凭借其直观而严谨的机器学习方法,这篇文章为学生提供了进行研究和构建数据驱动产品所需的基础知识和实用工具。作者优先考虑几何直觉和算法思维,并包括所有基本的数学先决条件的细节,以提供一个新鲜和可访问的方式学习。课程强调实际应用,并举例说明计算机视觉、自然语言处理、经济学、神经科学、推荐系统、物理学和生物学等学科。本书包含超过300幅彩色插图,经过精心设计,能够直观地掌握技术概念,超过100个深度编码练习(使用Python)提供了对关键机器学习算法的真正理解。在线提供了一套在线资源,包括示例代码、数据集、交互式讲座幻灯片和解决方案手册,使其成为机器学习研究生课程和个人参考和自学的理想文本。
- 鼓励几何直觉和算法思维,以提供对关键概念的直观理解和互动的学习方式
- Python编码练习,帮助将知识付诸实践
- 强调实际应用,结合真实世界的例子,使学生有信心进行研究,构建产品,解决问题
- 完全独立的,有包含基本数学先决条件的附录
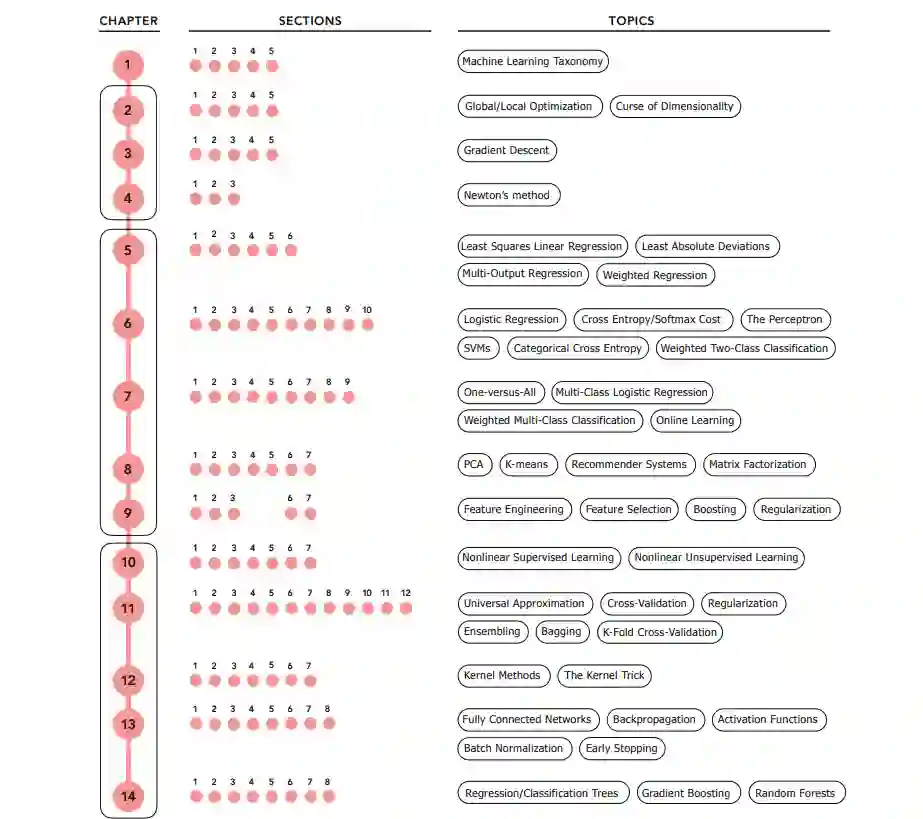
目录内容:
- Introduction to machine learning Part I. Mathematical Optimization:
- Zero order optimization techniques
- First order methods
- Second order optimization techniques Part II. Linear Learning:
- Linear regression
- Linear two-class classification
- Linear multi-class classification
- Linear unsupervised learning
- Feature engineering and selection Part III. Nonlinear Learning:
- Principles of nonlinear feature engineering
- Principles of feature learning
- Kernel methods
- Fully-connected neural networks
- Tree-based learners Part IV. Appendices: Appendix A. Advanced first and second order optimization methods Appendix B. Derivatives and automatic differentiation Appendix C. Linear algebra.
第一部分: 数学优化(第2-4章)
数学优化是机器学习的主力,它不仅支持单个机器学习模型的调整(在第二部分中介绍),还支持我们通过交叉验证来确定合适模型本身的框架(在本文的第三部分中讨论)。在本文的第一部分,我们将全面介绍数学优化,从第2章详细介绍的基本零阶(无导数)方法,到第3章和第4章分别介绍的基本和高级一阶和二阶方法。更具体地说,这一部分的文本包含完整的描述,局部优化,随机搜索方法,梯度下降,和牛顿的方法。 第二部分:线性学习(5-9章)
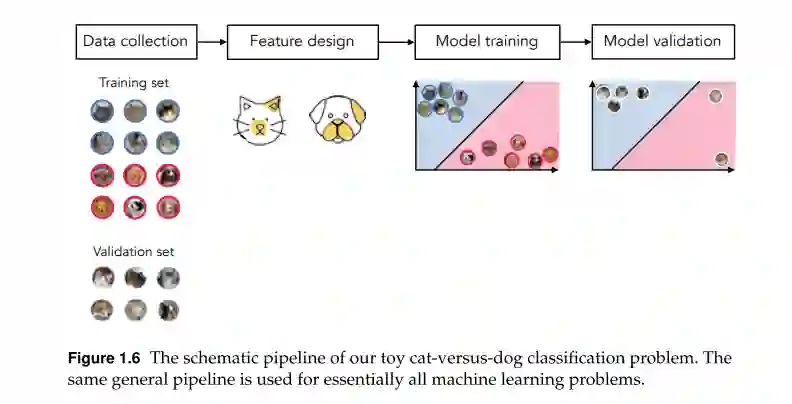
在这部分的文本中,我们描述了损失函数的机器学习的基本组成部分,重点是线性模型。这包括在第5-7章中对监督学习的完整描述,包括线性回归,两类和多类分类。在这些章节中,我们描述了一系列的观点和流行的设计选择,当建设监督学习者。在第8章中,我们同样描述了无监督学习,第9章包含了基本特征工程实践的介绍,包括流行的直方图特征,以及各种输入规范化方案和特征选择范例。 **第三部分: 非线性学习(10-14章) **
在本文的最后一部分,我们将第二部分中介绍的基本范式扩展到一般非线性设置。我们仔细地从第10章对非线性有监督和无监督学习的基本介绍开始,在这一章中,我们介绍了非线性学习的动机、常见术语和在其余的文本中使用的符号。在第十一章,我们讨论了如何自动选择适当的非线性模型,首先介绍了普遍近似。这自然会导致对交叉验证的详细描述,以及增强、正规化、集成和k -fold交叉验证。有了这些基本思想,在第12-14章中,我们专门用一章的篇幅介绍机器学习中使用的三种常用的通用近似器:固定形状的核、神经网络和树,在这里我们讨论每种常用的通用近似器的优点、缺点、技术偏差和用法。为了更好地学习本书的这部分内容,我们强烈建议先学习并理解第11章及其基本思想,然后再继续学习第12-14章。