对抗样本到底是bug还是特征?Reddit热议的MIT论文再度引发大讨论
新智元报道
【新智元导读】5月初,MIT的一篇论文提出。对抗样本不是bug,而是有用的特征,引发热议。三个月以来,有学者该文中的观点提出了不同意见,对抗样本到底是bug还是特征?有网站专门组织了一场大讨论,原论文作者也参加了,双方有来有回,一起来看看吧。
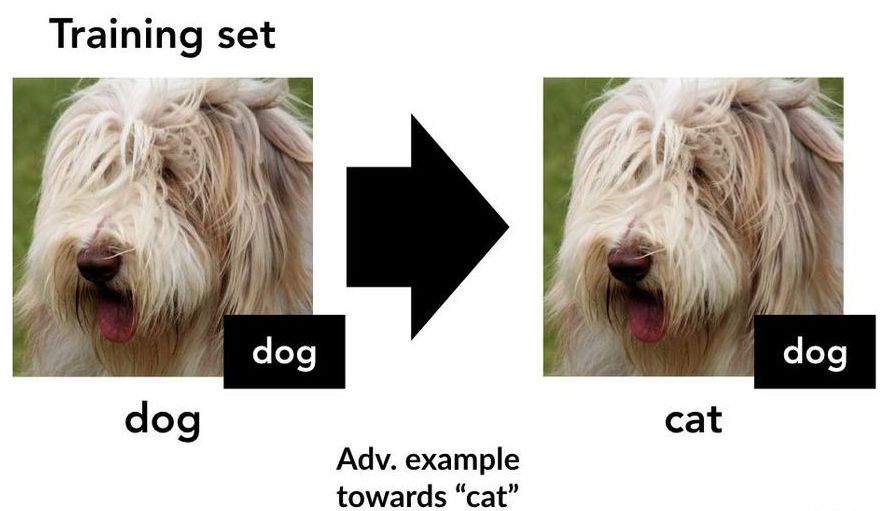
5月6日,MIT的Andrew Ilyas团队发表了一篇论文,题为《对抗样本不是Bug, 而是特征 》。文中概述了两组实验。首先,他们表明,在对抗性实例上训练的模型可以应用到实际数据上,其次,在源自高鲁棒性神经网络表示的数据集上训练的模型,似乎继承了这些数据集非平凡的鲁棒性。
他们对这一结论提出了一个有趣的解释:对抗性实例是由于“非鲁棒特征”,这些特征具有高度可预测性,但对人类来说难以察觉。

新智元曾对这篇论文做过专门报道,详见:
Reddit热议MIT新发现:对抗样本不是bug,而是有意义的数据特征!
这篇论文引起了全世界社交媒体上的热议,各地社群和研究小组中都引发了兴趣浓厚的讨论。该如何解释这些实验?这些实验是可复现的吗?如果确实存在非鲁棒性的特征......那么都有哪些特征?
机器学习社区有时担心同行评议不够彻底。但此次讨论参与的积极性非常高。一些人花了几个星期的时间来复现结果,进行新的实验,并深入思考原来的论文。还有人在实验时随时更新着对非鲁棒特征观点,有时还会进行讨论。此文的原作者也深入地讨论了实验结果,澄清了误解,甚至在回应他人的评论时进行了新实验。
这种深度的参与和讨论非常令人兴奋,希望将来能够尝试更多此类形式的讨论。
讨论内容主要围绕以下几个主题:
对原文内容的澄清:参与讨论和原论文作者之间的讨论中可能表现出一些误解,借此机会能够各自明确自己的观点。
成功的实验再现:有些讨论者成功复现了Ilyas团队的许多实验。这与论文原作者发布代码,模型和数据集是分不开的。Gabriel Goh和Preetum Nakkiran都独立地重新实现并复制了非鲁棒数据集的实验。Preetum还通过已发布的鲁棒数据集上训练了模型,发现模型结构其实非常简单,从而复现了部分鲁棒的数据集实验。而且,Preetum和Gabriel最初都对此持怀疑态度。Preetum表示,他尝试的许多模型变体和超参数都是高鲁棒性的。
探索非鲁棒性“转移”的边界条件:其中一些讨论重点放在了“非鲁棒数据集”实验的变体上,这些实验将训练的对抗样本非鲁棒性转移到了实际数据上。这种转移是何时发生的,为何会发生?Gabriel Goh探索了出另一种机制,Preetum Nakkiran则展示了一种不会发生这种转移的特殊结构。Eric Wallace表明,对于其他类型的错误标记数据,很可能会发生这种转移。
鲁棒和非鲁棒特征的属性:Gabriel Goh探讨了线性模型中出现非鲁棒特征的可能性,Dan Hendrycks和Justin Gilmer讨论了实验结果与更广泛的鲁棒性的分布和转移问题相关联的问题。Reiichiro Nakano探讨了鲁棒模型的定性差异等。
论文原作者积极参与了这次讨论,并针对讨论中提出的多种观点和问题给出了回复。以下节选几例:
对抗样本研究人员应该扩展“鲁棒”的含义
Justin和Dan讨论了“非鲁棒特征”模型不具备鲁棒性的特殊情况,因为这些特征依赖于肤浅的相关性,这种观点经常出现在分布鲁棒性文献中。他们还讨论了神经网络在频率空间中的最新行为分析。他们强调,我们应该对鲁棒性的概念进行更广泛的扩展。
原作者回复:
仅从数据中高频出现的要素进行学习的模型,是一个有趣的发现,这一发现为我们提供了另一种视角,我们的模型可以从对人类“毫无意义”的数据中进行学习。我们完全同意这一观点,即研究更广泛的鲁棒性概念,在机器学习研究中将变得越来越重要,并有助于我们更好地掌握希望模型依赖的那些特征。
存在非鲁棒、但有用的样本
Gabriel探讨了线性模型中非鲁棒但有用的特征。他提供了两种结构:一种是“受污染”的特征,由于混合了无用的特征,是非鲁棒的,而“集合”特征可能是真正有用的非鲁棒特征。
原作者回复:
这些线性模型实验,是实现真实数据集非鲁棒特征可视化的第一步(即对它们的存在性的一种巧妙的证实)。此外,“受污染”的非鲁棒特征的理论架构,为开发更精细的特征定义提供了一个有趣的方向。
对抗样本就是Bug
Preetum构建了一系列对抗样本,这些样本没有转移到真实数据中,这表明一些对抗样本是原始论文框架中的一些“错误”。Preetum还证明,即使底层分布没有“非鲁棒特征”,也会出现对抗样本。
原作者回复:
应该细致考察对抗样本。基于构造的“bug”的对抗样本不会转移的事实,是“可转移性”和“非鲁棒特征”之间的存在联系的另一个证据。
从错误标记的数据中学习
Eric表示,对模型的训练错误进行训练,或者如何预测示例形成不相关的数据集,可以转移到真实的测试集。这些实验类似于原始论文的非鲁棒转移结果。- 所有三个结果都是“从不正确标记的数据中学习”的例子。
原作者回复:
这些实验创造性地证明了这样一个事实,即“人类毫无意义”数据的学习特征的潜在现象实际上可以在广泛的环境中出现。





