当深度学习遇上量化交易——因子挖掘篇

©PaperWeekly 原创 · 作者|桑运鑫
学校|上海交通大学硕士生
研究方向|图神经网络在金融领域的应用
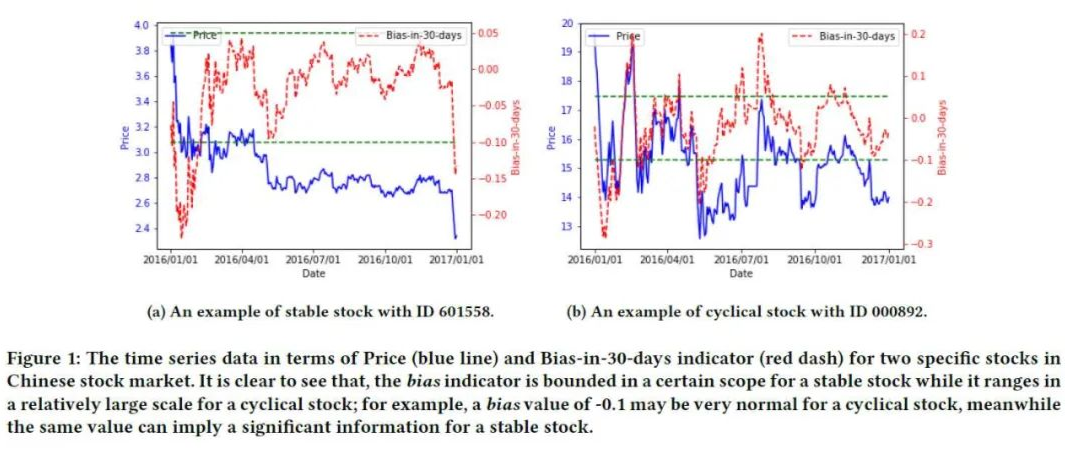
但与常规的回归预测任务不同的是,股价预测问题有其独特性,存在时间序列、噪声高、过拟合等问题。当前对于深度学习在股票交易中的研究主要侧重在因子挖掘、图神经网络与知识图谱、新闻与社交媒体等非结构化数据的利用、以及时序模型改进四个方面。
我们会在文章中依次探讨近 5 年顶会上对这四个方向的研究。此外,因为相关的资料确实相当匮乏,我在 GitHub 上新建了一个 repo:deep-stock, 用于收集、整理相关的研究论文、书籍、数据、网站等,欢迎 star!
deep-stock:
https://github.com/sangyx/deep-stock
本文主要介绍 MSRA 在 KDD 2019 上发表的两篇文章,这两篇文章主要关注深度学习在因子挖掘方面的应用。


论文标题:Individualized Indicator for All: Stock-wise Technical Indicator Optimization with Stock Embedding
论文链接:https://dl.acm.org/doi/10.1145/3292500.3330833
而要解决上述问题,需要解决下面两个问题:
怎么把股票分成不同种类,或者说怎么发现因子的内禀属性?
怎么找出不同的技术因子对不同种类股票的影响程度?即如何计算那个加权系数?
对于第一个问题,要解决它其实要给每只股票生成一个 embedding,并且这个 embedding 要包含足够的信息。基于“万物皆可 embedding” 的思想,可以很自然的想到 word2vec 中的 skip-gram 和 cbow 两个生成 embedding 的方法。
文章在这里采用了 skip-gram 的方法,但 skip-gram 方法建立在一个词和它周围的词组成的词组更合理的基础上,我们如何得到由有相似属性的股票组成的序列呢?
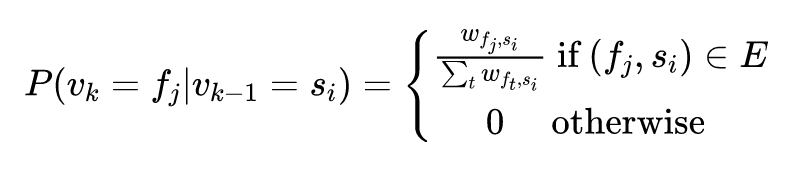
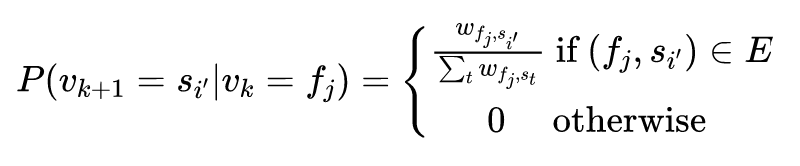
3. 使用 Skip-Gram 算法对上面采样得到的股票序列进行训练可以得到股票 的 embedding 。
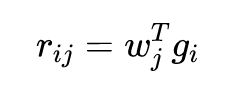
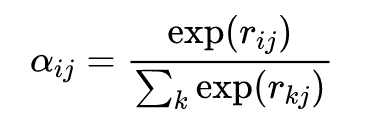
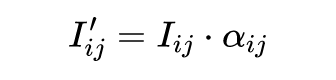
之后使用信息系数(Information Correlation,IC)作为目标函数对这个单层神经网络进行优化。
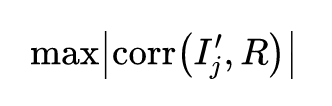
因为投资的动态性,所以文章引入了 Rotation Learning 的方法随时间不断更新因子,如下图所示。

