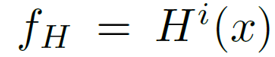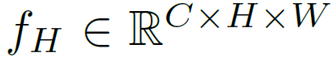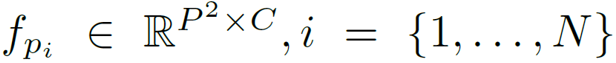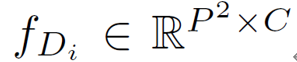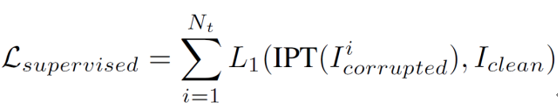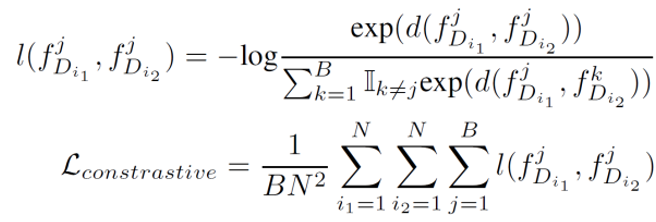作为自然语言处理领域的主流模型,Transformer 近期频频出现在计算机视觉领域的研究中。
例如 OpenAI 的 iGPT、Facebook 提出的 DETR 等,这些跨界模型多应用于图像识别、目标检测等高层视觉任务。
而华为、北大、悉大以及鹏城实验室近期提出了一种新型预训练 Transformer 模型——IPT(Image Processing Transformer),用于完成超分辨率、去噪、去雨等底层视觉任务。
该研究认为输入和输出维度相同的底层视觉任务更适合 Transformer 处理。
预训练模型能否在视觉任务上复刻在自然语言任务中的成功?
华为诺亚方舟实验室联合北京大学、悉尼大学、鹏城实验室提出底层视觉 Transformer,使用 ImageNet 预训练,在多项视觉任务上达到 SOTA。
与自然语言任务相比,视觉任务在输入形式上有很大差别。Transformer 等模型在自然语言处理任务上展现出了强大的特征学习能力,使用大量数据进行预训练的策略获得了成功。因此,很多研究都在考虑如何在计算机视觉领域发挥 Transformer 模型与预训练的潜力。
近日,华为、北大、悉大以及鹏城实验室的研究者提出了一个名为 IPT(Image Processing Transformer)的预训练 Transformer 模型,用于完成超分辨率、去噪、去雨等底层视觉任务。IPT 具备多个头结构与尾结构用于处理不同的任务,不同的任务共享同一个 Transformer 模块。预训练得到的模型经过微调即可在多个视觉任务上大幅超越对应任务上的当前最好模型。
![]()
论文链接:https://arxiv.org/pdf/2012.00364.pdf
卷积神经网络(CNN)是计算机视觉领域中的常用模型,自然语言处理领域中出类拔萃的 Transformer 模型在应用到计算机视觉任务中时,真的能比 CNN 更好吗?
