作者|机器之心编辑部
来源|机器之心
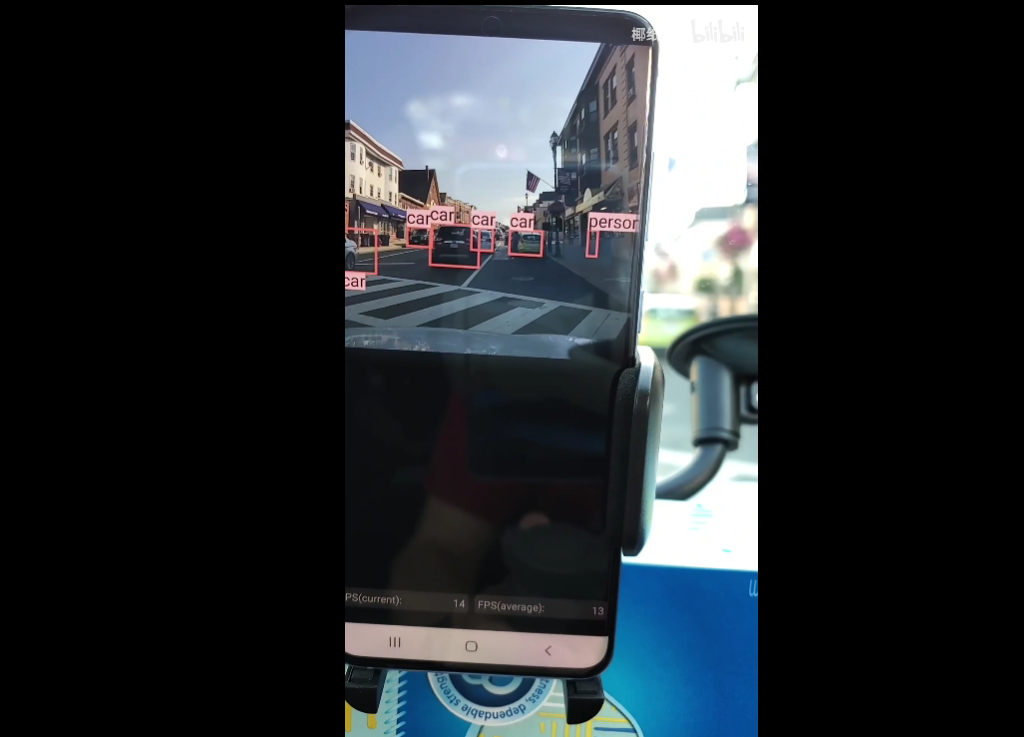
本文提出了一套模型压缩和编译结合的目标检测加速框架,根据编译器的硬件特性而设计的剪枝策略能够在维持高 mAP 的同时大大提高运行速度,压缩了 14 倍的 YOLOv4 能够在手机上达到 19FPS 的运行速度并且依旧维持 49mAP(COCO dataset)的高准确率。相比 YOLOv3 完整版,该框架快出 7 倍,并且没有牺牲准确率。该框架由美国东北大学王言治研究组和威廉玛丽学院任彬研究组共同提出。
随着近年来 CNN 在目标检测领域的发展和创新,目标检测有了更加广泛的应用。考虑到在实际场景中的落地需求,目标检测网络往往需要在保持高准确率的同时拥有较低的计算延迟。而现有的目标检测网络,在资源有限的平台上,尤其是手机和嵌入式设备上部署这类应用时,很难同时实现高准确率与实时检测。
在过去的几年中,有很多优秀的目标检测网络被相继提出。其中的 two-stage 检测网络包括 RCNN 系列和 SPPNet 等,还有 one-stage 检测网络如 YOLO 系列,SSD 和 Retina-Net 等。相较于 two-stage 网络,one-stage 网络在牺牲一定准确率的情况下换来了更快的执行速度。即便如此,这些网络依然需要较大的计算量来达到可接受的准确率,这成为了这些网络难以在移动设备上实现实时推理的主要阻碍。为此,一些轻量级 (lightweight) 目标检测网络模型被提出,如 SSD-Lite, YOLO-Lite, YOLO-tiny 等,以实现移动设备上的快速目标检测。但是这些轻量级网络的解决方案效果依然不理想。
为了更好地满足目标检测框架的落地需求,CoCoPIE 团队:美国东北大学王言治研究组和威廉玛丽学院任彬研究组共同提出了名为 YOLObile 的手机端目标检测加速框架。YOLObile 框架通过「压缩 - 编译」协同设计在手机端实现了高准确率实时目标检测。该框架使用一种新提出的名为「block-punched」的权重剪枝方案,对模型进行有效的压缩。在编译器优化技术的协助下,在手机端实现高准确率的实时目标检测。该研究还提出了一种高效的手机 GPU - 手机 CPU 协同计算优化方案,进一步提高了计算资源的利用率和执行速度。
相比 YOLOv4 的原版,加速后的 YOLObile 的运行速度提高了 4 倍,并且维持了 49mAP 的准确率。相比 YOLOv3 完整版,该框架快 7 倍,在手机上实现了 19FPS 的实时高准确率目标检测。同时准确率高于 YOLOv3,并没有用牺牲准确率来提高计算速度。
![]()
YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