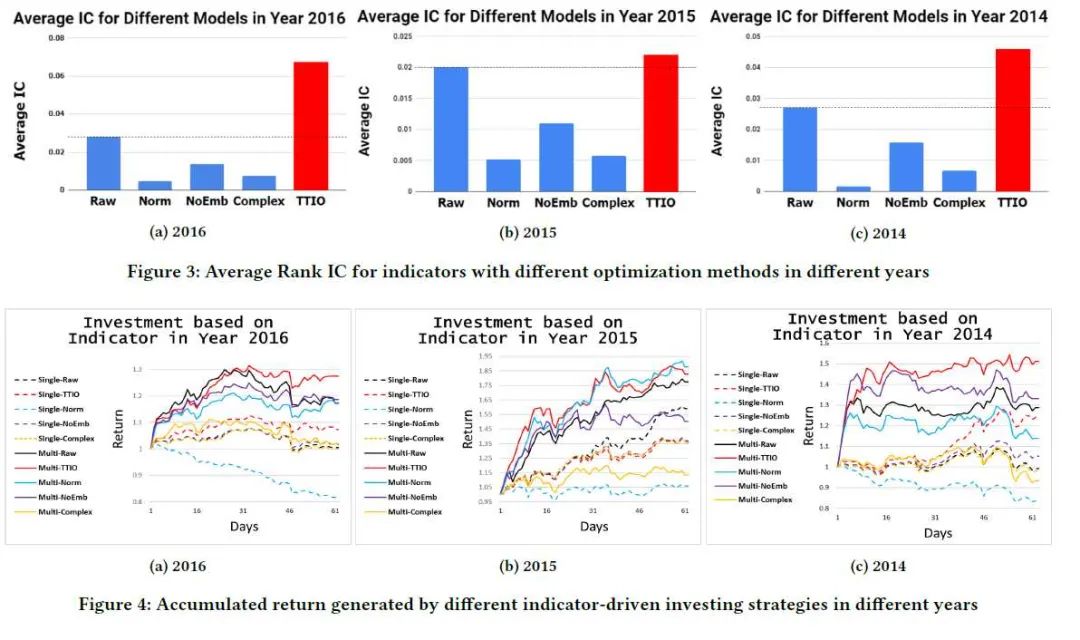
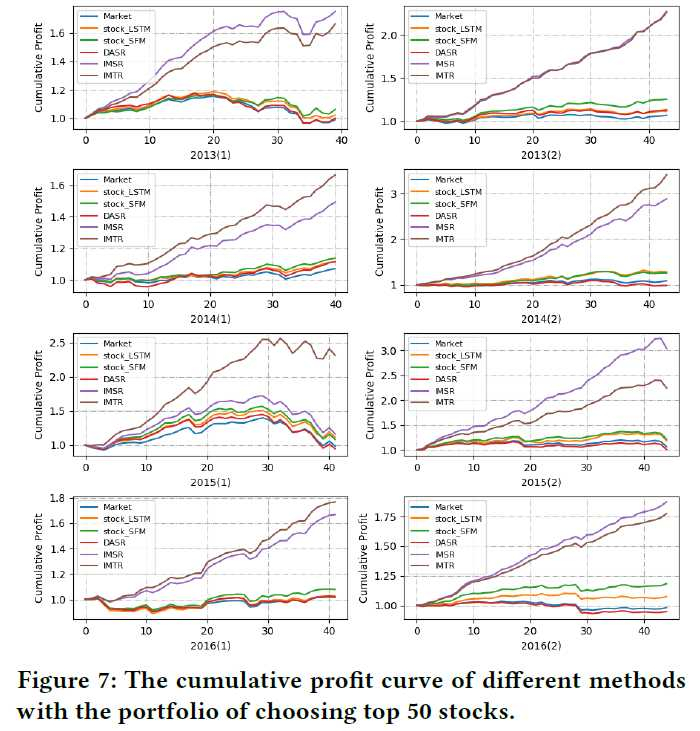
最后,文章对上述方法使用从 2013 年到 2016 年 2000 只股票的交易数据对如下表所示的七种因子进行了实验。
对照方法包括 Raw(原始因子),Norm re-scales(对原始因子进行归一化),NoEmb(将 stock embedding 作为训练参数直接进行训练)、Complex(将原始因子和股票 embedding 直接进行连接,输入一个两层的神经网络进行训练,为了测试过拟合问题)。

