在自然语言处理领域,网络微调已经取得了许多进展,现在这一思想延展到了图像到图像转换的领域。
![]()
许多内容制作项目需要将简单的草图转换为逼真的图片,这就涉及图像到图像的转换(image-to-image translation),它使用深度生成模型学习给定输入的自然图片的条件分布。
图像到图像转换的基本概念是利用预训练的神经网络来捕捉自然图片流形(manifold)。
图像转换类似于遍历流形并定位可行的输入语义点。
系统使用许多图片对合成网络进行预训练,以从其潜在空间的任何采样中提供可靠的输出。
通过预训练的合成网络,下游训练将用户输入调整为模型的潜在表征。
多年来,我们已经看到许多特定于任务的方法达到了 SOTA 水平,但目前的解决方案还是难以创建用于实际使用的高保真图片。
在最近的一篇论文中,香港科技大学和微软亚洲研究院的研究者认为,对于图像到图像的转换,预训练才是 All you need。以往方法需要专门的架构设计,并从头开始训练单个转换模型,因而难以高质量地生成复杂场景,尤其是在配对训练数据不充足的情况下。
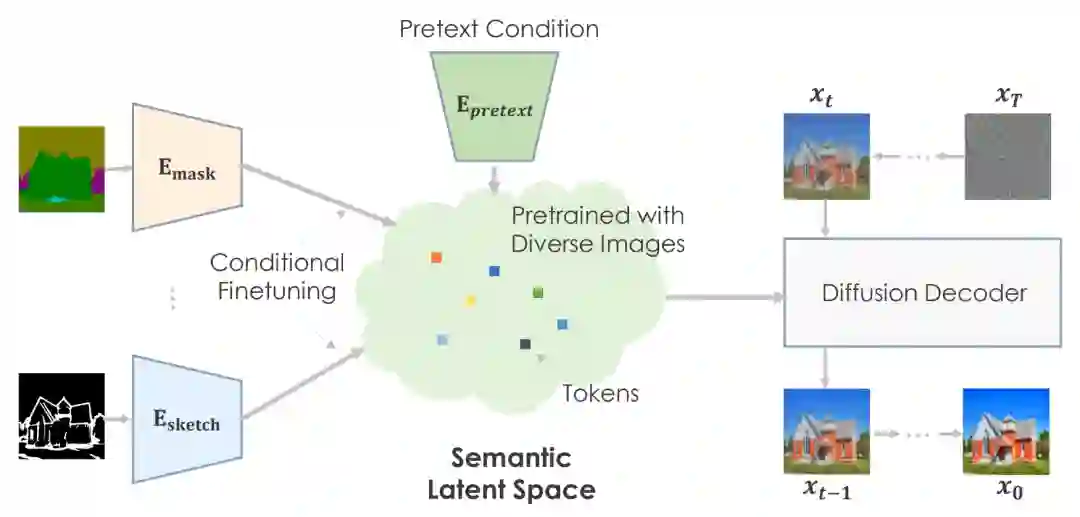
因此,研究者将每个图像到图像的转换问题视为下游任务,并引入了一个简单通用框架,该框架采用预训练的扩散模型来适应各种图像到图像的转换。他们将提出的预训练图像到图像转换模型称为 PITI(pretraining-based image-to-image translation)。此外,研究者还提出用对抗训练来增强扩散模型训练中的纹理合成,并与归一化指导采样结合以提升生成质量。
最后,研究者在 ADE20K、COCO-Stuff 和 DIODE 等具有挑战性的基准上对各种任务进行了广泛的实证比较,表明 PITI 合成的图像显示出了前所未有的真实感和忠实度。
-
论文链接:https://arxiv.org/pdf/2205.12952.pdf
-
项目主页:https://tengfei-wang.github.io/PITI/index.html
作者没有使用在特定领域表现最佳的 GAN,而是使用了扩散模型,合成了广泛多样的图片。其次,它应该从两种类型的潜在代码中生成图片:一种描述视觉语义,另一种针对图像波动进行调整。语义、低维潜在对于下游任务至关重要。否则,就不可能将模态输入转换为复杂的潜在空间。鉴于此,他们使用 GLIDE 作为预训练的生成先验,这是一种可以生成不同图片的数据驱动模型。由于 GLIDE 使用了潜在的文本,它允许语义潜在空间。
扩散和基于分数的方法表现出跨基准的生成质量。在类条件 ImageNet 上,这些模型在视觉质量和采样多样性方面与基于 GAN 的方法相媲美。最近,用大规模文本图像配对训练的扩散模型显示出惊人的能力。训练有素的扩散模型可以为合成提供通用的生成先验。