https://arxiv.org/abs/2009.05697
https://github.com/nightsnack/YOLObile
https://www.bilibili.com/video/BV1bz4y1y7CR
![]()
![]()
在原版的 YOLOv4 中,有一些操作符不能够最大化地利用硬件设备的执行效率,比如带有指数运算的激活函数可能会造成运行的延迟增加,成为降低延时提高效率的瓶颈。该研究把这些操作符相应地替换成对硬件更加友好的版本,还有一些操作符是 ONNX 还未支持的(YOLObile 用 ONNX 作为模型的存储方式),研究者把它替换成 ONNX 支持的运算符。
比如,在 YOLOv4 引入的新模块 Spatial Attention Module (SAM)中,用了 sigmoid 作为分支的激活函数,该研究在尝试把它换成 hard-sigmoid 后发现:准确率和直接删除相比几乎一致,增加的模块又会增加计算量,所以研究者将其删除了。
Mish 激活函数也涉及了指数运算,同时在 pytorch 上的支持不太友好,会在训练时占用很多缓存,同时它在 pytorch 上也不能够像 C++ 版本的 YOLOv4 一样带来很大的准确率提升,而且 ONNX 尚未支持。研究者将其换成了 YOLOv3 的 leaky RELU。
![]()
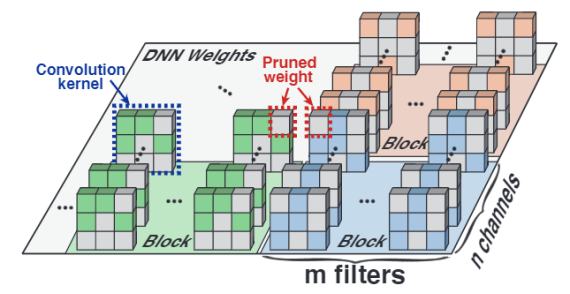
在 YOLObile 优化框架中,作者使用了新提出的名为「block-punched」的权重剪枝 (weight pruning) 方案。这种剪枝方案旨在在获得较高剪枝结构自由度的同时,还能使剪枝后的模型结构较好地利用硬件并行计算。这样就从两方面分别保证了剪枝后模型的准确率和较高的运算速度。
在这种剪枝方案中,每层的权重矩阵将被划分为大小相等的多个块(block),因此,每个块中将包含来自 m 个 filter 的 n 个 channel 的权重。在每个块中,被剪枝的位置需要做出如下限定:需要修剪所有 filter 相同位置的一个或多个权重,同时也修剪所有通道相同位置的一个或多个权重。
从另一个角度来看,这种剪枝方案将权重的剪枝位置贯穿了整个块中所有的卷积核(kernel)。对于不同的 block,剪枝的位置和剪掉的 weight 数量都是灵活可变的。另外这种剪枝策略可以应用在卷积核大小 3x3,1x1,5x5 等的卷积层上,也适用于 FC 层。
通过划分为固定大小的块来进行剪枝,能够提高编译器的并行度,进而提高在手机上运行的速率。
1. 在准确率方面,通过划分多个小区块,这种剪枝方法实现了更加细粒度的剪枝。相较于传统的结构化剪枝(剪除整个 filter 或 channel),这种方式具有更高的剪枝结构自由度,从而更好地保持了模型的准确率。