实验结果自然是吊打 baseline,如下图所示。但也有两个其他结论值得注意,Norm 方法相比 Raw 方法并不好,甚至要更差,这显示了除了相对大小,因子的绝对大小也很重要。而 Complex 虽然只使用了最简单的的两层神经网络,但过拟合问题也让它表现十分糟糕。


论文标题:Investment Behaviors Can Tell What Inside: Exploring Stock Intrinsic Properties for Stock Trend Prediction
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2019/11/p2376-chen.pdf
-
如何挖掘股票的内禀属性? -
如何将股票静态的内禀属性融入到深度神经网络中来加强动态的股票预测?
对于第一个问题,我们当然是使用 skip-gram。不好意思,串文了,skip-gram 是上一篇论文采取的方法,这篇文章提出了另一种解决方案,那就是万物皆可 Embedding 的另一个邪教——矩阵分解(Matrix Factorization)。
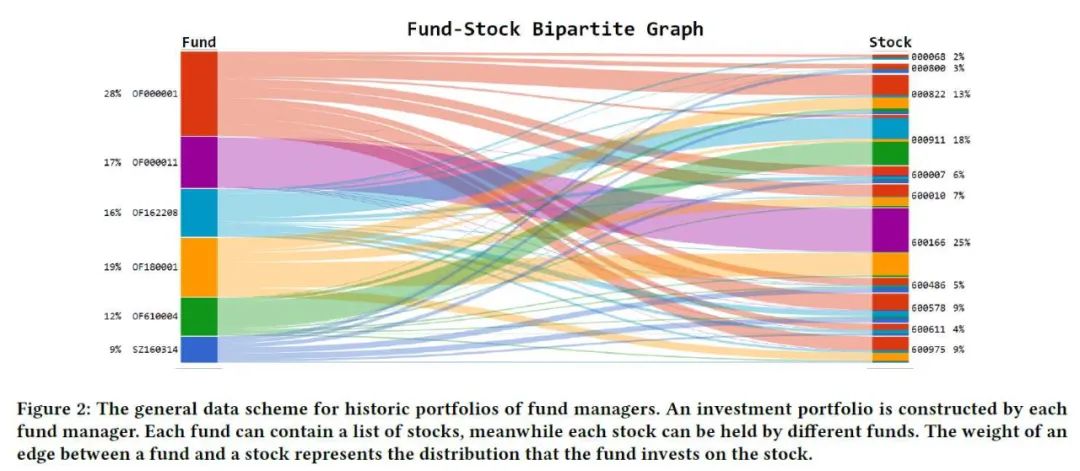
那去哪找矩阵呢?文章提出了一个有意思的假设:那些专业的基金经理比起我们这些小白来姿势水平肯定不知道高到哪里去了,他们在给自己管理的基金挑选股票组合时肯定倾向于选择有相似属性的股票(嗯,这里没串,两篇文章其实用的是同一个假设)。
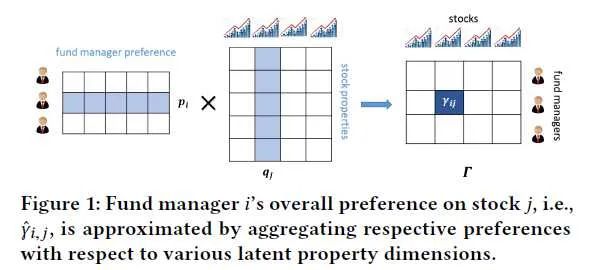