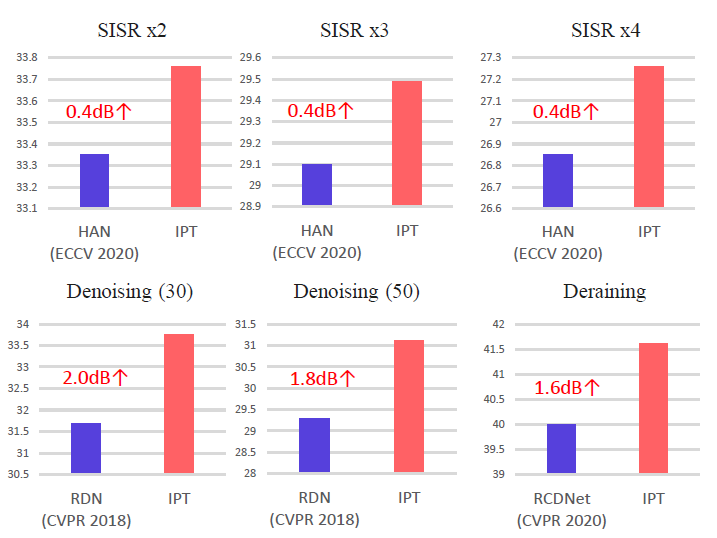
首先,研究者展示了经过预训练的 IPT 模型在不同任务上微调后达到的性能。如图 1 所示,在多项底层视觉任务中,IPT 模型均取得了巨大的性能提升。例如,对于不同倍率的超分辨率任务,IPT 普遍能够提升 0.4dB,而对于去噪和去雨任务则提升更多,提升了 1.6-2.0dB。
![]()
图 1:IPT 模型与当前各项任务最好结果的对比情况。
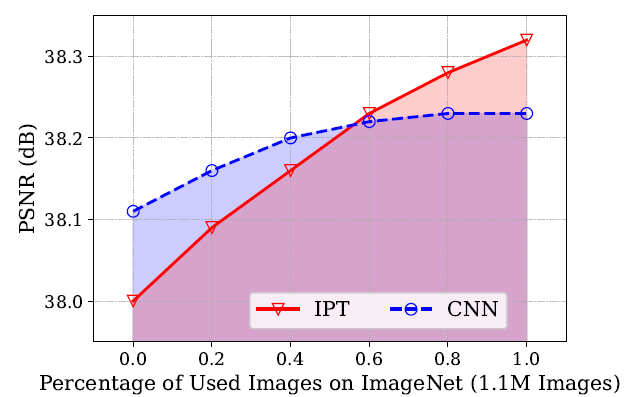
为了更好地说明为什么要用 Transformer,研究者还设计了一个基于 CNN 的预训练模型作为对照,并在 DIV2K 数据集 2 倍超分辨率的任务上探索了不同预训练数据量对模型性能的影响。图 2 展示了不同的数据量对 CNN 和 Transformer 模型的影响。结果显示,在预训练数据有限时,CNN 模型能获得更好的性能。随着数据量的增大,基于 Transformer 模块的 IPT 模型获得了显著的性能提升,曲线趋势也展现了 IPT 模型令人期待的潜力。
![]()
图 2:预训练数据量对 CNN 与 IPT 模型的影响。
可以看出,Transformer 模型能够更充分地发挥大规模训练数据的优势。自然语言处理领域的成功经验在底层视觉任务上得到了验证。
在自然语言任务中,Transformer 的输入是单词序列,图像数据无法作为输入。解决如何使用 Transformer 处理图像的问题是将 Transformer 应用在视觉任务的第一步。
不同于高层视觉语义任务的目标是进行特征抽取,底层视觉任务的输入和输出均为图像。除超分辨率任务之外,大多数底层视觉任务的输入和输出维度相同。相比于高层视觉任务,输入和输出维度匹配这一特性使底层视觉任务更适合由 Transformer 处理。
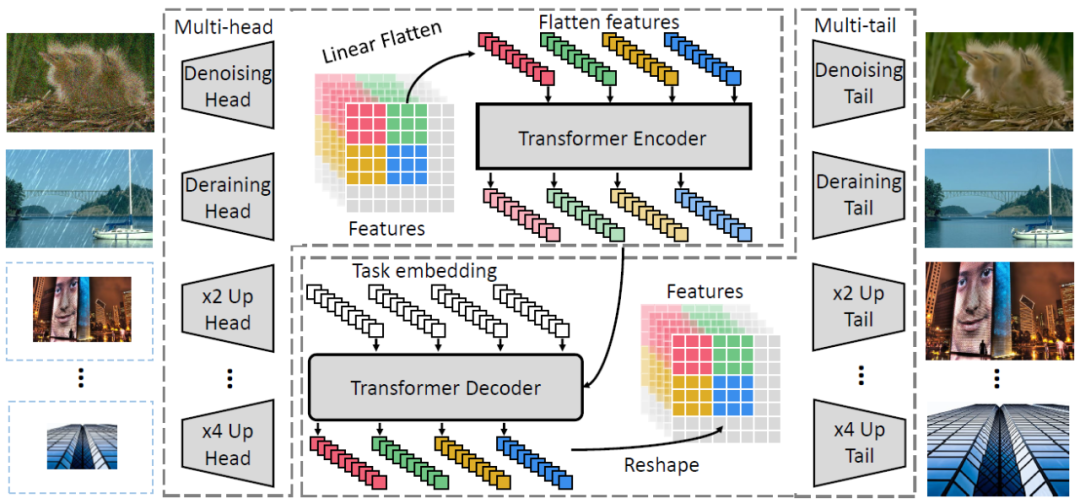
具体而言,研究者在特征图处理阶段引入 Transformer 模块,而图像维度匹配则交给了头结构与尾结构,如图 3 所示:
![]()
![]()
![]()
接下来,再对特征图进行切块与拉平操作。首先按照 P×P 的大小将特征图切割成 N 块,每一个特征块再被拉平为维度为 P^2×C 的向量,得到
![]()
这样一来,每个特征向量可以等同于一个「单词」,即可送入 Transformer 进行处理,得到维度相同的输出特征:
![]()
这些输出特征再经过整形和拼接操作,还原为与输入相同维度的特征图。如此处理得到的特征图会被送入一个尾结构,被解码为目标图像。
有了头结构和尾结构负责维度变换,Transformer 模块可以专心地做特征处理。这使得多任务的扩展变得简单:对于不同的任务,只需要增加新的头结构与尾结构即可,多种任务之间的 Transformer 模块是共享的。
为了适应多任务,研究者在 Transformer 的解码模块中加入了一个可学习的任务编码。
Transformer 的成功离不开大量数据预训练带来的性能提升。在这篇论文中,针对底层视觉任务,
研究者提出一种使用 ImageNet 数据集对模型进行预训练的方法。结果显示,经过预训练的模型只需要做一些简单微调即可适用于多种下游任务。
研究者使用 ImageNet 数据集生成多种退化图像,构成多种底层视觉任务训练集。具体来说,对 ImageNet 数据集中的自然图像进行下采样即可得到用于超分辨率任务的训练数据;加入噪声可生成用于去噪任务的训练数据;加入雨痕可产生用于去雨任务的训练集等。
利用这些人工合成的数据,配以对应任务的多头多尾结构,多个任务的训练数据同时进行训练,整个模型可以通过监督损失函数进行训练:
![]()
除此之外,为了提升模型在未曾预训练过的任务上的性能(如不同倍率的超分辨率、不同噪声强度的去噪任务),研究者根据特征块之间的相关性引入了对比学习方法作为自监督损失函数。具体来说,来自于同一图像的特征块之间的特征应当相互接近,来自于不同图像的特征块应当远离。这一自监督损失函数如下所示:
![]()
研究者表示,通过引入这一对比损失函数,模型能够在未经预训练的任务上展现超越传统方法的性能。
经过预训练的 IPT 模型,只需要在特定任务的数据集上进行微调,即可在此任务上达到很好的效果。在微调阶段,只有特定任务所对应的头尾结构以及 Transformer 模块被激活训练,与此任务无关的头尾模块被暂时冻结。
为了证明 IPT 的有效性,研究者在多种底层视觉任务上测试了模型效果,包括 2 倍、3 倍和 4 倍的超分辨率任务、两种强度的去噪任务以及去雨任务。每个具体任务所采用的 IPT 模型均为同一个预训练模型在特定任务上微调得到的。另外,研究者还做了一系列对照实验来确定 Transformer、对比学习损失函数等不同模块的重要性。所有实验都是在英伟达 Tesla V100 GPU 和 PyTorch 上完成的。