2. 在硬件表现方面,因为在同一小区块中,所有 filter 修剪被修剪的位置相同,所以在并行计算时,所有 filter 将统一跳过读取相同的输入数据,从而减轻处理这些 filter 的线程之间的内存压力。而限制修剪小区块内各 channel 的相同位置,
确保了所有 channel 共享相同的计算模式,从而消除处理每个 channel 的线程之间的计算差异。因此,这种剪枝方案可以大幅度降低在计算过程中处理稀疏结构的额外开销,从而达到更好的加速效果。
作者采用了 Reweighted Regularization 算法来筛选出剪枝掉的 weight 的位置,reweight 算法依据 weight 的绝对值大小筛选出相对重要的位置。整个剪枝的过程从依据预先训练好的网络模型开始,然后将 Reweighted 算法融合在训练的过程中,在训练每 3 到 4 个 epochs 后就能够得到一组可选的剪枝位置,通过重复训练来调整剪枝位置,最终得到精确的剪枝模型结果。
为了支持「block-punched」剪枝方案,编译器也需要作出相应的调整和优化。为了更好地存储和调用经过「block-punched」剪枝后的 weight index,研究者引入了新的存储方案,将 index 的存储空间进一步压缩。同时,通过对所有的块进行重新排序,编译器能够在更少的内存访问次数下运行,进而获得更快的运算速度。
YOLObile 中还使用了手机 GPU 和手机 CPU 协同计算的方式来进一步降低整个网络的运算时间。现在主流的移动端 DNN 推理加速框架,如 TensorFlow-Lite,MNN 和 TVM 都只能支持手机 CPU 或 GPU 单独运算,因此会导致潜在的计算资源浪费。
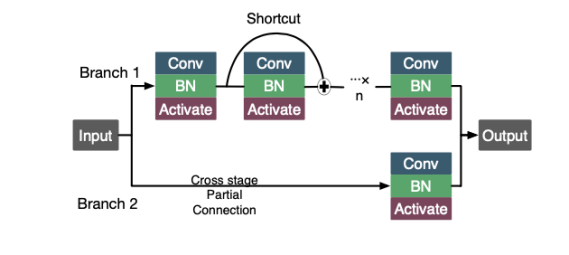
YOLObile 提出针对网络中的分支结构,比如 YOLOv4 中大量使用的 Cross Stage Partial (CSP)结构,使用 CPU 来辅助 GPU 同时进行一些相互无依赖关系的分支运算,从而更好地利用计算资源,减少网络的运算时间。YOLObile 框架将待优化的网络分支分为有卷积运算分支和无卷积运算分支,并对这两种情况分别给出了优化方案。
如下图所示,CSP 是一个跨越很多残差 block 的长分支,在手机的执行过程中,单一的 GPU 计算往往是顺序地执行完上面堆叠残差 block 的分支后再执行下面的 CSP 分支,然后拼接在一起作为下一层的输入。研究者将卷积层数更少的 branch2 挪到 CPU 上去,CPU 执行时间少于上面 branch1 在 GPU 上的总运算时间,这个并行操作能够有效减少运算延迟。