虽然与上一篇文章生成股票 embedding 基于的假设相同。但是这篇文章指出了这个假设存在的问题:
除了基金经理偏好的股票属性,基金中的投资组合同样依赖于股票的动态趋势和风险分布。没有基金经理会投资一个在持续下跌的股票,即使它具有让他心动的优良属性。同样的,为了保证基金收益更加健壮,很多投资组合都会做风险平均。
但文章指出,这一问题可以通过使用足够长时间的投资组合的数据来解决,因为在长期内累积的投资行为会削弱上面两个因素的影响,让股票的内禀属性更好的暴露出来。
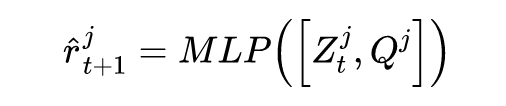
但经验告诉我们,市场是动态的,它在不同的时间段对不同的股票内禀属性的偏好是不同的。所以文章提出了两种不同的方法来分别捕捉动态市场状态(dynamic market state)和和动态市场趋势(dynamic market trend)。
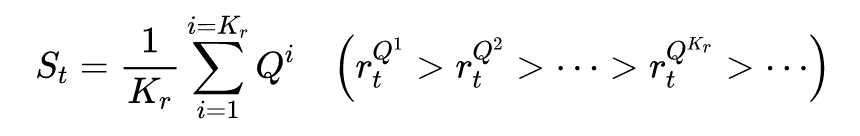
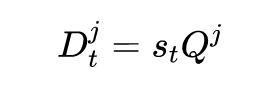
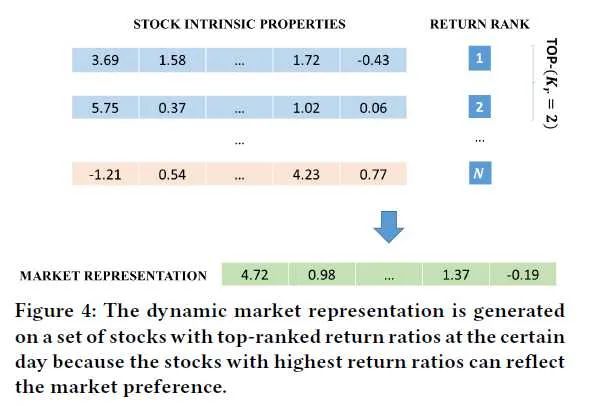

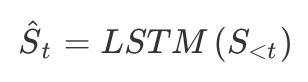
训练的损失函数包括两部分,包括回归损失和排序损失。加入排序损失是因为每个股票都是独立的。其中:
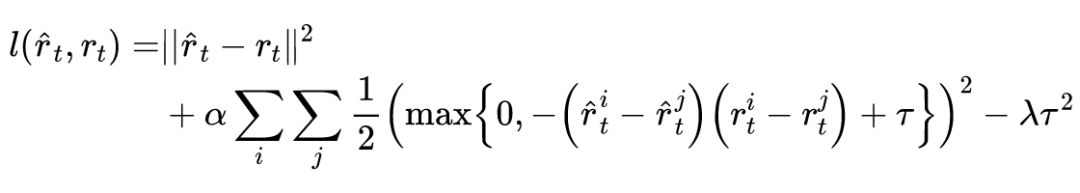

总结
如果您对深度学习在量化交易中的应用感兴趣,欢迎加我微信一起学习探讨。


点击以下标题查看更多往期内容:

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。