是将AdaNorm应用于trunk。通过这种方式,保证了shortcut 和MLP分支的特性都包含类别的信息。
在实验部分,为了降低计算成本,研究人员将Transformer块中MLP模块的信道扩展率设置为2。输入token维度为512,默认采用四个注意力header。选择Adam优化器(β1=0,β2=0.99)来训练生成器和判别器。Strans-G和Strans-D分别以0.0001和0.002的学习率进行优化。
在无条件的生成中,Strans-G在Celeba 64x64中显著地超出了之前的所有方法。它在FFHQ 256x256的高分辨率设置方面也取得了相当的性能。
对于条件图像生成,在提出的Adain-T层中,Strans-G将CIFAR10上的SOTA起始分数从10.14提高到11.62。由于CIFAR10是一个被广泛采用的数据基准,这一结果也表明了STrans-G在有限数据下模拟真实分布的稳健性。
在成像评估中,可以观察到Strans-G和基于CNN的Biggan模型之间存在相当大的差距。结果表明,与广泛使用的CNN 模型相比,基于Transformer 的GAN 仍然有改进的空间。
此外,这项研究首次显示了Transformer在ImageNet数据集中的潜力。
参考资料:
https://arxiv.org/abs/2110.13107
![]()