当然,决定能否将 branch2 转移到 CPU 的因素在于 branch1 的卷积层数多少,通常 CSP block 会跨越 8 个残差 block,也有的时候出现只跨越 4 个残差 block 的情况,还有在前几层只跨一个残差 block 的情况。
对于只跨 1 个残差 block 的情况明显还是 GPU 顺序执行更高效,对于跨越多个的就需要用实际测出的延迟来做判断。
值得注意的是,转移数据到不同处理设备的时候,需要加入数据传输拷贝的时间。
![]()
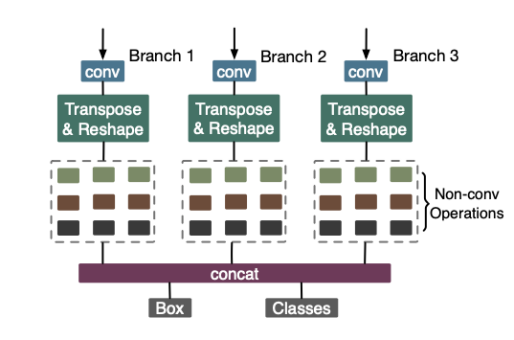
在 YOLOv4 最后输出的位置,3 个 YOLO head 输出部分有很多诸如转置,变形之类的非卷积运算,这些非卷积运算在 CPU 和 GPU 上的运行效率相当,作者同样基于运行时间,考虑将部分运算符转移到 CPU 上去做,选择最高效的执行方式。
![]()
![]()
实验结果
整个训练过程采用 4 块 RTX2080Ti,训练时间为 5 天。使用配备高通骁龙 855 CPU 和 Adreno 650 GPU 的三星 Galaxy S20 作为测试平台。训练的数据集是 MS COCO,和 YOLOv4 原版保持一致。
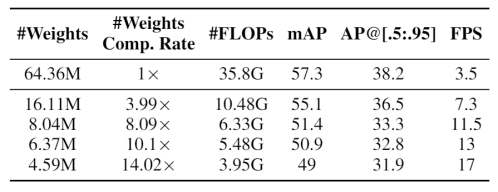
实验结果表明,当使用 YOLOv4 为基础模型进行优化时,该研究的优化框架可以成功将原模型大小压缩至 1/14,在未使用 GPU-CPU 协同计算优化时,将每秒检测帧数(FPS)提升至 17,且达到 49(mAP)的准确率。
![]()
![]()
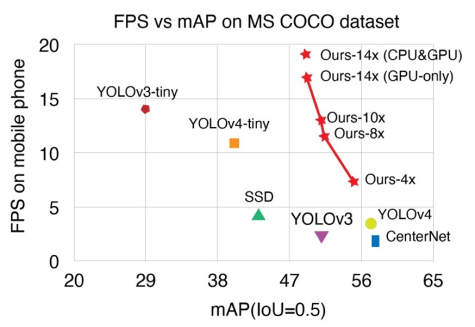
从下图中可以看到,与众多具有代表性的目标检测网络相比,该研究的优化模型在准确率与速度两方面同时具有优异的表现,而不再是简单的牺牲大幅准确率来获取一定程度的速度提升。
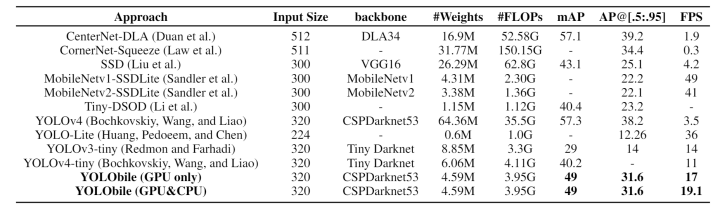
下表展示了 YOLObile 与其他具有代表性的目标检测网络在准确率与速度方面的具体比较。值得注意的是,作者的 GPU-CPU 协同计算优化方案可以进一步将执行速度提高至 19FPS。
![]()
相比于其他 one-stage 目标检测模型和 light-weight 模型,经过剪枝后的 YOLObile 更快且更精确,在准确率和速度上实现了帕累托最优。
消融实验
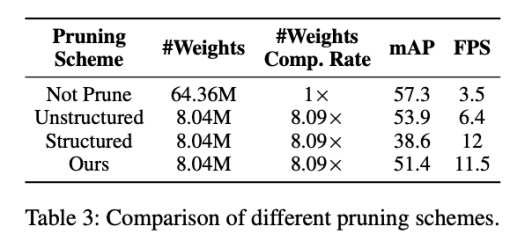
表格中列出了在相同压缩倍率的情况下,Structured Pruning, Unstructured Pruning, 和文中提出的 Block-Punched Pruning 这三种剪枝策略的准确率和运行效率的比较。