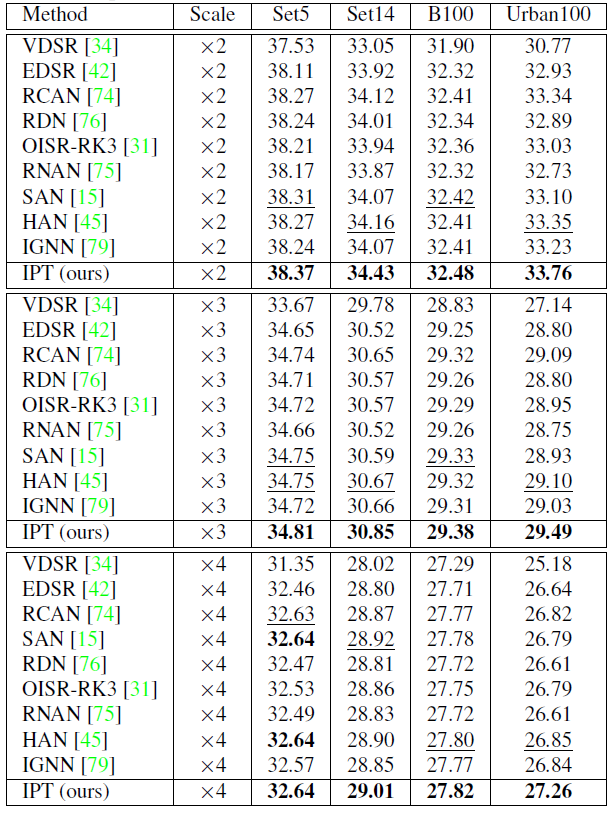
首先对于超分辨率任务,其预训练样本是将图像进行 bicubic 下采样得到的。研究者报告了在 Set5、Set14、B100 以及 Urban100 四个数据集上的结果,如表 1 所示。
![]()
可以看出,IPT 模型在所有设定下均取得了最好的结果。尤其是在 Urban100 数据集上,对比当前最好的超分辨率算法,IPT 模型展现出了大幅度的优势。
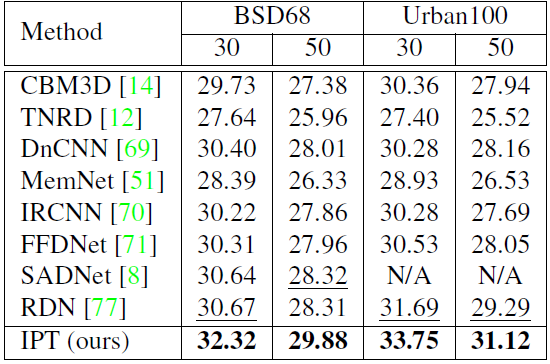
如表 2 和表 3 所示,在去噪和去雨任务上,IPT 模型也展现出了类似的性能。
![]()
![]()
下图展示了不同方法在去噪、去雨任务中的处理结果,从中可以看出 IPT 模型的输出结果更接近真值图像:
![]()
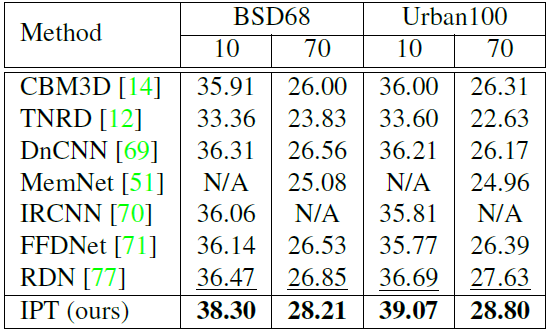
随后研究者进一步测试了预训练模型的泛化性能。具体做法是,将 IPT 模型在没有预训练过的任务上进行微调后测试。在表 4 中,对于噪声强度为 10 和 70 的设定下(预训练为 20 和 50),IPT 模型依旧展现出巨大的优势,展示了预训练模型良好的泛化性。
![]()
除此之外, 为了探究对比损失函数对模型学习表示能力的影响,研究者在 2 倍超分辨率任务上测试了对比损失函数占不同比例时模型的性能。表 5 展示了模型在 Set4 数据集上不同的对比损失函数权重得到的 PSNR。结果显示,相比不加入此损失(λ=0)的情况,对比损失函数能够进一步提升模型学习表示的能力。
![]()
从实验效果中可以看出,Transformer 模型在底层视觉任务上展现出了超过 CNN 的实力,说明 Transformer 在视觉任务中是可行的。不仅如此,它所表现出的因大量训练数据而带来的性能提升,展现出更大数据量、更大的模型在视觉领域的巨大潜力。这一方向值得更多的研究者做更多深入探索。
12月6日,机器之心将举办2020 NeurIPS MeetUp。此次MeetUp精选数十篇论文,覆盖深度学习、强化学习、计算机视觉、NLP等多个热门主题,设置4场Keynote、13篇论文分享和28个Poster。
时间:12月6日9:00-18:00
地址:北京燕莎中心凯宾斯基饭店(亮马桥)
点击阅读原文,立即报名。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com