作者可以使用前置(pretext)任务对大量数据进行预训练,并开发一个非常有意义的潜在空间来预测图片统计。
对于下游任务,他们有条件地微调语义空间以映射特定于任务的环境。该机器根据预先训练的信息创建可信的视觉效果。
作者建议使用语义输入对扩散模型进行预训练。他们使用文本条件、图像训练的 GLIDE 模型。Transformer 网络对文本输入进行编码,并为扩散模型输出 token。按照计划,文本嵌入空间是有意义的。
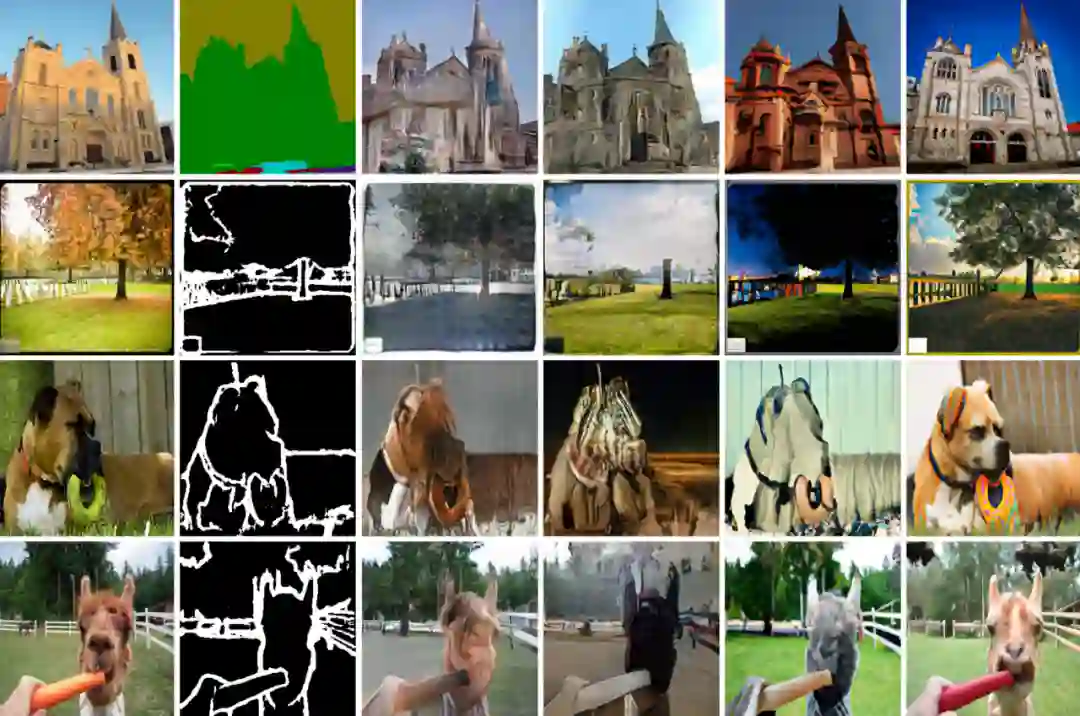
上图是作者的作品。与从头开始的技术相比,预训练模型提高了图片质量和多样性。由于 COCO 数据集具有众多类别和组合,因此基本方法无法通过引人注目的架构提供美观的结果。他们的方法可以为困难的场景创建具有精确语义的丰富细节。图片展示了他们方法的多功能性。
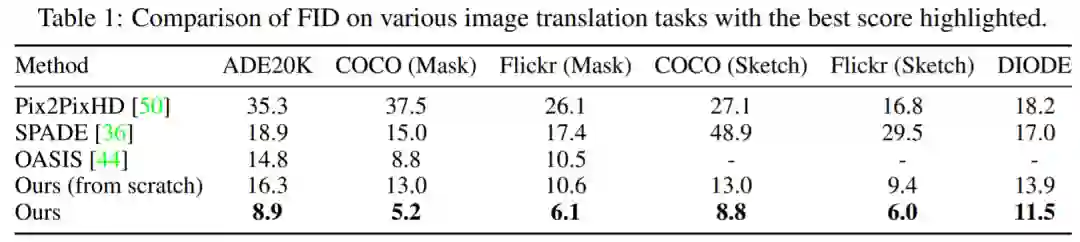
表 1 显示,该研究所提方法性能始终优于其他模型。与较为领先的 OASIS 相比,在掩码到图像合成方面,PITI 在 FID 方面获得了显著的改进。此外,该方法在草图到图像和几何到图像合成任务中也显示出良好的性能。
图 3 展示了该研究在不同任务上的可视化结果。实验可得,与从头开始训练的方法相比,预训练模型显著提高了生成图像的质量和多样性。该研究所用方法可以产生生动的细节和正确的语义,即使是具有挑战性的生成任务。
该研究还在 Amazon Mechanical Turk 上的 COCO-Stuff 上进行了一项关于掩码到图像合成的用户研究,获得了 20 名参与者的 3000 票。参与者一次会得到两张图片,并被要求选择一张更真实的进行投票。如表 2 所示,所建议的方法在很大程度上优于从零开始的模型和其他基线。
条件图像合成可创建符合条件的高质量图片。计算机视觉和图形学领域使用它来创建和操作信息。大规模预训练改进了图片分类、对象识别和语义分割。未知的是大规模预训练是否有利于一般生成任务。
能源使用和碳排放是图片预训练的关键问题。预训练是耗能的,但只需要一次。条件微调让下游任务可以使用相同的预训练模型。预训练允许用更少的训练数据训练生成模型,当数据由于隐私问题或昂贵的注释成本而受到限制时,可以提升图像合成效果。
原文链接:https://medium.com/mlearning-ai/finetuning-is-all-you-need-d1b8747a7a98#7015
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com