可以看到,Unstructured Pruning 在压缩 8 倍的状态下能够维持较高的准确率,但是和前文描述的一样,它的运行效率较低,即使在压缩 8 倍的情况下,运行时间只提高了不到 2 倍。Structured Pruning 后模型能够高效率地在硬件设备上执行,但是准确率相比 Unstructured Pruning 有大幅度的下降。而根据编译器设计的 Block-Punched 剪枝策略,能够维持较高的准确率,并且达到和 Structured Pruning 相当的执行效率。
![]()
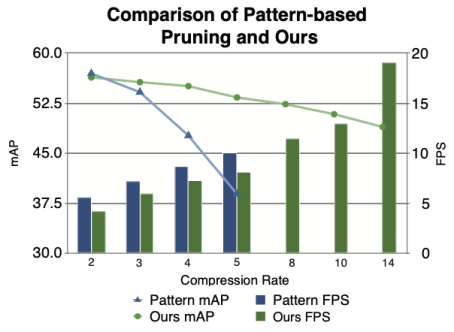
和 Pattern-Based Pruning 的比较
Pattern-Based Pruning 只能用在 3x3 的层,为了达到较高的压缩倍率,就需要对 3x3 的卷积层压缩掉更多的 weight。
下图是一个关于不同倍率下 pattern-based pruning 和 block-punched pruning 的比较,可以看出 pattern-based pruning 在较低倍率压缩的情况下,能够拥有较高的准确率和执行效率,但是受限制于只适用于 3x3 卷积层,即使将所有的 3x3 层全部压缩也只能达到 5 倍多的压缩率,但是准确率就非常低了。block-based pruning 由于可以将所有的层都进行压缩,在高倍率的情况下依然能够维持较高的准确率。
![]()
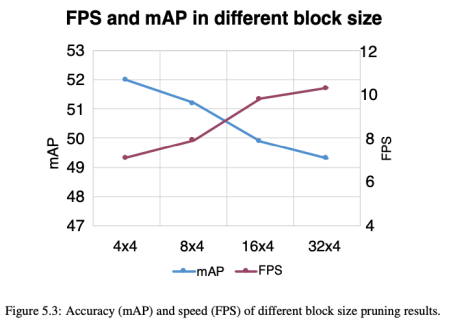
该研究对四种不同的块大小进行实验,为了实现较高的硬件并行度,每个模块中的 channel 数固定为 4,这与 GPU 和 CPU 矢量寄存器的长度相同。在每个块中使用不同数量的 filter 来评估准确性和速度。
如图 5.3 所示,与较小的块相比,较大的块可以更好地利用硬件并行性,并可以实现更高的推理速度。但是其粗略的修剪粒度导致准确性下降。较小的块可以获得较高的精度,但会牺牲推理速度。根据结果,研究者将 8×4(8 个连续 filter 的 4 个连续 channel)视为移动设备上的所需块大小,这在精度和速度之间取得了良好的平衡。
![]()
![]()
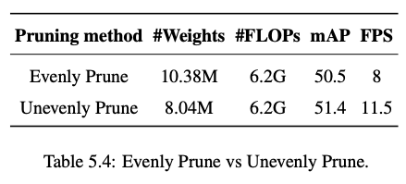
YOLOv4 在卷积层中仅包含 3×3 和 1×1 的 kernel。该研究提出这两种类型的卷积层在修剪过程中具有不同的敏感度并进行了两组实验。在相同数量的 FLOPs 下,将一组中的所有层平均修剪,另一组中,3×3 卷积层的压缩率比 1×1 卷积层高 1.15 倍。如上表所示,均匀修剪的模型和不均匀修剪的模型相比,准确性和速度都较低。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()